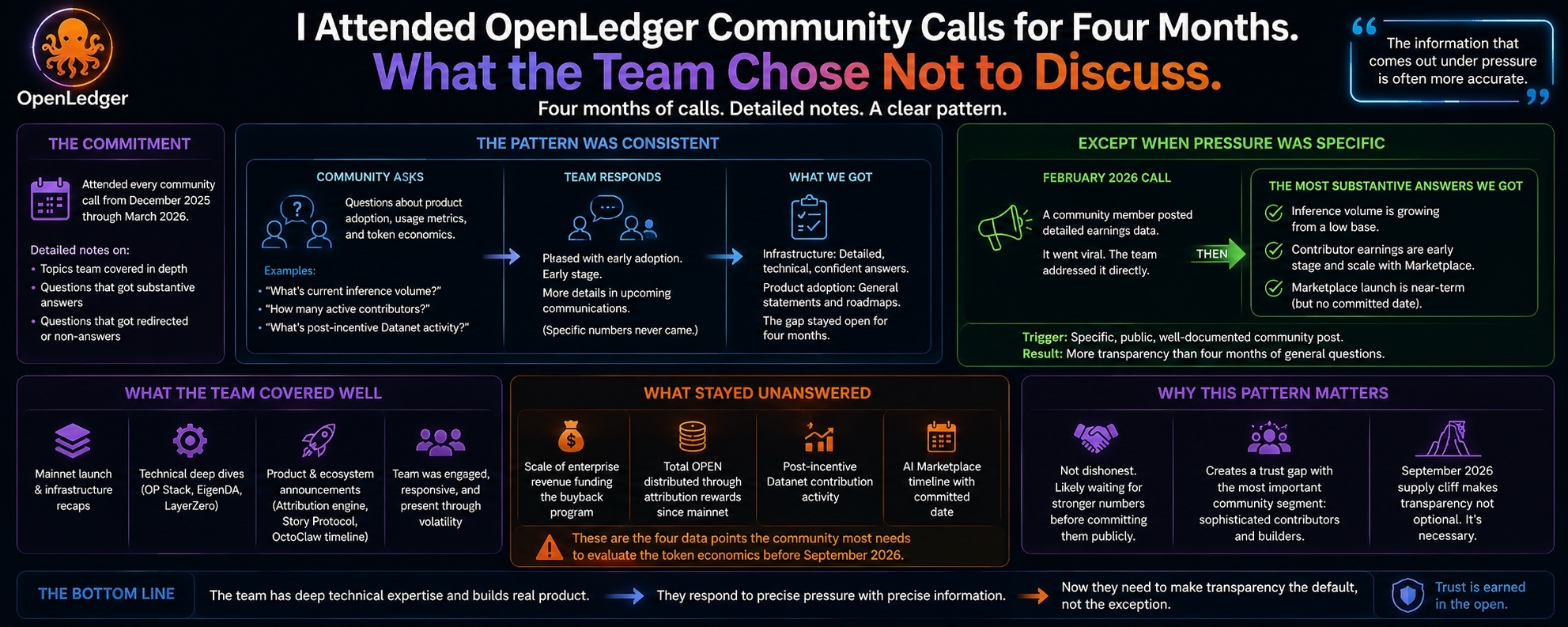
I started attending OpenLedger's community calls in December 2025, about three weeks after mainnet launched. I attended every one I could make through the end of March 2026. I kept notes, specifically on three categories: topics the team covered in depth, topics raised by community members that received substantive answers, and topics raised by community members that received redirected or non-answers. The third category is the one this piece is about.

The first call I attended was in December, during the price volatility period. The team opened with a mainnet launch recap: the infrastructure was running, the model ecosystem was active, the contribution tracking was live. The presentation was confident and technically specific about the infrastructure layer. When the Q&A opened, the first five questions were all variations of: what are your current usage metrics, specifically inference volume, active contributors, and post-incentive Datanet activity? The team's answer to each of these, in different framings, was that they were pleased with early adoption and would share more detailed metrics in upcoming communications. The upcoming communications never included the specific numbers these questions were asking for.
I noticed this pattern consistently across the four months. Infrastructure questions, how does the OP Stack handle transaction finality, what is EigenDA's cost structure, how does the LayerZero integration work technically, these received detailed and confident answers that showed the team had deep technical knowledge of their own architecture. Product adoption questions, how many unique wallets have used ModelFactory, what is the post-mainnet active contributor count, how much OPEN has been distributed through the attribution reward mechanism, consistently received redirects to the roadmap or general statements about "early stage adoption."
The calls were not unproductive. The team used them to announce real things: the attribution engine update, the Story Protocol partnership details, the OctoClaw launch timeline. These announcements were substantive. The pattern I was tracking wasn't about the quality of what got announced. It was about the gap between what the community was asking to know and what the team was choosing to share.
The most instructive call happened in February 2026, about a week after a community member had posted the public accounting of their contributor earnings that I mentioned in another piece. That post had attracted enough attention that it was clearly on the team's radar before the call started. The team addressed it directly and spent more time on the attribution reward mechanism and current earnings dynamics than any previous call had. The information they shared was more specific: inference volume was growing but starting from a low base, contributor earnings at current volume were in an early stage and would scale with the Marketplace launch, the expected Marketplace timeline was near-term but not committed to a specific date. This was the most substantive answer to a product adoption question I heard across four months of calls.

What struck me about that February call was not just the content but the trigger. The team shared more specific information about contributor economics in response to a specific, public, well-documented community post than they had in response to months of general questions. This is a communication pattern I recognize from other organizations: the information that comes out under pressure is often more accurate than the information shared proactively. It's not a behavior unique to OpenLedger and I don't think it reflects bad intentions. It reflects an organization that hasn't yet made specific quantitative transparency a default operating mode.
The topics that were never addressed substantively across all four months, regardless of how they were raised: the scale of the enterprise revenue funding the buyback program, the total volume of OPEN distributed through attribution rewards since mainnet, the post-incentive Datanet contribution activity, and the specific timeline for the AI Marketplace with a committed date rather than "near-term." These four pieces of information are the ones that would let the community evaluate whether OpenLedger's token economics are likely to work before the September 2026 supply cliff. They are, I believe, the pieces of information the community most needs and that the team is most reluctant to share.

I don't think this reluctance is dishonest. I think it reflects an organization that knows its current metrics are below the narrative level its token price established at the TGE and that is waiting for stronger numbers before committing them to public documentation. That's understandable. It creates a trust gap with exactly the contributors and builders who make up the most important part of the community, the people who are sophisticated enough to know what questions to ask and patient enough to ask them repeatedly across four months of calls.
@OpenLedger $OPEN #OpenLedger $BSB
