把钱扔进大模型API接口的时候,我总有一种在给旧时代地主交租的错觉。你喂给它最独家的行业认知,它吐出几行看似聪明的代码,最后利润全进了硅谷中心化巨头的腰包,你连一粒渣都没分到。
这就是为什么我最近翻烂了 @OpenLedger 的白皮书。圈内现在只要粘上AI两个字,恨不得把PPT写成科幻小说,但我今天不想聊那些宏大的叙事,只想站在一个老韭菜和老码农的视角,聊聊 $OPEN 背后那个真正戳到痛点、却被绝大多数人忽视的底层解法。
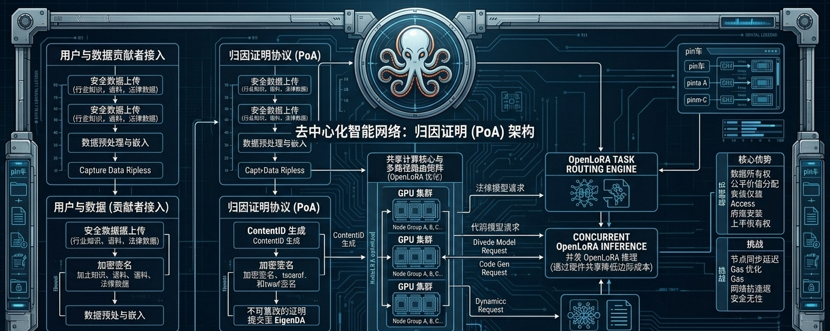
大家都知道它主打 Proof of Attribution(归因证明)和 Datanets,想把数据所有权和收益还给大众。听起来很美,但作为一个写了多年智能合约的人,我最关心的是:当成千上万的微型模型和精细数据在链上频繁交互时,那高昂的计算成本和验证延迟,会不会直接把这个系统压垮?
白皮书里其实藏了一个极少被大众提及的冷门技术:**基于OpenLoRA的共享算力多重路由矩阵**。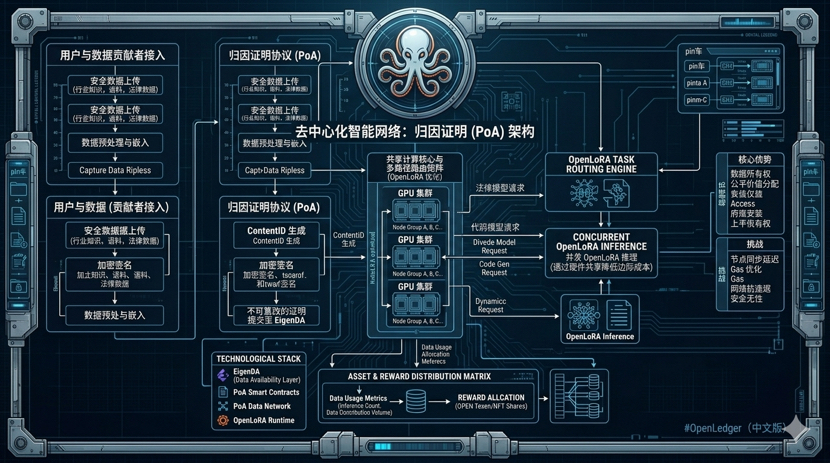
名字很绕,说白了就是一种“拼车”机制。传统逻辑下,你想运行一个特定垂直领域的AI模型,就必须给它单独分配一整块昂贵的GPU算力,这就像你为了去隔壁街买个菜,特意包了一辆豪华大巴,成本高到离谱。而这个路由矩阵,允许成百上千个经过微调的OpenLoRA轻量化模型,在同一块共享GPU基础设施上并发运行。
它用极其务实的数学逻辑,把AI推理的边际成本压到了地板上。你贡献的独家行业语料、他微调的法律模型,都可以在同一个算力池里精细化路由,互不干扰,却能共享底层的硬件开销。这才是去中心化AI能够运转的经济学底线。
不过,老骨头看项目,向来是带点刺的。
白皮书里吹得天花乱坠的底层架构,说挂载了顶级的EigenDA来解决数据可用性,能让链上存储费用趋近于零。然而回归到实际体验,我们在进行数据NFT确权或者部署轻量化模型时,依然能感受到节点同步的滞后,偶尔还会蹦出一些让人摸不着头脑的隐形Gas消耗。技术堆砌得再高大上,如果无法让普通用户实现无感丝滑的交互,那它跟市面上那些传统的EVM链又有多少本质区别?
很多人炒作这个赛道,炒的是“机器代替人类”的焦虑。但我盯着 $OPEN 的逻辑看久了,反而看出了一种冷酷的宿命感。
AI正在把整个物质世界数字化,而它正在尝试把这种数字化的智力活动彻底金融化。每一次微小的推理,每一次数据的微调,都变成了一条条可被追踪、可被定价的资产。它不仅仅是在构建一个技术网络,更是在为未来的硅基生命制定第一部劳动法。
当人类的智慧最终退化成供给AI训练的燃料,或许只有这种冰冷的链上归因,才能证明我们曾经在这个充满噪音的数字宇宙里,真正地存在过。