Îmi amintesc zilele Axie Infinity..... toată lumea spunea că e o nouă economie, dar sub toată acea entuziasmare era un castel de nisip construit pe pomparea token-urilor. Când OpenLedger spune că contribuitorii vor câștiga din taxele de inferență, întreb aceeași întrebare veche. E structura într-adevăr diferită de data aceasta?🤔
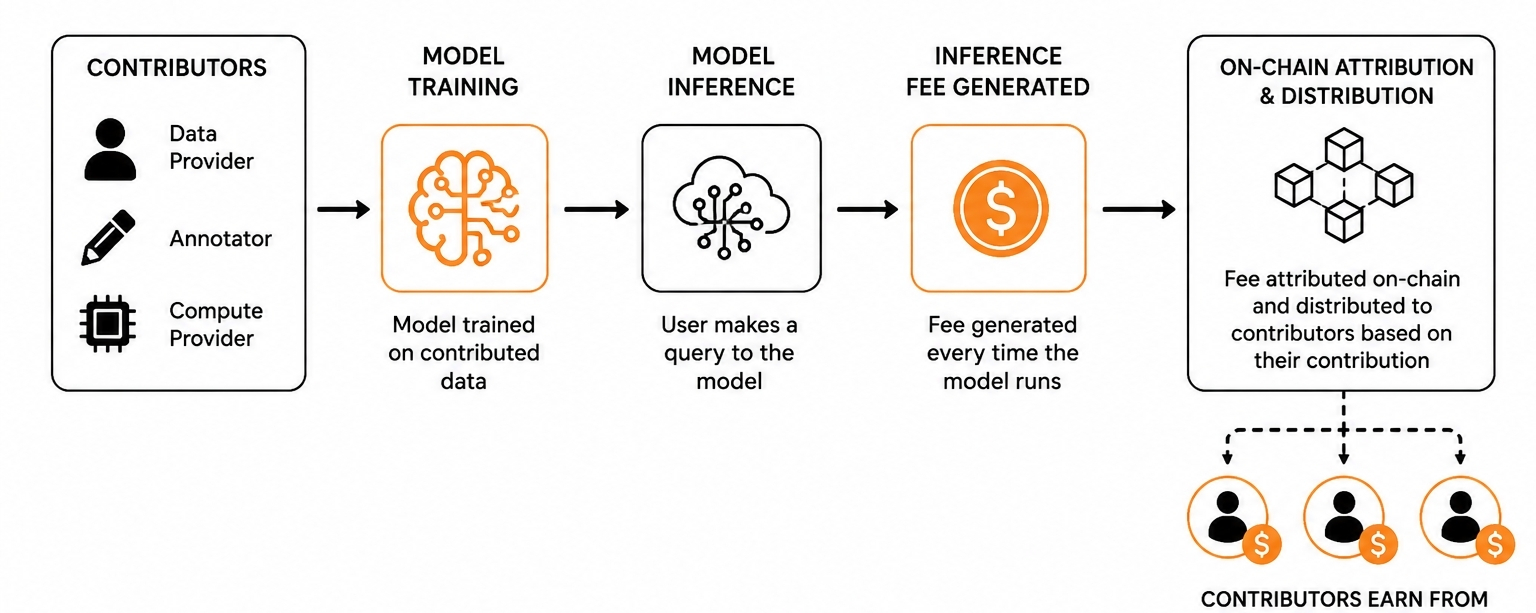
Aici e ce m-a deranjat la fiecare proiect înainte de acesta. Vin la tine pentru datele tale, pentru notările tale, pentru tiparele tale de comportament, pentru puterea ta de calcul. Le oferi. Modelul se antrenează. Modelul rulează. Oamenii plătesc să-l folosească. Și undeva în această lanț de plăți, se generează o taxă de fiecare dată când modelul procesează o interogare. Acea taxă merge către platformă. Contribuitorul primește o plată unică, poate o alocare de token-uri, poate nimic deloc. Fluxul de venituri continuu pe care contribuția ta l-a făcut posibil? Nu-l mai vezi niciodată.😤
Aceasta este problema structurală pe care majoritatea proiectelor Web3 AI o ocolesc în tăcere. Ele rezolvă problema "cum obținem date"..... nu problema "cum compensăm corect persoanele care au făcut produsul să funcționeze".
OpenLedger face ceva ce pare simplu, dar este de fapt mai greu de construit decât pare. De fiecare dată când un model antrenat pe datele tale rulează o inferență, se generează o taxă, iar acea taxă este atribuită înapoi contribuabililor ale căror date au modelat capabilitățile acelui model în particular. Atribuirea are loc pe blockchain, ceea ce înseamnă că nu este o promisiune care stă într-un registru intern al unei companii. Este un record verificabil. Acesta este primul punct solid meritat să fie luat în considerare, deoarece atribuirea la timpul de inferență, nu doar la timpul de antrenare, este o "alegere de design cu adevărat diferită."
Al doilea lucru pe care îl consider demn de examinat este unghiul de transparență pe blockchain. Cele mai multe modele de venituri AI sunt cutii negre chiar și atunci când companiile sunt tehnic "deschise". Te încrezi că taxa a fost generată, te încrezi în formula de distribuție, te încrezi în procentaj...... Abordarea OpenLedger face ca evenimentul de inferență să fie o tranzacție de urmat. Dacă implementarea se dovedește a rezista examinării este o întrebare separată, dar intenția de design contează deoarece schimbă ce înseamnă responsabilitatea în acest context.
Acum aici este locul unde încep să pun întrebări mai dificile.🧐 Modelul de taxare a inferențelor sună curat în teorie. Dar ce se întâmplă când un model este antrenat pe mii de contribuabili și o interogare de inferență atinge capabilități modelate de toți aceștia? Cum împarți atribuirea semnificativ între acea complexitate? Contribuitorul care a furnizat cel mai specializat, dar decisiv punct de date primește credit proporțional, sau sistemul împarte contribuțiile în medii brute? Aceasta nu este o rațiune pentru a respinge modelul...... Este exact întrebarea care determină dacă structura economică a OPEN rezistă cu adevărat la scară.
Al treilea punct este ceea ce mi-a atras cu adevărat atenția, pentru că OpenLedger susține, în esență, că contribuția de date este muncă, nu donație. Această reformulare are consecințe reale. Dacă datele sunt muncă, atunci taxa de inferență este salarii amânate până când produsul generează venituri. Acest lucru este mai apropiat de modul în care un muzician câștigă drepturi de autor din streamuri decât de modul în care un muncitor de fabrică își vinde timpul pentru o rată orară fixă. Modelul de drepturi de autor din muzică a durat decenii și a necesitat multe lupte legale pentru a fi corect. OpenLedger încearcă să construiască acest mecanism nativ în protocol încă din prima zi....
Al patrulea lucru la care mă întorc mereu este întrebarea despre ce înseamnă de fapt "contributor" în diferite etape. Contribuitorii timpurii care au ajutat la antrenarea modelor fundamentale au mai multă greutate în arhitectură decât contribuabilii ulteriori care au ajustat caracteristici mai mici. Modelul de taxare a inferențelor ține cont de această diferență temporală sau tratează toate contribuțiile ca fiind echivalente? Dacă un model antrenat acum doi ani rulează încă milioane de inferențe astăzi, persoanele care au contribuit la început ar trebui, teoretic, să câștige în continuare. Dacă acesta este modul în care OPEN distribuie efectiv, datele rețelei live ne vor spune în cele din urmă.
În al cincilea rând, punctul sceptic pe care nu pot să-l ignor...... este că acest model necesită ca OpenLedger să mențină un tip foarte specific de disciplină operațională în timp. Sistemele de atribuire sunt ușor de proiectat și ușor de erodat în tăcere. O companie aflată sub presiune financiară ar putea ajusta formula de împărțire a taxelor, redefini ce contează ca o inferență calificată sau pur și simplu încetini înregistrarea pe blockchain a evenimentelor. Integritatea pe termen lung a protocolului depinde de guvernanța fiind cu adevărat descentralizată, nu doar teoretic descentralizată, în timp ce o echipă de bază deține cheile decizionale.👀
Ceea ce găsesc cu adevărat interesant la OpenLedger nu este tokenul. Este întrebarea pe care o pune pe masă. Dacă un model AI câștigă bani de fiecare dată când gândește, iar datele tale l-au învățat să gândească, atunci ce ai vândut de fapt când ai contribuit cu acele date? O resursă unică..... sau dreptul de a participa continuu în viața comercială a acelui model?
Această întrebare nu are încă un răspuns clar. Dar faptul că OpenLedger construiește infrastructură în jurul ei, mai degrabă decât să ridice doar întrebarea într-un whitepaper, este motivul pentru care acord atenție, cu atenție.... NU
entuziasmat.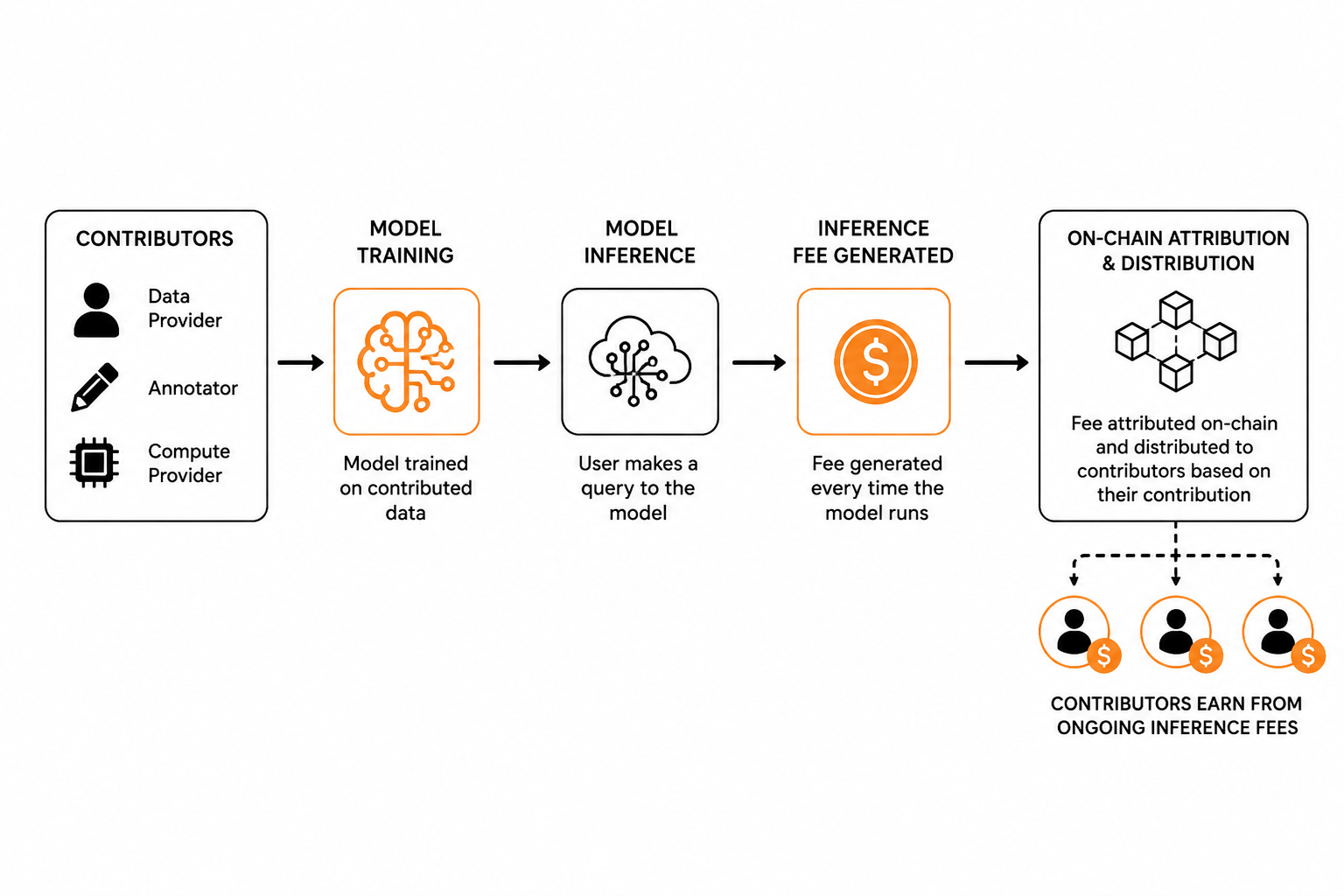
#OpenLedger #dyor @OpenLedger #CryptoVibes


