
Ok so when i first looked at this whole openledger thing, i swear my first reaction was like yeah another system with rules, limits, caps and all that stuff. but then i kept reading and it started making more sense to me. i dont think this is random control just for the sake of control, i think they are trying to build a clean space where data is not just uploaded and forgotten but actually treated like something that can earn value later.
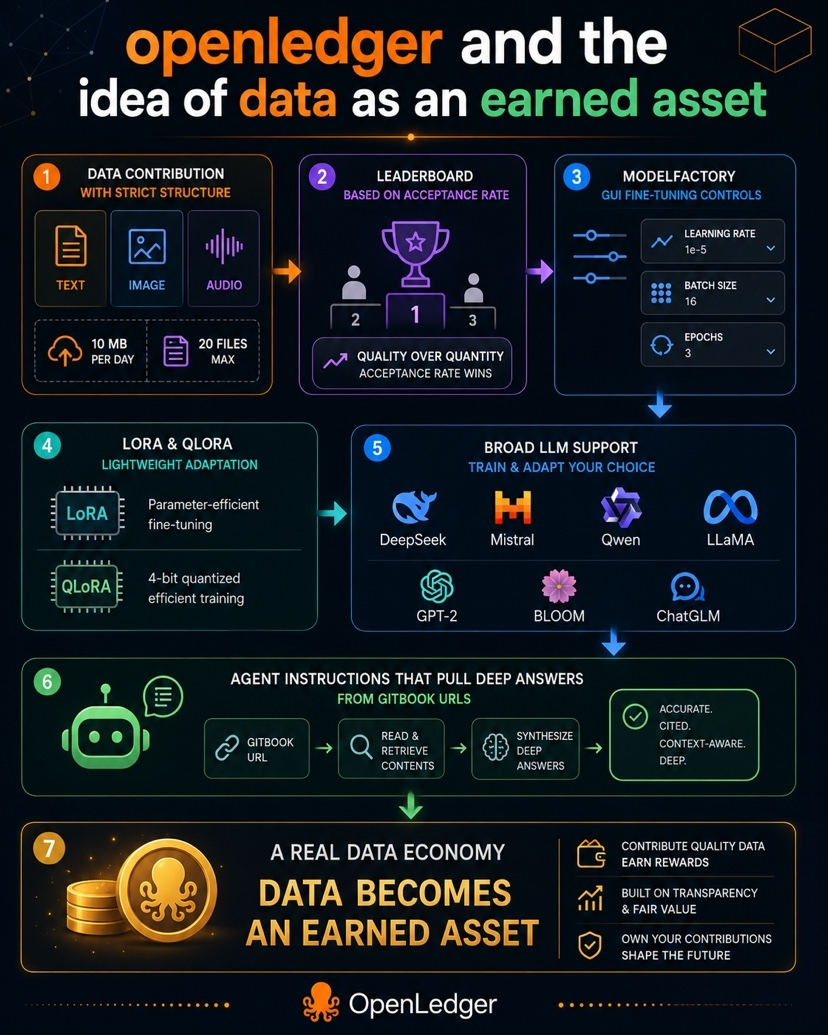
the datanets contribution layer is where i paused first because it feels strict. text is text, image is image, audio is audio, you cant just mix everything and throw it in. normally in web3 we hear “open for everyone” and “permissionless” so this feels opposite at first. but honestly i get why they did it. if everyone uploads anything without checks then the system becomes messy so fast. 10mb per day and 20 files max sounds small but i think its not really about making it hard, its more about stopping spam and keeping the good data easier to find.
what i liked more is the leaderboard part. at first i thought okay maybe more uploads means better rank but no, it is more about acceptance rate. and i like that because it pushes people to think before uploading. if i upload 20 bad files just to look active, the system wont reward that. but rejected files also dont destroy your rank which is actually a good thing. it gives space to test things without being scared. i think that small detail says a lot about how they want people to contribute.
then i looked at modelfactory and this is where it became more serious for me. they are trying to make model training look less scary. like you dont need to be sitting in terminal all day pretending to be some deep ai engineer. learning rate, batch size, epochs all of it can be adjusted in a gui style. i think thats smart because ai building should not only belong to people who know every command line thing. but at the same time they are not making it too loose either, there is still control in the process.
lora and qlora support also makes sense because full fine tuning is expensive and not everyone can do that. so this lightweight route feels more practical. the train, test, interact, refine loop is the part i keep thinking about because it makes model building feel like something alive not like you train once and leave it. and then when i saw the supported llms list like deepseek, mistral, qwen, llama, gpt-2, bloom, chatglm etc, i first thought they are just adding everything lol but maybe thats the point. wider model support means more people can experiment in different ways.
the funniest picture in my head is like openledger is a strict kitchen. you cant just throw random spices in the pot but once the food is ready, people can taste it, test it and rate it. thats kinda how i see it. vibes alone wont work here. you need clean data, useful contribution and some actual value.
also the agent instructions part is underrated in my opinion. if deep queries can pull answers from gitbook url then it is not just dead documentation sitting there. it becomes more like a live knowledge system that can answer based on actual docs. overall i think openledger is trying to stand between two opposite sides. one side is open contribution and decentralization, the other side is strict validation and structure. that balance is hard. i dont know if they will fully get it right but i do think the idea is worth watching because if data really becomes an earned asset then this kind of system could matter more than people think.
