Most of the time, AI is discussed from the user’s side.
What can it write?
What can it answer?
How fast is it?
How much cheaper does it make a task?
That is understandable. The user sees the result first. A clean answer, a generated image, a finished report, a working agent. It all feels like the front door of AI.
But there is another side that feels less visible.
Who gets to supply the pieces behind it?
That question matters more than it first appears.
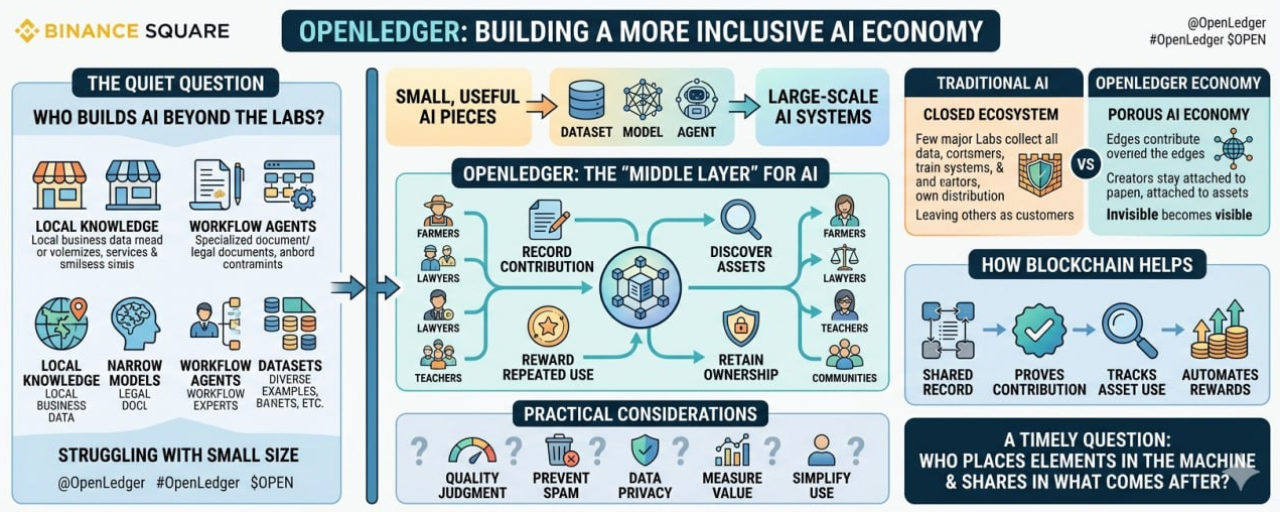
OpenLedger can be looked at from this angle. Not only as an AI blockchain, and not only as a system for monetizing data, models, and agents. More as a possible opening for people who are not sitting inside the largest AI companies, but still have something useful to contribute.
Because useful AI does not always begin in big labs.
Sometimes it begins with a small dataset that only a local business understands. Sometimes it is a narrow model trained around one type of document. Sometimes it is an agent built by someone who knows a workflow deeply because they have done that work for years. Sometimes it is a collection of examples, labels, corrections, or patterns that would look ordinary to outsiders, but becomes valuable in the right setting.
The problem is that these pieces often do not have a clear path into the wider AI economy.
They are too small to become platforms.
Too specific to attract broad attention.
Too valuable to give away.
Too hard to price.
Too hard to track once someone else uses them.
So they sit in between.
Not useless. Not fully active either.
That middle space is where OpenLedger starts to feel relevant.
It seems to be asking whether data, models, and agents can behave more like usable assets without needing to be absorbed by one large company. Can a small team make a dataset available without losing control of it? Can a model builder earn from repeated use instead of selling the model once? Can an agent become part of a larger network of work, instead of staying trapped inside one product?
These are not loud questions, but they are important.
Because AI could easily become another closed economy.
A few companies collect the most data, train the strongest systems, own the distribution, and decide which tools get used. Everyone else becomes either a customer or a supplier with little bargaining power. That path is familiar. We have seen it with search, social platforms, app stores, cloud services, and creator platforms.
The pattern is not always intentional. It just happens when the middle layer is missing.
OpenLedger seems to be working on that middle layer.
A place where AI inputs can be recorded, discovered, and rewarded. A place where ownership does not have to disappear the moment an asset becomes useful. A place where smaller contributors might have some way to stay attached to what they created.
That does not mean everything becomes equal. It does not mean small contributors suddenly compete with major labs. That would be too neat, and probably not true.
But it may change the terms a little.
Instead of needing to build a full AI company, someone could contribute one useful layer. Instead of needing to own the entire application, they could provide the dataset or model that improves it. Instead of being invisible in the background, their asset could have a record of use.
That is a quieter kind of participation.
And maybe that is what makes it interesting.
AI is becoming too broad for one kind of builder. The best systems may need domain experts, data owners, model creators, agent developers, evaluators, and application builders. Not all of them will look like traditional software founders. Some may simply hold knowledge that has not been turned into a product yet.
OpenLedger’s role, if it works, is to make that knowledge easier to activate.
The word “monetize” can sound cold, but underneath it is a more human issue. People want to know that if their work makes something better, they are not completely erased from the value chain. A farmer’s crop dataset, a lawyer’s document patterns, a teacher’s learning material, a local language community’s examples — these things can train and improve AI systems. But without structure, they can also vanish into them.
That is the uncomfortable part.
AI needs inputs. It always has. The question is whether those inputs are treated as disposable fuel or as assets with ongoing identity.
OpenLedger seems to lean toward the second view.
Blockchain helps because it can keep a shared record. Not every record solves a problem. Not every token creates value. But in a network where many independent contributors are involved, a common record can reduce confusion. It can show who contributed what, how it was used, and where rewards should flow.
Still, this will not be easy.
There are practical questions everywhere. How do you judge the quality of a dataset? How do you stop low-effort assets from flooding the network? How do you protect private information? How do you measure whether one model or agent truly added value? How do you make the system simple enough that non-technical contributors can use it?
Those questions may decide more than the idea itself.
Because participation only expands when the process feels understandable. If OpenLedger is too complex, it risks becoming useful only to the same technical crowd that already knows how to navigate these systems. But if it becomes simple enough, it could open a door for a wider group of contributors.
That is the angle worth sitting with.
OpenLedger is not just about AI becoming more powerful. It is about whether the AI economy can become more porous. Whether useful pieces can enter from the edges. Whether smaller creators of data, models, and agents can have a place before everything is gathered into a few large systems.
No one knows yet how far that can go.
But the question itself feels timely.
As AI keeps growing, it will not only matter what the machines can do. It will also matter who gets to place something inside the machine, keep a trace of it there, and share in what comes after.