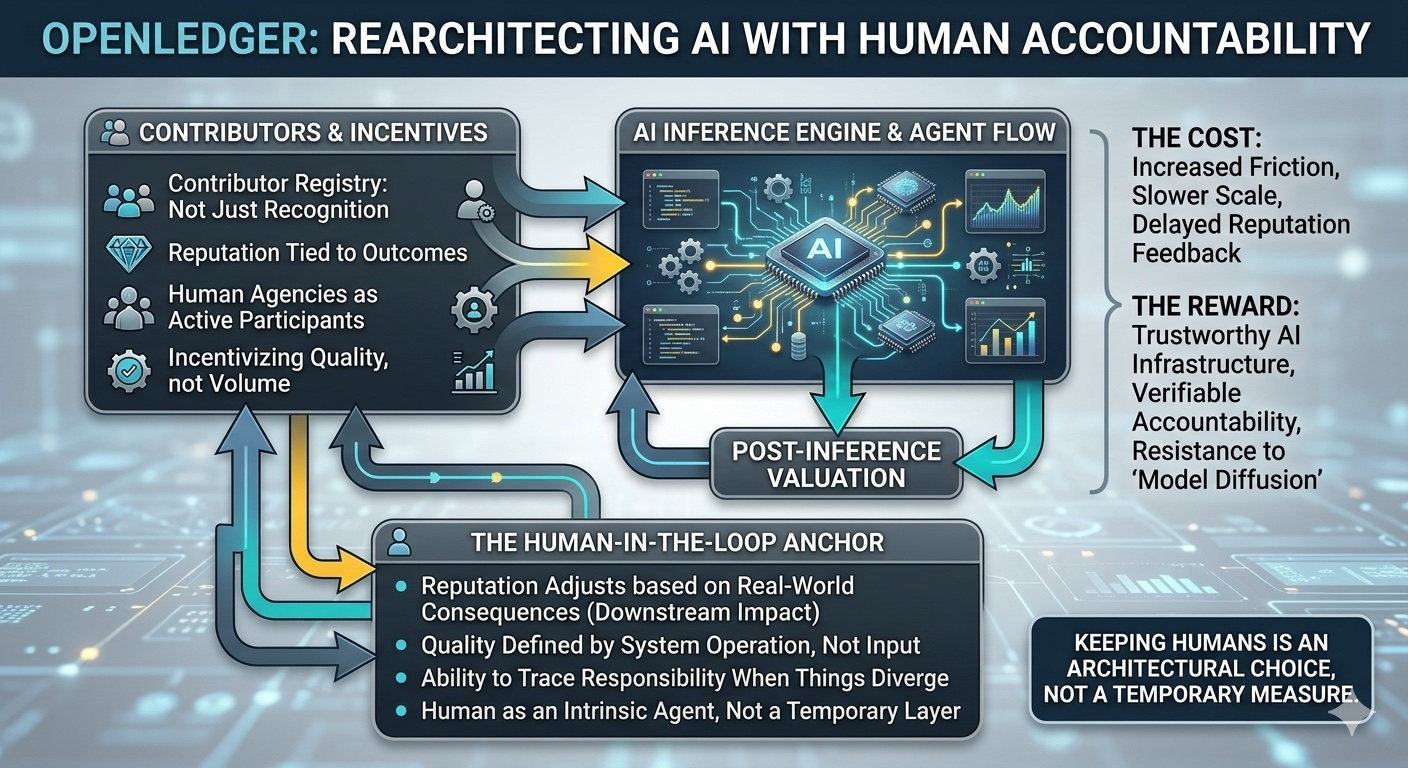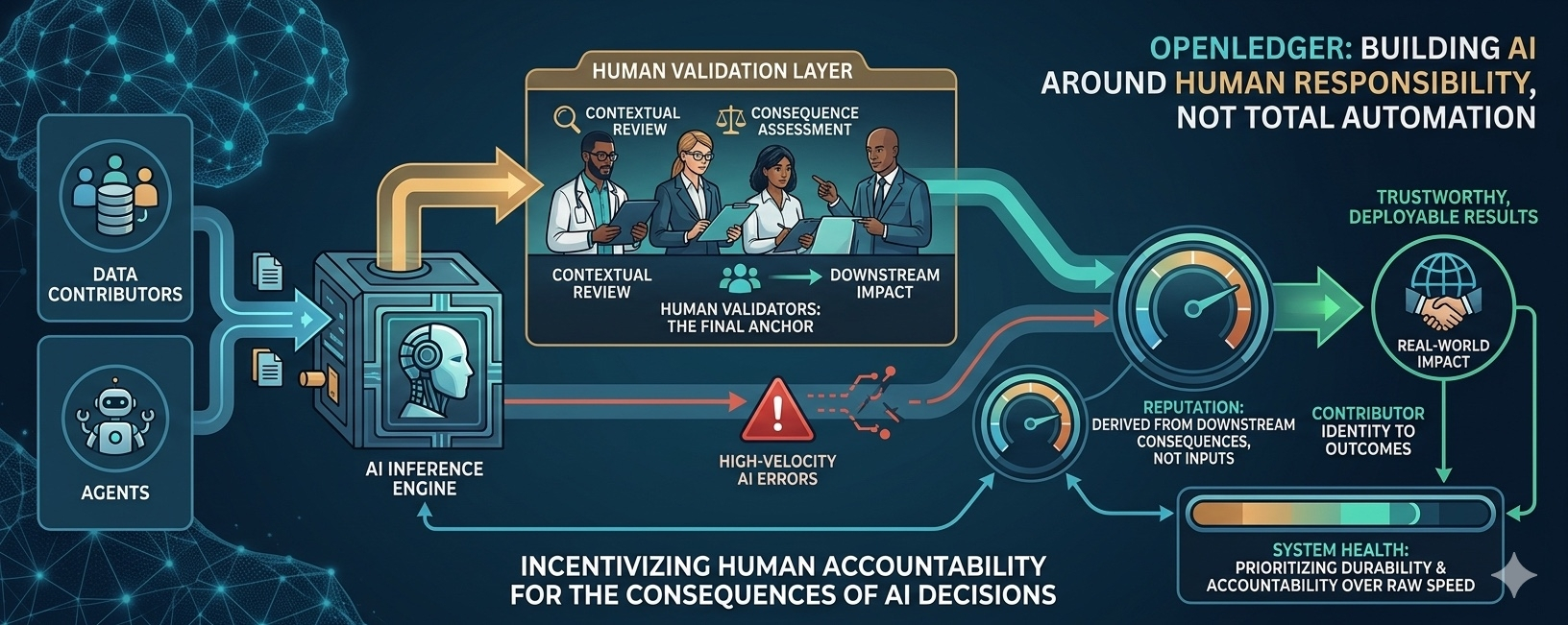
Mình đã dạo khắp các diễn đàn, đọc kĩ các bài viết về OpenLedger. Thế nhưng có một điều ít ai nhắc tới chính là vai trò của Human-in-the-loop.
@OpenLedger không nói rằng con người là lớp giám sát tạm thời. Họ cũng không hứa rằng khi AI đủ thông minh thì lớp này sẽ biến mất. Cách họ viết khiến mình hiểu một điều rất rõ. Nếu gỡ con người ra khỏi hệ thống này, không phải một module bị lỗi, mà toàn bộ kiến trúc sẽ mất ý nghĩa.
OpenLedger không xây AI infrastructure với mục tiêu tối đa hóa tự động hóa. Họ xây nó quanh một câu hỏi khác, nghe có vẻ chậm chạp hơn, nhưng thực tế lại khó hơn nhiều. Khi AI đã chạy đúng, đã tối ưu, đã đưa ra quyết định hợp lý theo mô hình, thì ai chịu trách nhiệm cho hậu quả nếu quyết định đó vẫn sai trong bối cảnh thực.
Câu trả lời của họ không nằm ở triết lý, mà nằm trong thiết kế. Contributor registry không chỉ để ghi nhận ai đóng góp. Reputation không chỉ là phần thưởng cho hành vi tốt trong quá khứ. Ở OpenLedger, giá trị của một contribution không được xác nhận tại thời điểm submit. Nó chỉ được xác nhận sau khi dữ liệu đó đi qua inference, được agent sử dụng, tạo ra tác động downstream. Và chính tác động đó mới là thứ quyết định reputation được giữ lại hay bị trừ.
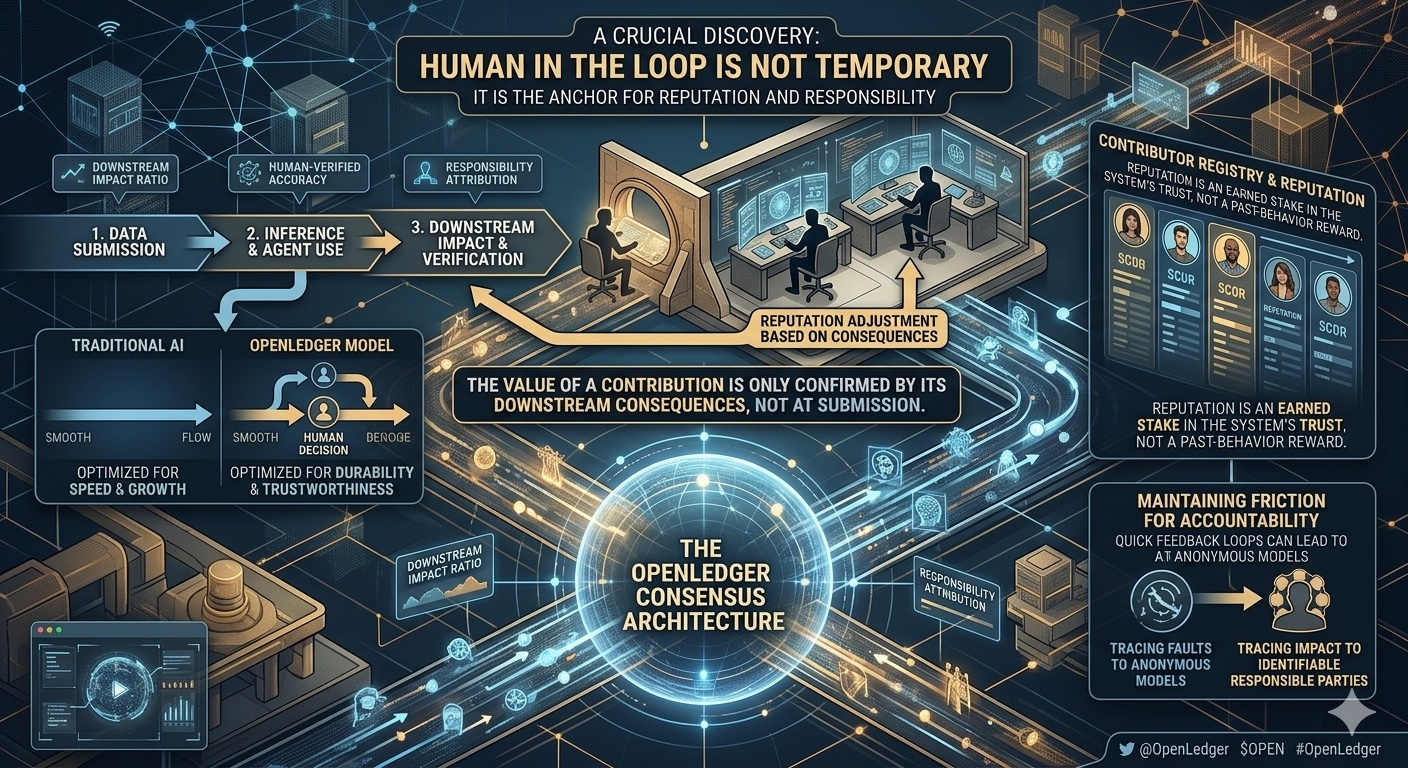
Chi tiết này rất quan trọng. Nó cho thấy OpenLedger không tin rằng chất lượng có thể được đánh giá hoàn toàn ở đầu vào. Họ tin rằng chất lượng chỉ lộ diện khi hệ thống đã vận hành, đã va vào thực tế, đã gây hệ quả. Và ở điểm đó, họ muốn có con người đứng ra chịu trách nhiệm, chứ không phải một metric vô danh.
Mình từng quen với cách các hệ AI khác làm việc. Dữ liệu được chấm điểm dựa trên format, consistency, statistical signal. Model chạy. Output đẹp. Nhưng khi output đó dẫn tới một quyết định sai, rất khó truy ngược lại ai chịu trách nhiệm. Mọi thứ tan vào “mô hình”. OpenLedger cố tình không cho phép điều đó xảy ra một cách trơn tru.
Trong các bản cập nhật testnet, có những con số không hề dễ chịu. Một phần đáng kể contribution bị đánh giá là low downstream impact sau khi agent sử dụng. Những con số này không được đưa lên headline. Nhưng chính việc họ giữ lại những số liệu làm narrative kém long lanh cho thấy họ đang tối ưu cho độ bền, không phải cho cảm giác tăng trưởng nhanh.
Giữ con người trong vòng lặp như vậy tạo ra một hiệu ứng rất khác về incentive. Khi reputation gắn với hậu quả thực, hành vi đóng góp thay đổi. Không còn động lực ném dữ liệu cho đủ số. Không còn cảm giác “đóng góp xong là hết trách nhiệm”. Con người ở đây không phải người kiểm duyệt hình thức. Họ là người gắn danh tiếng của mình với kết quả mà AI tạo ra.
Dĩ nhiên, cái giá phải trả là ma sát. Validation chậm hơn. Phản hồi reputation không tức thì. Scale không mượt như pipeline fully autonomous. Nhưng đổi lại, hệ thống có một thứ rất hiếm trong AI infrastructure hiện nay. Khả năng truy ngược trách nhiệm khi mọi thứ đi chệch.
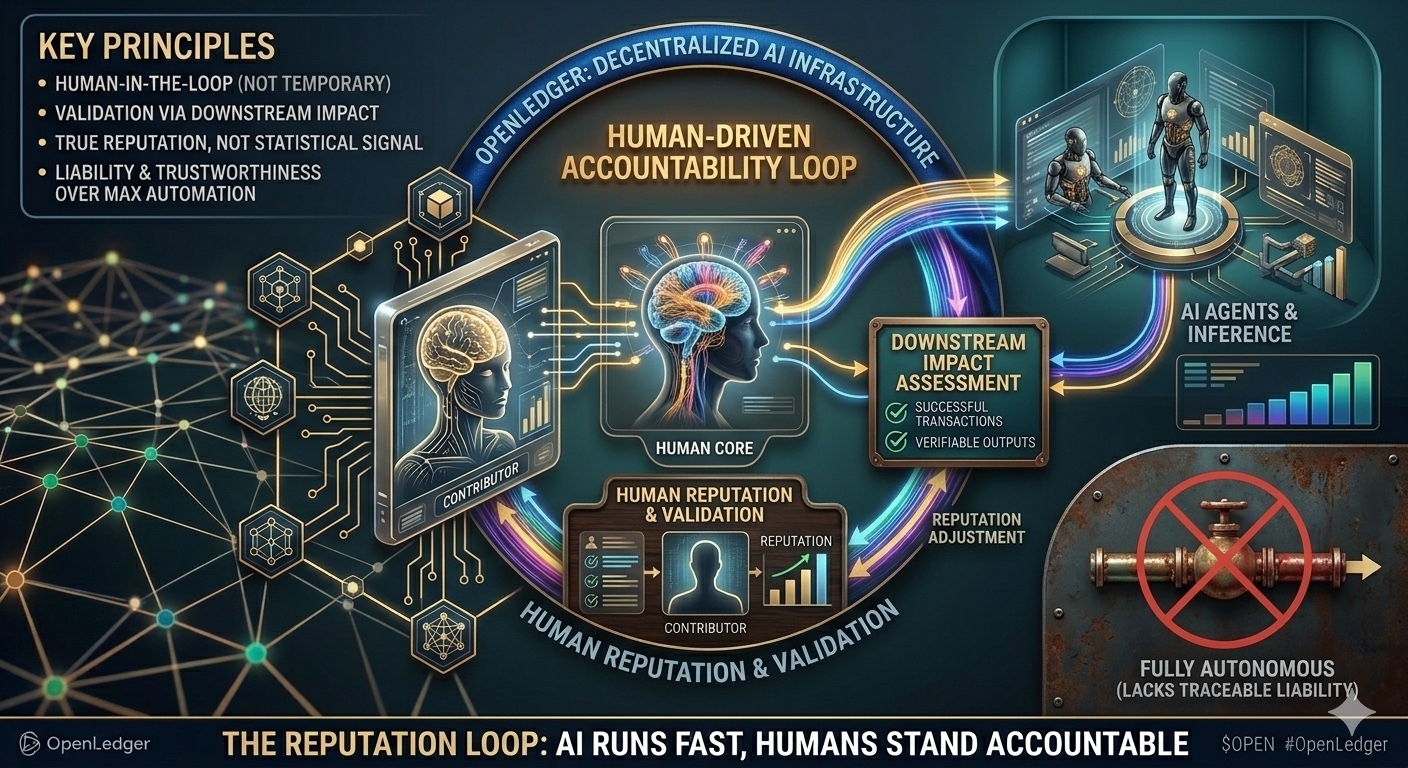
So với các mô hình machine-to-machine, nơi con người chỉ còn là operator đứng ngoài, OpenLedger giữ con người như một tác nhân nội tại. AI chạy nhanh. Rất nhanh. Nhưng quyết định để output đó tiếp tục được tin cậy hay không vẫn cần người đứng ra gắn tên. Cảm giác này giống một phòng biên tập hơn là một dây chuyền tự động. Nội dung được xuất bản không chỉ vì đủ điều kiện kỹ thuật, mà vì có người chịu trách nhiệm nếu nó gây hậu quả.
Tất nhiên, giữ con người không phải không có vấn đề. Con người mang theo thiên lệch. Mang theo cảm xúc. Mang theo khả năng collusion và gatekeeping. Reputation nếu không được giám sát tốt có thể trở thành quyền lực mềm. Những contributor mới có thể cảm thấy khó tiếp cận nếu hệ thống đánh giá bị capture. OpenLedger không phủ nhận những nguy cơ đó. Họ chấp nhận chúng như một phần của lựa chọn kiến trúc.
Điểm mình đánh giá cao là họ không cố gắng giải quyết mâu thuẫn này bằng lời hứa hay governance đẹp đẽ. Họ để mâu thuẫn tồn tại. Permissionless tới đâu thì bắt đầu va vào trách nhiệm. Tự động hóa tới đâu thì phải có người đứng ra chịu hậu quả. Human-in-the-loop ở đây không được mô tả như thứ sẽ bị tối ưu hóa rồi biến mất. Nó là điểm neo để hệ thống không trôi quá xa khỏi tác động thực.
Có thể OpenLedger sẽ trả giá. Nếu thị trường ưu tiên tốc độ hơn độ tin cậy. Nếu developer muốn một nền tảng ít ràng buộc hơn. Khi đó, giữ con người trong vòng lặp có thể trở thành điểm yếu cạnh tranh. Nhưng nếu bỏ lớp này đi, toàn bộ câu chuyện về trustworthy AI infrastructure sẽ mất nền để đứng ngay khi có một failure lớn đầu tiên.
Mình không đọc OpenLedger như một dự án hoài nghi AI. Ngược lại. Mình đọc nó như một dự án hiểu rất rõ sức mạnh của AI, nên mới cẩn trọng với hậu quả của nó. Khi AI bắt đầu can thiệp trực tiếp vào tài sản, vào quyết định tài chính, vào hành vi người dùng, thì sai lệch không còn là chuyện kỹ thuật. Nó là chuyện niềm tin.
Con người được giữ lại không phải vì hệ thống chưa đủ tốt. Mà vì hệ thống, nếu đủ mạnh, thì càng cần có người đứng ra chịu trách nhiệm. Không phải giải pháp tạm thời. Mà là một lựa chọn kiến trúc. Và nếu nó đúng, nó sẽ không tạo ra cảm giác trơn tru. Nó chỉ tạo ra cảm giác đáng tin hơn, theo một cách rất khó để quảng bá.