When people hear “AI model training,” most instantly imagine pain.
Not the exciting kind.
The annoying kind.
Terminal windows everywhere. Dependency errors you pretend to understand. GPU memory crashes. Config files that look like someone lost an argument with reality. A developer on GitHub saying “just run this” like that sentence has ever made anyone feel calm.
That’s usually the vibe.
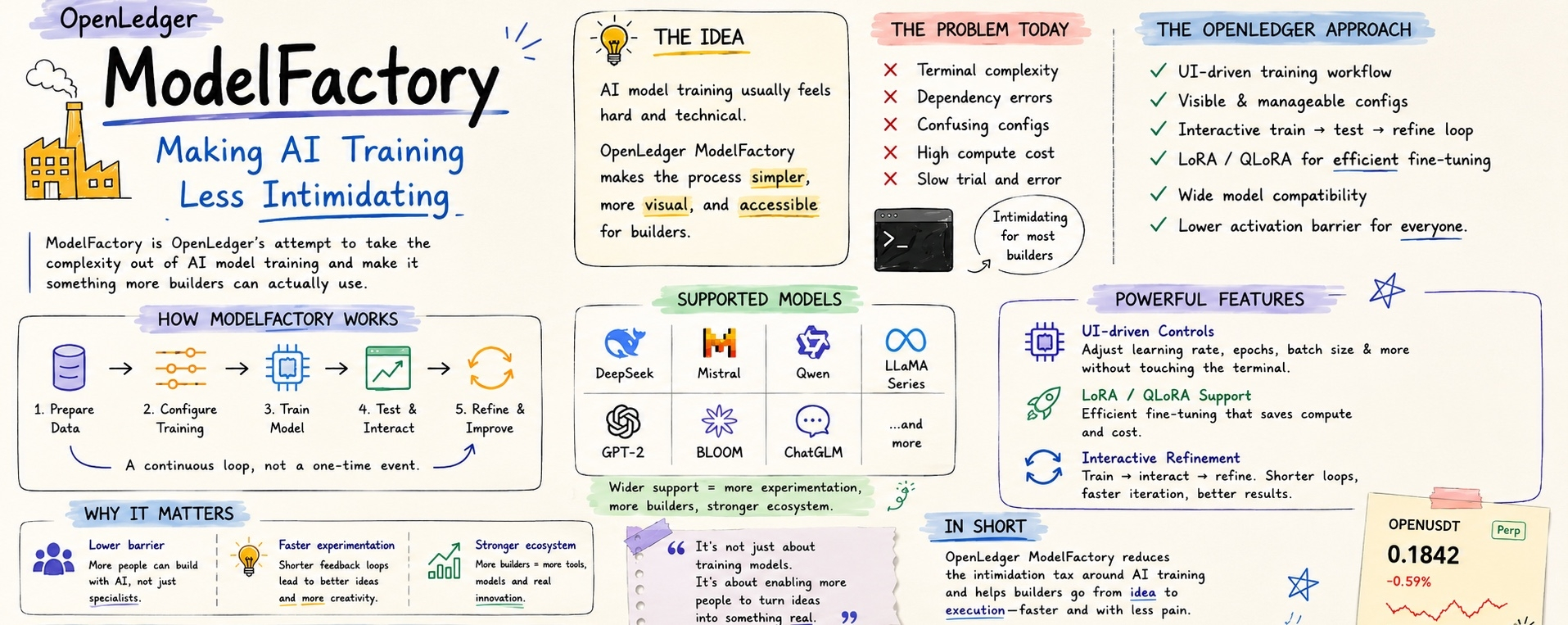
Which is exactly why OpenLedger’s ModelFactory caught my attention differently.
Because the interesting part isn’t simply that OpenLedger supports model training.
A lot of AI infrastructure says that.
The interesting part is how they’re packaging it.
And honestly, that changes who even bothers participating.
Most AI systems still make training feel like something reserved for researchers, infra engineers, or people emotionally comfortable living inside terminals. If the setup friction is painful enough, most builders never even reach the experimentation phase.
That’s not a technology problem.
That’s a participation problem.
ModelFactory seems to understand that.
Instead of framing fine-tuning like some elite engineering ritual, OpenLedger makes the workflow feel more operational. You’re not staring at raw command-line chaos trying to guess whether your environment is about to explode. Training configuration becomes something visible and manageable.
Learning rates.
Epochs.
Batch sizing.
Model configuration.
Those controls still exist.
The difference is they’re not hidden behind intimidation.
That matters way more than people think.
Because AI infrastructure doesn’t only compete on capability.
It competes on how quickly someone goes from:
“I have an idea”
to
“I actually built something.”
That gap kills a lot of ecosystems.
Another thing I liked is how broad the model support appears to be.
DeepSeek.
Mistral.
Qwen.
LLaMA variants.
GPT-2.
BLOOM.
ChatGLM.
That tells you this isn’t some narrow environment trying to push builders into one preferred ecosystem.
Wider compatibility usually means wider experimentation.
And experimentation is what actually creates ecosystem activity.
Then there’s LoRA and QLoRA support, which honestly feels like one of the most practical choices here.
Because full fine-tuning sounds exciting until infrastructure cost reminds you you’re not running a hyperscaler.
Lightweight adaptation paths are simply more realistic for most builders.
Especially if OpenLedger wants participation beyond heavyweight research teams.
That’s not a flashy feature.
That’s practical design.
The refinement loop also stood out to me.
Older model workflows often feel awkward.
Train.
Wait.
Test.
Realize something feels off.
Go back.
Repeat the suffering.
Interactive iteration changes that psychology.
Builders experiment differently when feedback loops get shorter.
People try more things when failure feels cheaper.
That’s not just AI infrastructure.
That’s product behavior.
And honestly, I think that’s the smarter OpenLedger story.
Most people will read ModelFactory as:
“nice, another AI tool.”
I think the bigger angle is participation.
Because lowering technical intimidation changes who builds.
And who builds changes what gets created.
That matters a lot if OpenLedger actually wants an active AI ecosystem instead of a technically impressive ghost town.
AI infrastructure dies surprisingly fast when only specialists can comfortably use it.
The best systems don’t just increase capability.
They lower activation energy.
And ModelFactory feels much closer to that kind of infrastructure than people might initially assume.