Most AI projects talk about intelligence as if it appears at the front of the product.
You open an app. You ask something. A model answers. That is the part everyone sees.
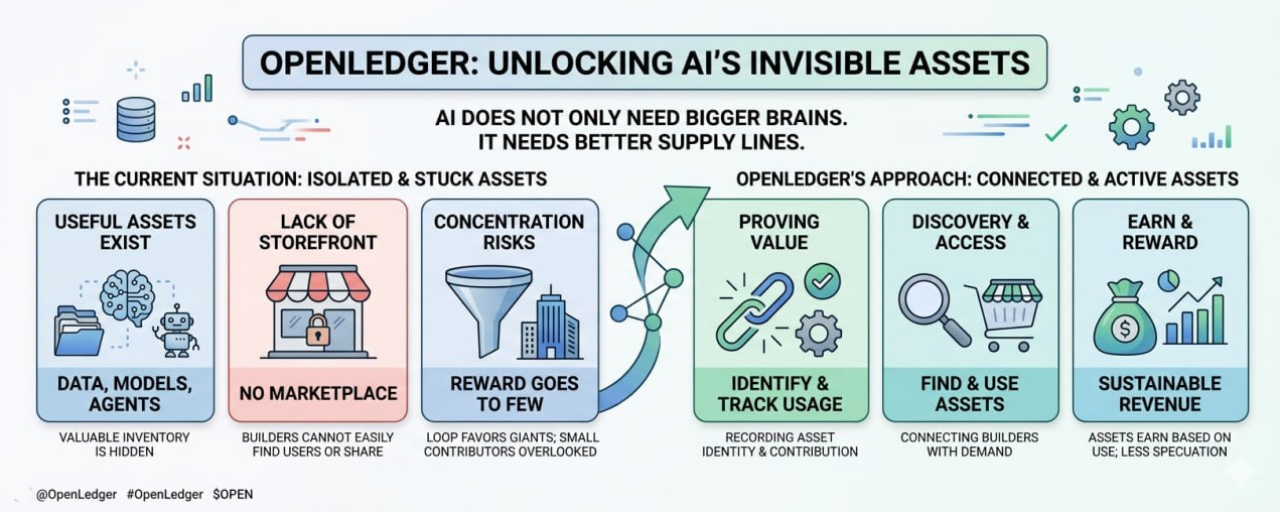
But the more you sit with it, the more it feels like the visible answer is only the last step. Before that, there is a whole shelf of things sitting behind the system. Data. Small models. agents. testing work. private knowledge. corrections. user behavior. Little pieces that shape the output, even when nobody notices them.
@OpenLedger seems to be looking at that shelf.
Not the chatbot window. Not the final answer. The layer behind it, where useful AI assets exist but often have no easy way to move, earn, or even prove that they mattered.
That angle feels more interesting than the usual “AI plus blockchain” framing. Because that phrase has become too easy to ignore. It sounds like two large ideas being pushed together. But with OpenLedger, the better question may be simpler: what happens when AI assets need a place to live before they become part of something bigger?
Right now, many of those assets are stuck.
A company might have a valuable dataset, but it cannot easily share it without losing control. A developer might build a narrow model that works well for one type of task, but it may never find the right users. Someone may create an agent that handles a specific workflow, but it stays inside a small app or private tool. The asset exists, but it has no real market around it.
It is like having useful inventory with no storefront.
That is where OpenLedger’s idea of liquidity starts to make more sense. Not liquidity as noise. Not as charts or quick speculation. More like access. Movement. The ability for data, models, and agents to be discovered, used, tracked, and rewarded without being swallowed whole by one closed system.
You can usually tell when a market is immature because good things stay hidden. They do not move to where they are needed. They sit in folders, private servers, research notes, or small communities. AI has plenty of that. In fact, it may have more hidden value than visible value.
The biggest models get attention because they are easy to point at. But many AI systems become useful because of smaller, quieter inputs. A cleaned dataset from one industry. A local language resource. A model tuned for invoices. An agent trained around customer support rules. A knowledge base that reflects years of internal decisions.
None of these sound dramatic. That may be the point.
AI does not only need bigger brains. It needs better supply lines.
#OpenLedger can be seen as an attempt to build those supply lines. It gives AI-related assets a way to be recorded and connected to usage. The asset does not have to disappear the moment it becomes useful. It can carry an identity with it. It can be part of a network. It can, at least in theory, earn based on how it is used.
That changes the shape of the conversation.
Instead of asking only who owns the final AI product, we can ask what helped make the product work. Instead of treating data as raw material that gets consumed once, we can treat it as something that continues to create value. Instead of seeing agents as isolated tools, we can imagine them as services that plug into larger systems.
The shift is small, but it matters.
Because the current AI economy still favors concentration. The groups with the most compute, data access, and distribution can collect more inputs, build better systems, and then attract even more users. That loop is powerful. It may not be broken easily.
OpenLedger does not need to break it to be relevant. It only needs to create more paths for smaller contributors to participate.
A niche dataset should not need to become a full company to be useful. A model builder should not need massive distribution to find demand. An agent should not need to live inside one platform forever. If these pieces can be listed, discovered, verified, and paid for when used, then the AI market becomes less flat. More layered.
Of course, this also brings problems.
Measurement is hard. It is one thing to say an asset contributed value. It is another thing to prove it. A model output may depend on many inputs at once. A dataset may improve performance indirectly. An agent may save time, but the value of that time can be unclear. Attribution can become messy very quickly.
Quality is another issue. Open markets attract useful work, but they also attract clutter. If everyone can publish datasets, models, and agents, then discovery becomes its own problem. People will not want more assets. They will want the right ones.
There is also trust.
Some data should not move freely. Some models may carry hidden risks. Some agents may behave well in tests and poorly in live environments. So the system cannot only be about monetizing assets. It also has to be about knowing what those assets are, where they came from, and how they behave over time.
That is probably where the blockchain part matters most. Not as decoration. More as memory.
A shared record can help show ownership, usage, permissions, and history. It can make the movement of AI assets less vague. It can help different parties work together without needing one platform to control the whole relationship.
Still, the real test will be whether builders feel less friction, not more.
If using OpenLedger feels complicated, people will avoid it. If it helps a dataset owner connect with demand, or helps a model earn from real usage, or helps an agent become reusable across systems, then the idea starts to feel practical.
That is the quiet possibility here.
OpenLedger is not only about making AI smarter. It is about making the pieces around AI easier to use without losing them. It treats data, models, and agents less like background material and more like active assets.
And maybe that is where the next part of AI begins to form.
Not in the loudest model release. Not in the most polished app.
But somewhere in the middle, where useful pieces are waiting for a better way to move.