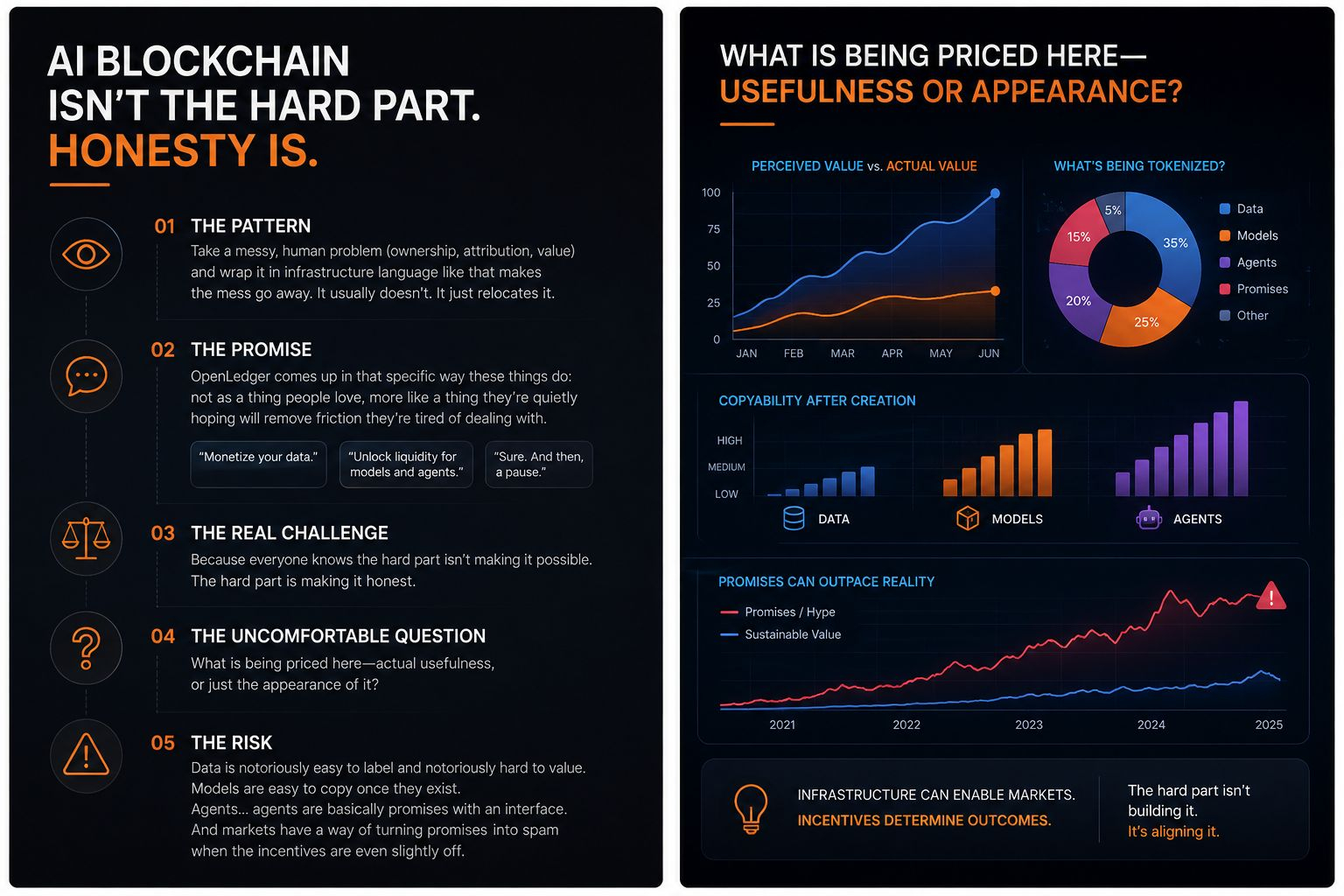
@OpenLedger $OPEN I’ll admit it: when I first heard “AI blockchain” I felt my eyes glaze over. Not because it’s impossible, but because I’ve seen this pattern too many times—take a messy, human problem (ownership, attribution, value) and wrap it in infrastructure language like that makes the mess go away. It usually doesn’t. It just relocates it.
OpenLedger keeps coming up in conversations in that specific way these things do: not as a thing people love, more like a thing they’re quietly hoping will remove friction they’re tired of dealing with. “Monetize your data.” “Unlock liquidity for models and agents.” Sure. And then, a pause. Because everyone knows the hard part isn’t making it possible. The hard part is making it honest.
I keep coming back to the same uncomfortable question: what is being priced here—actual usefulness, or just the appearance of it? Data is notoriously easy to label and notoriously hard to value. Models are easy to copy once they exist. Agents… agents are basically promises with an interface. And markets have a way of turning promises into spam when the incentives are even slightly off.
Maybe that’s too cynical. There’s a real itch being scratched. People have been extracting value from data and labor for years while the sources get nothing, or get paid once and then forgotten. On paper, having a ledger that can track contributions and route payments feels like the kind of boring fix that might actually matter. Not glamorous. Just… fairer, maybe.
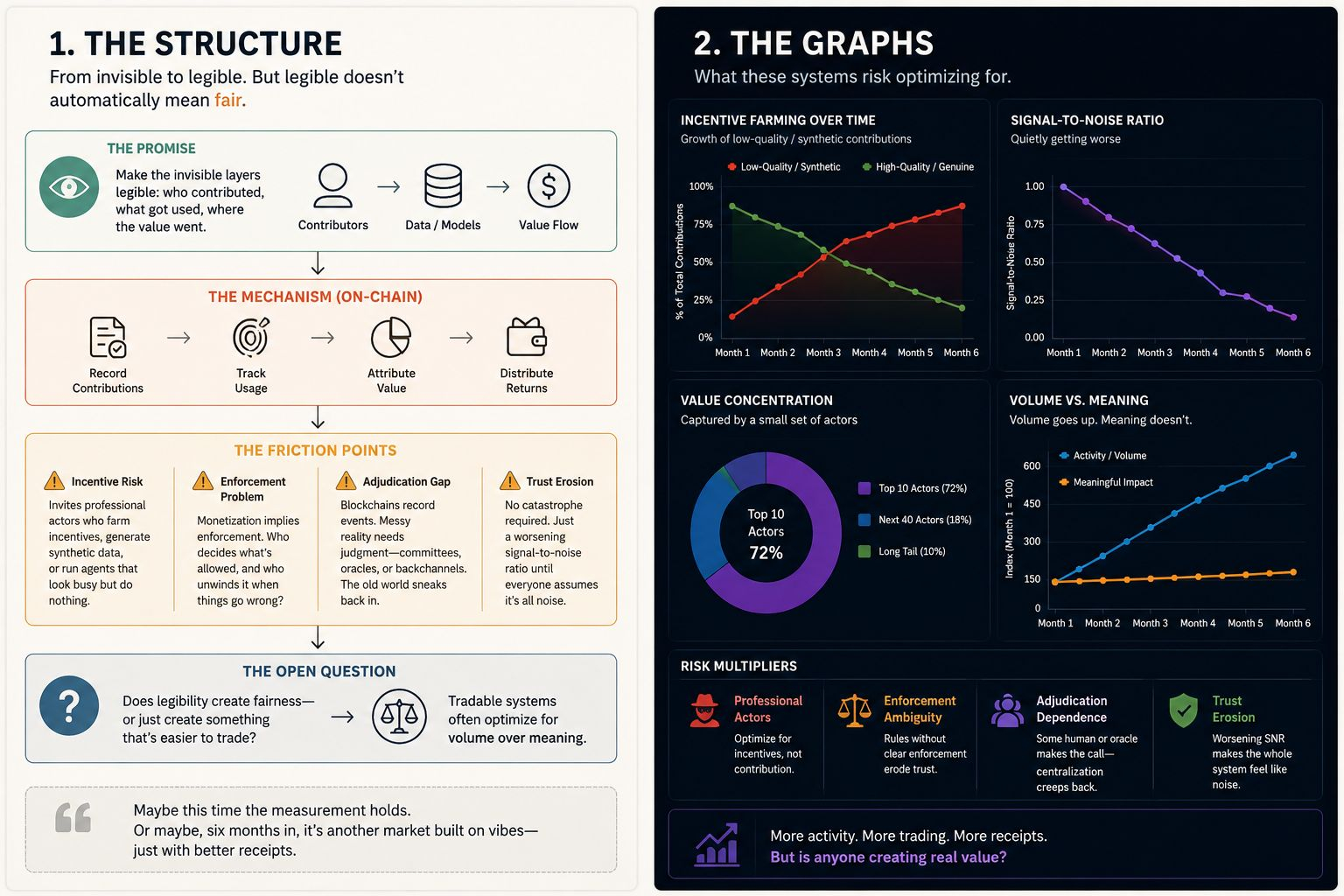
But the underlying behavior of a system like this isn’t “users monetize data.” It’s: participants compete to be the most *measurable* source of value. And measurement is where everything starts to bend. If the system rewards “data that improves models,” you’ll get data shaped to look improving. If it rewards “agent performance,” you’ll get agents optimized for benchmark theater. The incentives don’t just attract contributors—they sculpt them.
And then the verification problem shows up, like it always does, wearing a different hat. Who says the dataset is what it claims to be? Who checks it isn’t scraped, duplicated, poisoned, or just legally radioactive? Who decides a model’s outputs are “derived from” a contribution versus merely correlated with it? I’ve watched attribution systems collapse under their own ambition, not because the math was wrong, but because the edge cases became the main case.

It also feels weirdly delicate under scale. Once you attach liquidity to “intelligence assets,” you invite a certain kind of actor. Not evil, just… professional. The kind that farms incentives. The kind that hires people to generate synthetic data that passes plausibility checks. The kind that spins up agents that look busy, talk a lot, and do nothing. You don’t need a catastrophic exploit for trust to erode. You just need the signal-to-noise ratio to quietly worsen until everyone assumes it’s all noise.
The part people don’t say out loud is that “monetization” implies enforcement somewhere. If a model is trained on something it shouldn’t be, what happens? If a contributor claims rights they don’t have, who unwinds it? If an agent causes damage, who eats it? Blockchains are good at recording events. They’re not naturally good at adjudicating messy reality without someone—some committee, some oracle, some backchannel—making judgment calls. That’s where the old world sneaks back in.
Still, I can’t dismiss the impulse behind OpenLedger. There’s something real about trying to make the invisible layers legible: who contributed, what got used, where the value went. I just don’t know if making it legible makes it fair, or if it just makes it tradable.
And tradable systems have a habit of optimizing for volume over meaning. I keep watching this space try to financialize whatever it can measure. Maybe this time the measurement holds. Or maybe, six months in, everyone’s arguing about fake contributions and “bad actors,” and the whole thing starts to feel like another market built on vibes—just with better receipts.