Nhiều người nhìn vào Roadmap năm 2026 của OpenLedger và thấy một bản danh sách dài về các cập nhật kỹ thuật: chín lớp kiến trúc, giải pháp OpenLoRA, hay cơ chế Proof of Attribution (PoA). Nhưng từ góc nhìn của một người trực tiếp vận hành hệ thống, mình nhận ra OpenLedger không đơn thuần là đang nâng cấp hạ tầng. Họ đang trả lời lại một câu hỏi chí mạng mà cả ngành AI lẫn Web3 đang né tránh: Ai sẽ chịu trách nhiệm kinh tế khi một AI Agent tự ra quyết định trên chuỗi?
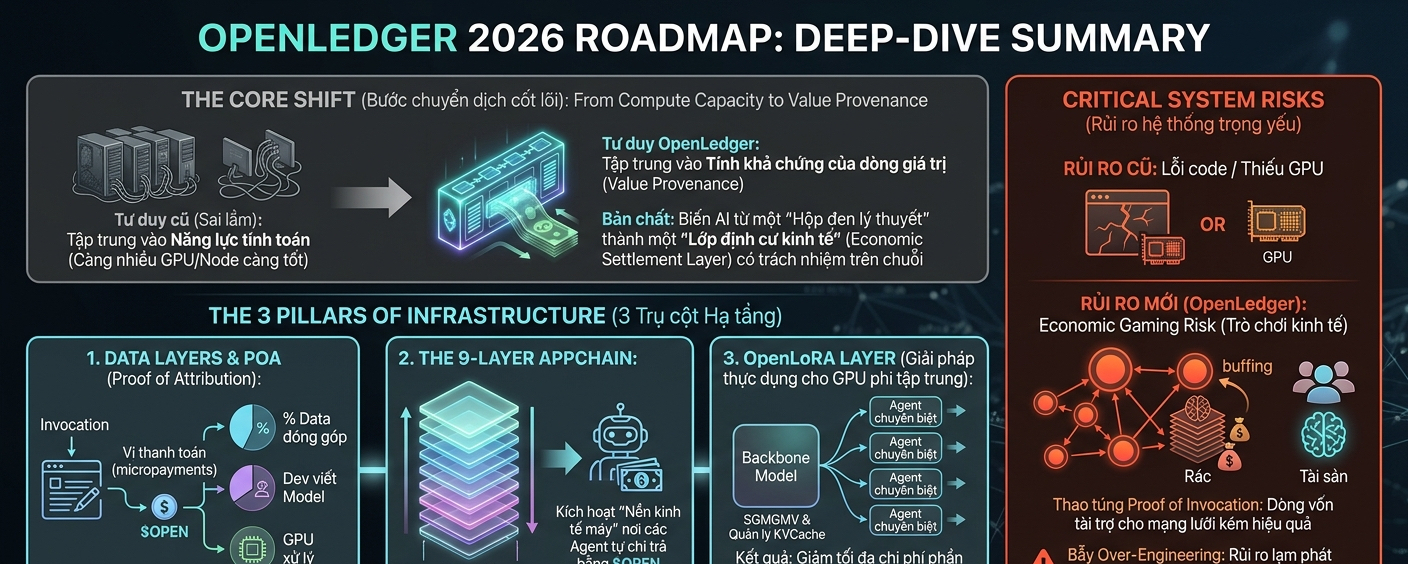
Trước đây, khi theo dõi các dự án AI phi tập trung (Decentralized AI), mình hay nghĩ nút thắt cổ chai nằm ở tốc độ tính toán của GPU hoặc chi phí băng thông dữ liệu. Cứ thêm nhiều node, tối ưu hóa phần cứng là xong. Nhưng khi nhìn vào cách OpenLedger chuyển dịch lộ trình từ năm 2025 sang năm 2026, mình thấy họ đã nhận ra vấn đề không nằm ở "năng lực tính toán" (compute capacity), mà nằm ở "tính khả chứng của dòng giá trị" (value provenance).
Trong mô hình AI truyền thống, dữ liệu được nạp vào một chiếc hộp đen. Bạn trả tiền cho kết quả đầu ra (inference), nhưng bạn hoàn toàn mù tịt về việc phần tiền đó sẽ được chia lại cho ai—nhà phát triển mô hình, người đóng góp dữ liệu sạch, hay chủ sở hữu GPU? Toàn bộ chuỗi cung ứng này vận hành dựa trên sự độc quyền và bất đối xứng thông tin.
Bản cập nhật kiến trúc 9 lớp của OpenLedger trong năm nay đang thay đổi chính xác cái primitive gốc này.
Điểm cốt lõi nằm ở cách họ hiện thực hóa cấu trúc Datanets và Proof of Attribution (PoA). Hãy nghĩ về nó như một bộ khung kế toán tự trị (Autonomous Accounting). Khi một thực thể—có thể là con người hoặc một AI Agent khác—gọi một câu lệnh (invocation), hệ thống không chỉ trả về kết quả. Trước khi execution xảy ra, lớp PoA sẽ phân rã lệnh đó để truy vết ngược lại: kết quả này được cấu thành từ bao nhiêu % dữ liệu của kho Data ngách nào, chạy trên mô hình của dev nào, và được xử lý bởi cụm GPU nào của bên thứ ba (như io.net hay Aethir).
Hệ thống biến toàn bộ quá trình suy luận vốn tĩnh lặng của AI thành một chuỗi các vi thanh toán (micropayments) chạy bằng $OPEN. Tức là, OpenLedger không còn là một sổ cái để ghi chép lịch sử giao dịch nữa. Nó trở thành một Lớp định cư kinh tế (Economic Settlement Layer) cho các thực thể AI.
Nhìn từ thực tế vận hành, điều này kéo theo một giải pháp kỹ thuật rất thực dụng trong roadmap của họ: OpenLoRA.
Nếu ai đã từng thử chạy các mô hình ngôn ngữ lớn (LLM) trên mạng lưới node phi tập trung đều biết đó là một cơn ác mộng về độ trễ và chi phí. Bạn không thể bắt hàng ngàn node tính toán đồng bộ một mô hình hàng trăm tỷ tham số trong vài mili-giây. OpenLedger xử lý điều này không phải bằng cách "ước gì có phần cứng mạnh hơn", mà bằng cách thay đổi cấu trúc chia sẻ tài nguyên.
Với việc tích hợp thuật toán SGMV và quản lý KVCache, họ cho phép nhiều Agent chuyên biệt khác nhau chia sẻ chung một mô hình nền tảng (backbone model) trên cùng một cụm GPU mà không làm suy giảm hiệu năng. Nghĩa là, hệ thống đưa toàn bộ sự phức tạp về mặt phần cứng xuống tầng dưới, giải phóng các nhà phát triển khỏi áp lực hạ tầng để họ chỉ tập trung vào việc tinh chỉnh (fine-tuning) các Agent phục vụ mục đích chuyên biệt.
Nhưng thiết kế này cũng đặt ra một hệ quả rủi ro hệ thống (System Risk) hoàn toàn mới mà trader hay nhà đầu tư cần phải ý thức rõ.
Trong cấu trúc Tokenomics mới của $OPEN, việc bắt buộc các Nhà cung cấp dữ liệu (Data Providers) phải staking token để bảo chứng cho chất lượng dữ liệu sạch tạo ra một áp lực khóa cung (supply lock) rất tốt. Tuy nhiên, nó dịch chuyển rủi ro từ "lỗi code" sang "rủi ro trò chơi kinh tế" (Economic Gaming Risk).
Nếu cơ chế tính toán tần suất gọi bằng chứng (Proof of Invocation) hoặc hệ thống giám sát chất lượng dữ liệu bị thao túng bởi các liên minh Node lớn, hệ thống sẽ tự động phân phối phần thưởng cho các mô hình "rác" nhưng có lượng tương tác ảo cao. Trên lý thuyết hệ thống vẫn execute chính xác, token vẫn được đốt và thưởng đúng logic, nhưng về mặt ngữ nghĩa kinh tế, dòng vốn đang tài trợ cho một mạng lưới kém hiệu quả.
Roadmap năm 2026 của @OpenLedger cho thấy một thông điệp rất rõ ràng: Kỷ nguyên của việc "bán câu chuyện AI phi tập trung" đã kết thúc. Dự án đã chuyển hẳn sang giai đoạn "bán hiệu năng thực tế".
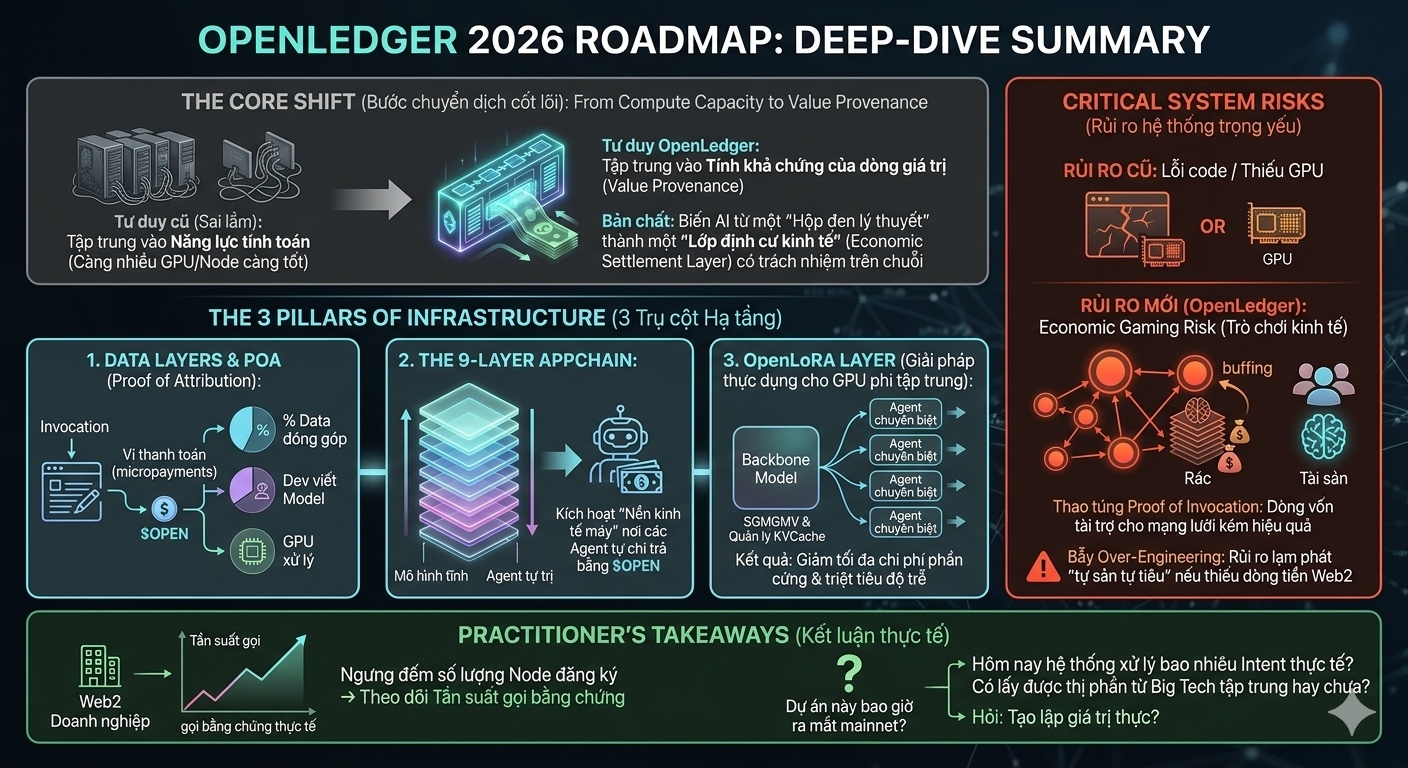
Thứ chúng ta cần quan sát trong các quý tới không phải là số lượng node đăng ký mới (vốn rất dễ tạo hype), mà là tần suất gọi bằng chứng thực tế từ các doanh nghiệp Web2. Nếu dòng tiền từ thế giới thực không vào để tiêu thụ nguồn cầu của $OPEN , thì cấu trúc 9 lớp phức tạp kia cũng chỉ là một hệ thống over-engineering tự vận hành trong không gian trống rỗng.
Chúng ta không còn bắt đầu một ngày bằng việc tự hỏi "Dự án này bao giờ ra mắt mainnet?", mà phải hỏi: "Hôm nay, hệ thống này đã xử lý bao nhiêu intent thực tế từ thị trường, và liệu nó có đang thực sự dịch chuyển cấu trúc quyền lực từ các Big Tech tập trung về tay mạng lưới phi tập trung hay không?"