Có một buổi tối cách đây không lâu, mình lướt X (Twitter) và thấy một cuộc tranh luận khá gắt giữa một bên là các dev Web3 và một bên là các kỹ sư Data Science. Phe Web3 thì hào hứng bảo "Crypto sẽ phi tập trung hóa AI bằng cách trả token cho người dùng nạp data", còn phe AI thì cười trừ phản pháo "Mấy ông nghĩ AI là cái thùng rác thích đổ gì vào rồi trả tiền là xong à?". Lúc đó mình chỉ nghĩ trận chiến này chắc còn lâu mới có hồi kết.
Nhưng hôm qua, khi ngồi lật giở tài liệu kỹ thuật của OpenLedger đến phần Proof of Attribution (PoA), mình bỗng thấy một lối đi mà có vẻ như dự án này đang muốn dùng để dàn xếp cuộc xung đột nói trên. Định nghĩa của họ nghe qua thì vẫn rất "vibe" Web3: Hệ thống ghi nhận đóng góp on-chain giúp xác định tầm ảnh hưởng của dữ liệu lên đầu ra của mô hình và trả thưởng bằng $OPEN. Thú thực, nếu chỉ đọc lướt, bạn sẽ dễ dàng tặc lưỡi bỏ qua và xếp nó chung mâm với làn sóng Data-to-Earn quen thuộc.
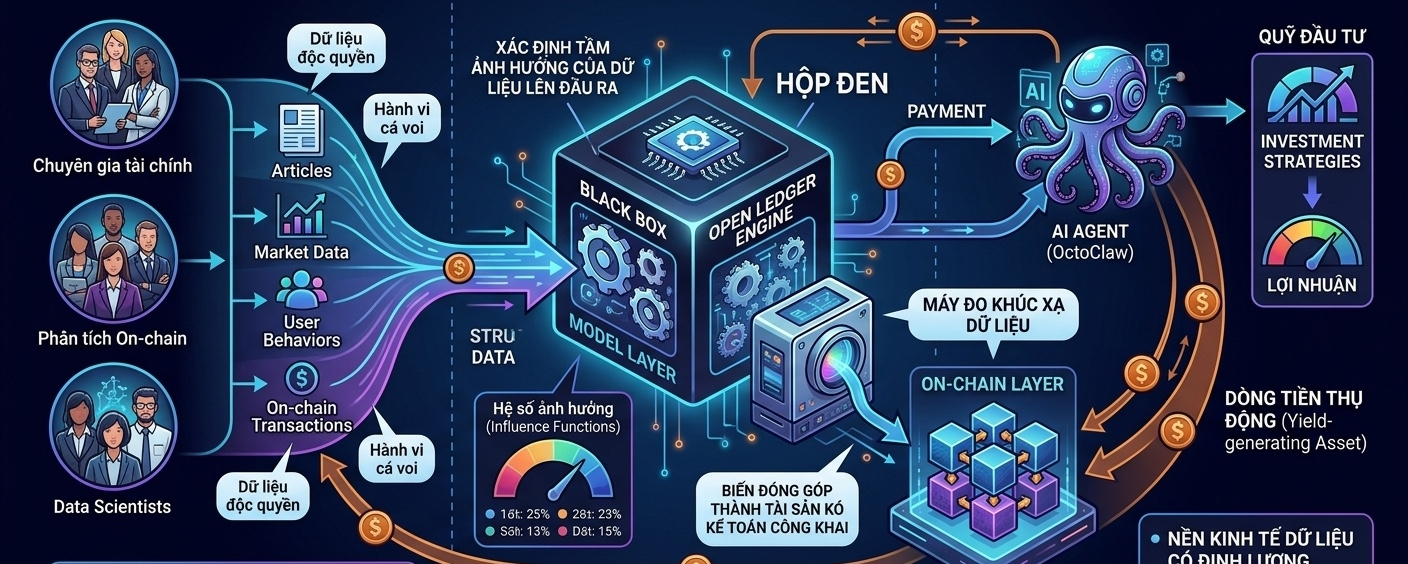
Nhưng khi mình khựng lại ở cụm từ xác định tầm ảnh hưởng lên đầu ra, mình nhận ra OpenLedger không hề chọn cách tiếp cận ngây thơ là đi gom data thô. Họ đang nhảy thẳng vào phần lõi gai góc nhất của bài toán kinh tế AI.
Bình thường với mấy trend phi tập trung hóa dữ liệu, người ta thường chỉ tập trung vào lớp Input. Nghĩa là làm sao để thu thập, làm sạch, định danh dữ liệu rồi lưu nó lên blockchain và trả token cho người nạp. Quá trình đó gần như kết thúc ngay khi dữ liệu được đưa vào kho.
Nhưng PoA của OpenLedger lại không dừng ở kho. Nó đang nói về câu chuyện diễn ra sau khi dữ liệu đã đi vào bên trong mô hình và tạo ra kết quả. Và từ đoạn đó, mình bắt đầu đọc toàn bộ cơ chế này theo một hướng thực tế và "đau đầu" hơn nhiều.
Trước đây, tụi mình thường hình dung việc bán dữ liệu cho AI giống như bán nguyên liệu thô. Bạn đem một ký dữ liệu đến, hệ thống cân lên, trả bạn bấy nhiêu tiền là hết nhiệm vụ. Nhưng AI không hoạt động như một cái máy xay sinh tố. Khi bạn nạp một nghìn bài viết về tài chính vào mô hình, không phải bài viết nào cũng đóng góp giá trị như nhau cho câu trả lời cuối cùng của AI.
Có những bài viết chứa thông tin cốt lõi làm thay đổi hoàn toàn nhận thức của mô hình, nhưng cũng có chín trăm bài viết khác chỉ là thông tin lặp lại, nhiễu, hoặc hoàn toàn vô giá trị. Nếu trả thưởng cào bằng theo dung lượng, hệ thống sẽ nhanh chóng ngập tràn rác. Còn nếu muốn trả thưởng công bằng, hệ thống phải trả lời được câu hỏi cực khó là: Trong câu trả lời xuất sắc kia của AI, có bao nhiêu phần trăm công sức thuộc về bộ dữ liệu của bạn?
Đây chính là chỗ làm mình thấy PoA thú vị hơn một cái chợ mua bán data thô. Thứ họ đang cố gắng xây dựng giống như một chiếc máy đo khúc xạ dữ liệu nằm ngay tại biên giới giữa Model Output và Blockchain.
Nếu đọc PoA theo hướng toán học và hệ thống, mình hình dung một workflow phức tạp được chia thành hai lớp rõ rệt. Lớp trí tuệ nhân tạo bên dưới sẽ sử dụng các kỹ thuật toán học để tính toán xem nếu loại bỏ bộ dữ liệu của bạn ra khỏi quá trình huấn luyện hoặc truy xuất, thì chất lượng đầu ra của mô hình giảm đi bao nhiêu, từ đó gán cho nó một điểm số ảnh hưởng.
Ngay sau đó, lớp blockchain phía trên sẽ biến điểm số này thành một bằng chứng mật mã, ghi nhận trực tiếp lên on-chain và kích hoạt hợp đồng thông minh để tự động phân phối $OPEN tương ứng.
Điều làm mình chú ý không phải là thuật toán AI vì các nhà khoa học dữ liệu đã làm điều này trong phòng thí nghiệm từ lâu. Thứ làm mình chú ý là việc on-chain hóa cái sự ảnh hưởng đó.
Trong thế giới Web2, các ông lớn công nghệ lấy dữ liệu của chúng ta để tạo ra những mô hình trị giá hàng tỷ đô, nhưng họ giữ cái hộp đen đó cho riêng mình. Bạn không bao giờ biết dữ liệu của mình đóng góp bao nhiêu phần trăm vào thành công của họ, và họ có quyền từ chối trả tiền cho bạn. Bằng cách đưa PoA lên chuỗi, OpenLedger đang cố gắng biến sự đóng góp của dữ liệu thành một tài sản có thể kiểm toán công khai. Nó không còn là lời hứa của dự án, mà là logic của code.
Càng nghĩ về PoA, mình càng thấy nó không chỉ phục vụ cho việc huấn luyện mô hình, mà còn là mảnh ghép chí mạng cho kỷ nguyên AI Agent thương mại độc lập.
Hãy tưởng tượng một kịch bản ở trạng thái production, bạn là một chuyên gia sở hữu một bộ data độc quyền về hành vi của các ví cá voi và bạn quyết định đóng góp nó vào OpenLedger thay vì bán đứt. Ngày mai, một AI Agent của một quỹ đầu tư gọi API vào hệ thống để xin một chiến lược giao dịch.
Nhờ bộ data của bạn, Agent đưa ra một quyết định giúp quỹ lãi lớn. Hệ thống PoA ngay lập tức ghi nhận bộ dữ liệu của bạn đóng góp bao nhiêu phần trăm vào độ chính xác đó, và dòng tiền từ phí dịch vụ của quỹ được trích thẳng vào ví của bạn dưới dạng $OPEN. Lúc này, bộ dữ liệu trở thành một dòng tiền thụ động đúng nghĩa dựa trên giá trị thực tế mà nó tạo ra trong thời gian thực.
Tất nhiên, nhìn dưới góc độ kỹ thuật thì cấu trúc này của OpenLedger đi kèm với những bài toán đánh đổi cực kỳ lớn. Việc tính toán tầm ảnh hưởng cho từng node dữ liệu trong một mô hình lớn là một cực hình về mặt tài nguyên phần cứng.
Nếu chi phí để tính ra ai đóng góp bao nhiêu còn cao hơn cả chi phí chạy mô hình, hệ thống sẽ bị nghẽn bẫy kinh tế và họ sẽ phải giải bài toán tối ưu hóa này rất tốt thông qua các lớp chứng minh dữ liệu. Bên cạnh đó, nếu bản thân thuật toán đo lường tầm ảnh hưởng bị thao túng hoặc có sai lệch, niềm tin vào toàn bộ hệ thống phân phối token cũng sẽ lung lay.
Nhưng chính trade-off đó lại làm mình thấy OpenLedger đang chạm vào một lớp khá thật của giao lộ AI và crypto. Nếu Cloud Config của OctoClaw là giải pháp để vận hành AI ở quy mô lớn, thì PoA chính là dòng máu kinh tế nuôi sống hệ thống đó. Họ không chọn con đường dễ là hô hào khẩu hiệu phi tập trung chung chung, mà đang đi thẳng vào việc giải quyết phần gốc rễ về quyền sở hữu và giá trị thặng dư của dữ liệu.
Theo mình, nếu đọc PoA theo hướng đó thì thứ đang được định hình không chỉ là một cơ chế trả thưởng, mà là một nền kinh tế dữ liệu có định lượng. Nơi mà giá trị bạn nhận lại không phụ thuộc vào việc bạn quảng cáo ra sao, mà phụ thuộc vào việc dữ liệu của bạn thực sự thông minh đến mức nào khi bước vào thực tế.