I’m watching OpenLedger (OPEN) the way I watch most new crypto experiments: quietly, from a distance, trying to understand whether what I’m seeing is early momentum or just early noise. The token is still in that phase where the price and supply numbers move around enough that they feel more like estimates than certainties. Trading activity is noticeable, sure, but it’s the kind of activity I treat as a signal to start paying attention—not a signal that anything is proven yet.
OpenLedger — built by OpenLedger — isn’t positioning itself as another “general-purpose blockchain.” If anything, it’s trying to build a very particular type of infrastructure: rails for AI data, models, and agents to become measurable economic goods instead of abstract inputs floating around in someone’s GPU cluster.
Their website,
,
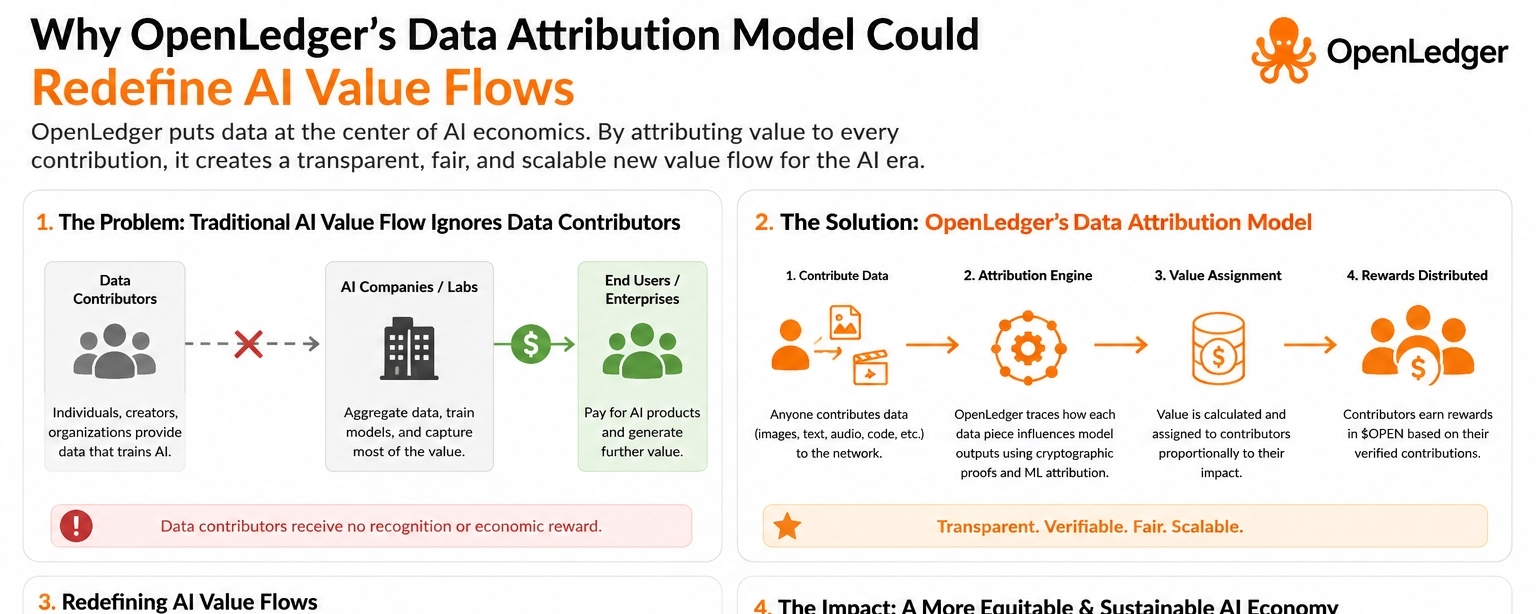
frames the whole idea as “unlocking liquidity for AI,” but what they’re really talking about is making AI contributions traceable the same way royalties or supply chain steps are traceable. Their documentation goes deeper into this, describing a system of “Datanets”—basically structured data ecosystems—and something called Proof of Attribution, which is meant to show who contributed what and how much it mattered.
I find that idea interesting not because it’s technical, but because it touches a real-world problem: AI today is extremely opaque. You don’t really know where the data came from. Contributors don’t know if their work improved anything. Users don’t know which inputs shaped the outputs they’re seeing. Everything blends into one big model, and the economic story disappears.
OpenLedger is trying to flip that. Not perfectly, not seamlessly, and certainly not instantly—but at least in intention. If it works, it could make the AI ecosystem behave more like a functioning market and less like a mystery box.
Still, there’s always a gap between what a protocol wants to become and what networks actually do in their early months.
The common pitfalls are already visible on the horizon.
People could try to flood the system with low-value data just to earn rewards. Developers might integrate the rails at a surface level without routing any meaningful workloads through them. Attribution metrics—no matter how elegantly described—can be fragile, especially if attackers figure out what counts as a “valuable contribution.”
And of course, markets have a habit of discovering price long before utility. OPEN trades across many exchanges, including large venues like Binance, accessible at:
,
so the liquidity footprint looks respectable for something this early. Data platforms like CoinGecko () and CoinMarketCap () show decent volume and shifting market cap, but these numbers mostly tell me that people are trading it—not why.
So I end up focusing on the quieter, less flashy signs:
Are people actually uploading meaningful data to these Datanets?
Is attribution giving results that match reality, not just dashboards?
Are developers training or deploying models here for reasons other than incentives?
Does activity keep happening after the marketing cycle moves on?
If OpenLedger can produce real answers to those questions, it could end up being one of those networks that quietly becomes infrastructure over time—like a highway you eventually forget was once new. But if the usage turns out to be thin or the attribution unverifiable, then the whole system becomes another ambitious idea that stayed theoretical.
So for now, I’m watching—not for the price candles or exchange listings, but for the slow accumulation of evidence. Crypto projects don’t become durable because they launched loudly. They become durable when people keep using them long after the noise fades. That’s the story I’m waiting to see with OpenLedger: not what it claims it can do, but whether the chain shows proof that it’s actually happening.