or just tokenized hope)
Been going through openledger’s docs and random threads to understand what they’re actually building, and what caught my attention isn’t the “ai + blockchain” headline. it’s the attempt to turn messy, off-chain ai inputs (data, labels, model outputs, evals) into something the chain can coordinate economically without pretending the chain can store or verify everything directly.
most people think openledger is just another ai + crypto token with a marketplace slapped on. i get why — the surface narrative is basically “contributors upload data, get rewards.” but the more interesting (and fragile) part is the long-term network design: who can prove they added value, and can the system pay for that value without leaning forever on emissions.
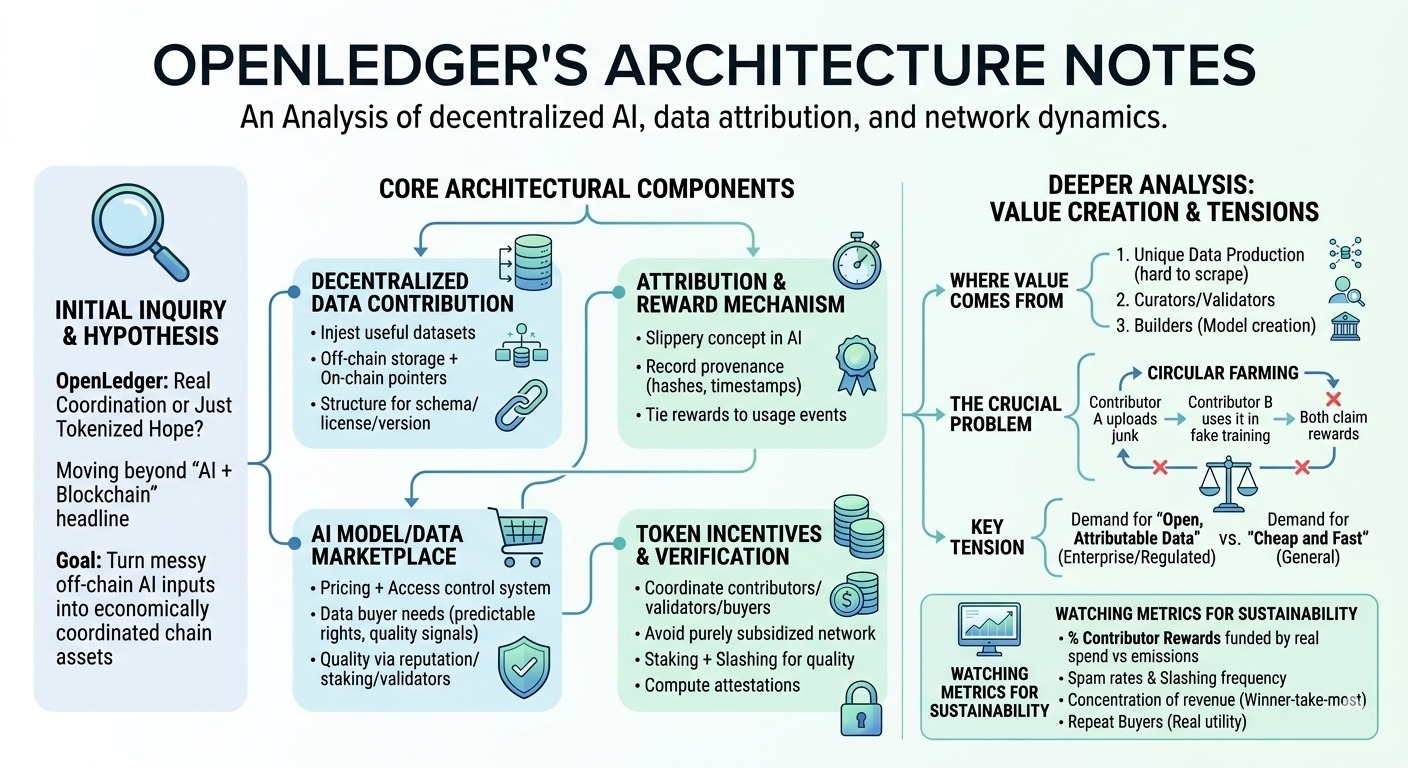
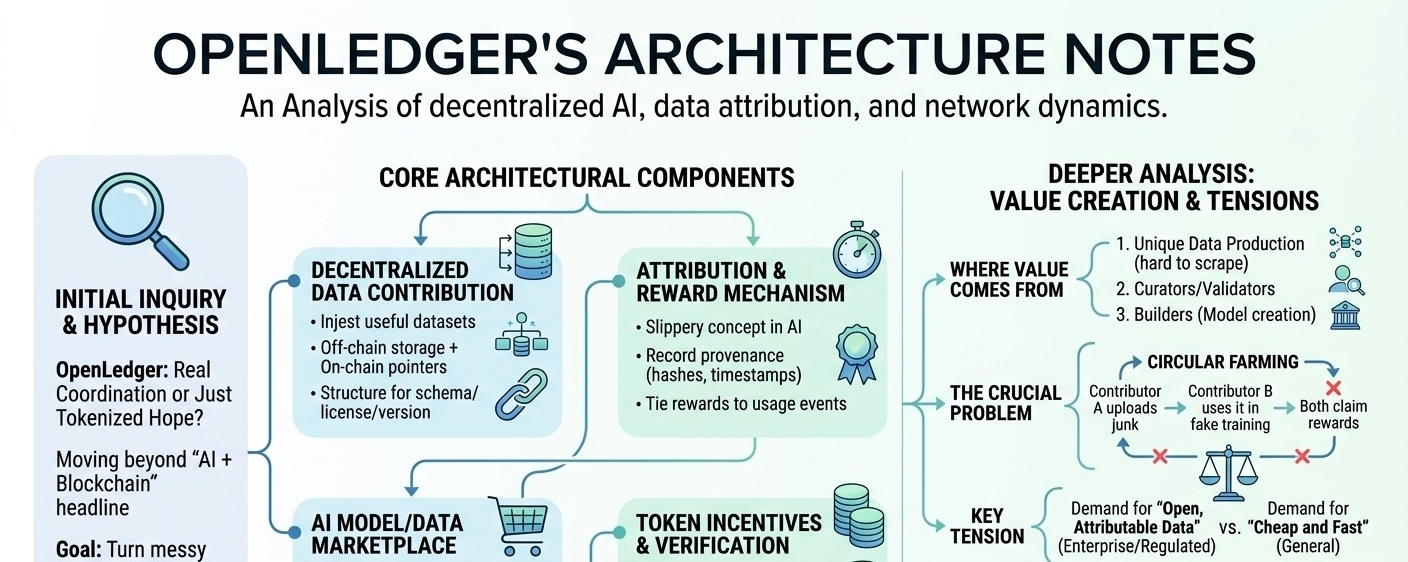
a few components seem core:
1) decentralized data contribution system
the system lives or dies on whether it can attract useful datasets, not just volume. in practice that means pipelines for ingesting data (probably off-chain storage + on-chain pointers/hashes), plus some structure around schema, licensing, and versioning. i’m assuming they’ll need strong conventions here, otherwise contributors optimize for whatever is easiest to upload. the “decentralized” angle is less about storage and more about who gets to participate in creating the corpus.
2) attribution + reward mechanism
openledger keeps emphasizing attribution, and honestly this is the part i keep thinking about… because attribution in ai is slippery. it’s not like a smart contract where you can trace execution deterministically. the credible approach is usually: record provenance (hashes, timestamps, contributor ids), then tie rewards to usage events (a dataset was pulled into a training run, a model fine-tune referenced it, an eval benchmark used it, etc.). but then the hard question: who attests that usage happened, and what prevents fake usage loops?
3) ai model/data marketplace dynamics
if they’re serious, the “marketplace” isn’t a storefront, it’s a pricing + access control system. data buyers (model builders, app teams) need predictable rights: can they train? can they redistribute outputs? is it exclusive? and they need quality signals. open platforms struggle here because quality is expensive to verify and centralized platforms solve it with internal review + contracts. openledger is trying to externalize that into network mechanics (reputation, staking, third-party validators, maybe curated subnets). i’m not sure how mature that is yet.
4) token incentives and network coordination / verification layer
the token piece seems intended to coordinate contributors, validators/curators, and buyers. but it’s also where the “is demand real?” question sits. if most rewards come from emissions rather than from actual buyers paying for datasets/models, the network can look healthy while it’s basically subsidized. some kind of verification layer (staking + slashing for bad data, signed attestations, maybe even compute attestations) would help, but it’s also overhead.
going deeper: who creates value?
i think value comes from three places: (a) people producing unique data that’s hard to scrape (domain-specific labels, multilingual transcripts, niche sensor data), (b) curators/validators who make that data usable, and (c) builders who turn it into models people pay to use. the protocol’s bet is that on-chain attribution can route money back to (a) and (b) automatically. but attribution stays trustworthy only if “usage” is hard to forge. otherwise, you get circular farming: contributor A uploads junk, contributor B “uses” it in a fake training job, both claim rewards.
a realistic example: imagine a customer-support fine-tune dataset (chat logs, labeled intents, redactions). if a model builder pays to fine-tune on it, you can attribute that purchase. but attributing downstream value (the model’s inference revenue later) is much harder unless inference happens through a metered gateway the protocol can observe. open systems tend to leak here: models get exported, served privately, and the chain sees nothing.
the tension i can’t shake
openledger seems to assume sustained demand for “open, attributable data” from ai builders. maybe that’s true in regulated or enterprise contexts, where provenance matters. but a lot of ai demand still wants cheap and fast, not necessarily attributable. and contributor incentives feel fragile: if rewards are high, spam floods in; if rewards are low, only hobbyists contribute. sustainability probably requires a tight loop where real buyers pay for real utility, and the token is mostly a coordination tool, not the product.
watching:
- % of contributor rewards funded by real marketplace spend vs emissions
- spam/low-quality rates and how often slashing/penalties actually trigger
- concentration: do a few curators/datasets dominate revenue (winner-take-most dynamics)
- repeat buyers: are teams coming back to purchase data/model access, or is it one-off
i don’t have a clean conclusion yet. i can see a world where attribution + licensing + payment rails actually help niche data markets function. i can also see it becoming an elaborate reward game that looks busy until subsidies taper. the question i keep coming back to: can openledger measure “use” in a way that’s both privacy-preserving and hard to fake, without quietly re-centralizing the whole thing?