Tôi từng tham gia vài cuộc vote trong crypto với một cảm giác rất kỳ lạ.
Proposal dài. Có thuật ngữ kỹ thuật. Có biểu đồ. Có đoạn giải thích vì sao quyết định này tốt cho cộng đồng. Tôi đọc được một nửa rồi tự hỏi: mình có thật sự hiểu đủ để bấm vote không?
Điều khó chịu là tôi biết rất nhiều người khác cũng có thể đang giống tôi. Nhưng cuối cùng hệ thống vẫn biến tất cả thành một con số rất gọn: đồng ý hoặc phản đối.
Nhìn từ xa, đó là dân chủ. Nhìn gần hơn, đôi khi nó chỉ là sự tự tin tập thể được đóng gói thành governance.
Khi đọc về OpenLedger tôi lại nghĩ về chuyện governance.
OpenLedger đang xây một nền kinh tế cho specialized AI models: Datanets gom dữ liệu chuyên biệt, ModelFactory giúp fine-tune, OpenLoRA giúp phục vụ model hiệu quả hơn, Proof of Attribution ghi nhận đóng góp, còn governance tham gia vào việc quyết định model nào nên được phát triển tiếp.
Ý tưởng này hợp lý.
Nhưng cũng chính ở đây có một vấn đề.
Nếu một model trading hoặc accounting được đưa ra để cộng đồng quyết định có nên tiến triển không, câu hỏi đầu tiên không phải là “cộng đồng có thích nó không?”
Câu hỏi đầu tiên phải là: cộng đồng có đủ năng lực để đánh giá nó không?
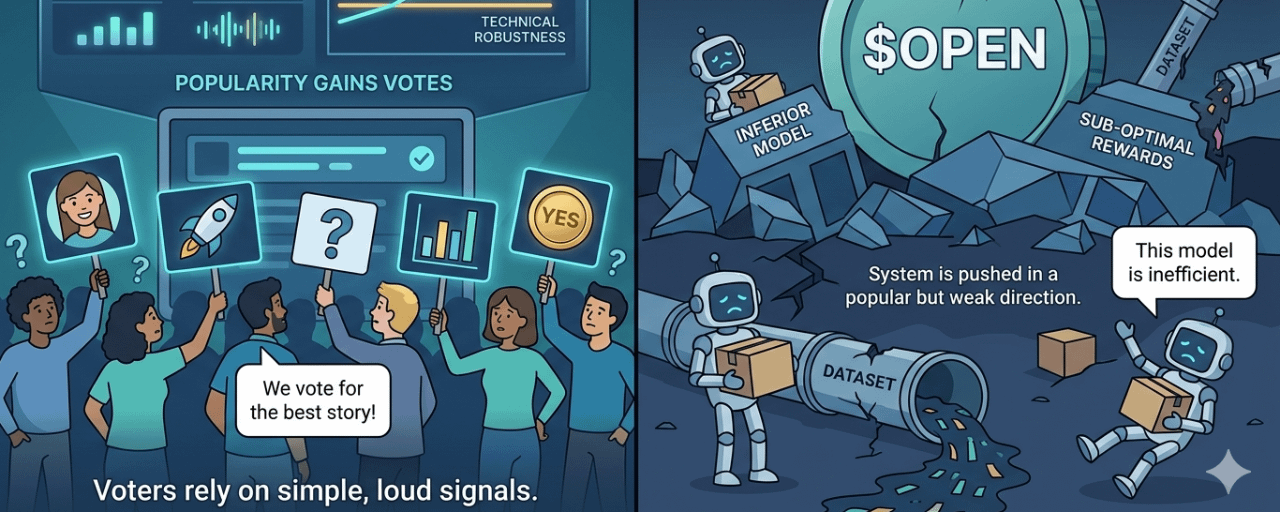
Tôi gọi vấn đề này là Governance Popularity Bias.
Thiên kiến phổ biến trong quản trị.
Nó xảy ra khi một quyết định cần chuyên môn sâu lại bị kéo về những tín hiệu dễ nhìn hơn: ai kể câu chuyện hay hơn, cộng đồng nào đông hơn, narrative nào đang nóng hơn, model nào có dashboard đẹp hơn.
Một model có thể được ủng hộ không phải vì nó tốt hơn, mà vì nó dễ hiểu hơn. Một Datanet có thể thắng không phải vì dữ liệu sạch hơn, mà vì cộng đồng đằng sau nó ồn ào hơn.
Crypto đã gặp chuyện này nhiều lần. DAO vote không phải lúc nào cũng chọn phương án đúng. Nhiều khi nó chọn phương án có meme mạnh hơn. Open-source cũng vậy. Một repo nhiều star chưa chắc an toàn nhất. Một paper được nhắc nhiều chưa chắc chắc nhất.
Với OpenLedger, rủi ro này nặng hơn, vì model không chỉ là một bài post để đọc xong rồi quên. Model có thể được dùng cho inference. Có thể nhận reward. Có thể trở thành một phần trong workflow của agent. Có thể kéo theo data contributor, validator, staker, người dùng và dòng $OPEN phía sau.
Nếu governance chọn sai, chi phí không chỉ là một quyết định xấu.
Nó là cả hệ sinh thái bị kéo về một hướng có vẻ hợp lòng đám đông nhưng yếu về chuyên môn.
Vì vậy, tôi nghĩ OpenLedger cần một lớp bổ sung: Expertise-Weighted Governance.
Quản trị có trọng số chuyên môn.
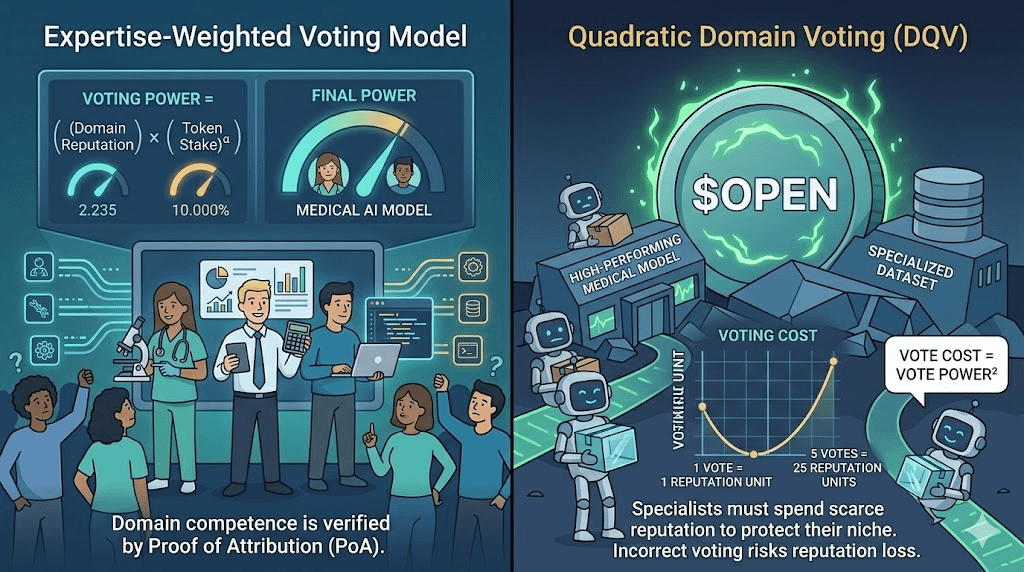
Nhưng trọng số này không nên được hiểu chung chung kiểu “hãy lắng nghe chuyên gia nhiều hơn”. Như vậy vẫn quá mềm. Nó nên được thiết kế thành một cơ chế cụ thể hơn: Domain-Specific Attenuated Voting, tức quyền vote bị suy giảm hoặc khuếch đại theo mức đóng góp thật trong đúng miền tri thức đó.
Một ví nắm nhiều $OPEN không nên mặc nhiên có tiếng nói lớn trong mọi model. Nếu ai đó sở hữu 1 triệu token nhưng chưa từng có một byte dữ liệu nào được Proof of Attribution ghi nhận trong Datanet y tế, trọng số vote của họ cho một medical model nên bị suy giảm mạnh. Ngược lại, một bác sĩ chỉ có ít token, nhưng từng đóng góp dữ liệu giúp model giảm lỗi trong các ca khó, nên có tiếng nói lớn hơn trong đúng miền đó.
Công thức có thể rất đơn giản:
Voting Power(domain) = OPEN Stake × Reputation(domain)^α
Trong đó, OPEN Stake là lượng token tham gia vote, Reputation(domain) là điểm uy tín tích lũy từ đóng góp đã được PoA ghi nhận trong đúng Datanet hoặc domain liên quan, còn α là hệ số khuếch đại chuyên môn. Nếu α càng cao, hệ thống càng ưu tiên người thật sự có lịch sử đóng góp trong miền đó.
Nói đơn giản: quyền biểu quyết không chỉ đến từ việc bạn sở hữu bao nhiêu, mà từ việc bạn đã chứng minh mình hiểu bao nhiêu trong đúng lĩnh vực đang được vote.
Nhưng chỉ vậy vẫn chưa đủ.
Nếu chuyên gia có trọng số cao, họ cũng không nên được vote bừa mà không trả giá. Vì vậy OpenLedger có thể dùng thêm Domain Quadratic Voting, hay DQV.
Thay vì bỏ phiếu theo kiểu 1 điểm uy tín đổi 1 lực vote, việc dồn nhiều lực vote vào một model phải có chi phí tăng theo bình phương. Một chuyên gia muốn dùng toàn bộ uy tín để bảo vệ một model thiểu số nhưng xuất sắc, họ có thể làm. Nhưng họ phải trả giá bằng reputation tích lũy từ các lần đóng góp Datanet trước đó.
Điều này ép cả chuyên gia lẫn cộng đồng phải nghiêm túc hơn.
Bạn chỉ dồn lực cho thứ bạn thật sự hiểu. Vì nếu vote sai, vote theo phe, hoặc vote vì narrative, cái mất không chỉ là một lá phiếu. Cái mất là uy tín chuyên môn đã tích lũy qua thời gian.
Tất nhiên, giải pháp này không sạch sẽ.
Ai xác định reputation có đáng tin không? Chuyên gia có thể trở thành tầng lớp gatekeeper mới không? Người mới nhưng có góc nhìn tốt có bị đè bởi người cũ không? Một hệ governance quá đại chúng dễ bị đám đông kéo đi. Nhưng một hệ governance quá chuyên gia cũng có thể biến thành hội kín.
Đó là điểm khó.
Nhưng tôi vẫn nghĩ OpenLedger phải đối diện với nó sớm.
Bởi specialized AI không giống vote chọn màu giao diện. Nó chạm vào dữ liệu, model, inference, reward và đôi khi cả quyết định tự động của agent. Nếu một model sai được cộng đồng đẩy lên chỉ vì nó phổ biến, thì sự minh bạch on-chain cũng không cứu được chất lượng. Nó chỉ giúp ta nhìn rất rõ quá trình một quyết định sai được hợp thức hóa.
Tôi không muốn một AI blockchain nơi mọi thứ đều “community-backed” nhưng không ai dám hỏi cộng đồng đó có thật sự hiểu thứ mình đang ủng hộ không.
Câu hỏi cuối cùng khá thẳng.
Nếu OpenLedger phải chọn giữa một model được đám đông yêu thích và một model được số ít chuyên gia chứng minh là tốt hơn, họ sẽ gọi lựa chọn nào là phi tập trung thật sự?
Và còn khó hơn nữa: bạn muốn AI tương lai được quản trị bởi nhiều người nhất, hay bởi những người hiểu rõ nhất cái họ đang bỏ phiếu?