

I keep coming back to a small, uncomfortable question around AI: where did the answer learn its voice?
Not the model name. Not the company logo. Not the neat box where the response appears. I mean the buried trail underneath it. The forum post, the research note, the image caption, the niche dataset, the expert correction, the quiet human labor that becomes invisible once a model starts speaking fluently. Most AI systems make that disappearance feel normal. OpenLedger’s idea of tracing data origins for model training seems to push against that normality.
The project’s docs describe OpenLedger as infrastructure for training and deploying specialized models using community-owned datasets called Datanets, where uploads, model training, reward credits, and governance actions are executed on-chain. That framing matters because it treats training data less like loose raw material and more like something with memory attached to it. A dataset is not just “used.” It is registered, attributed, and carried forward with metadata. OpenLedger’s Data Attribution Pipeline says data contributors submit structured, domain-specific datasets for AI model training, and each dataset is attributed on-chain for transparency and verification. 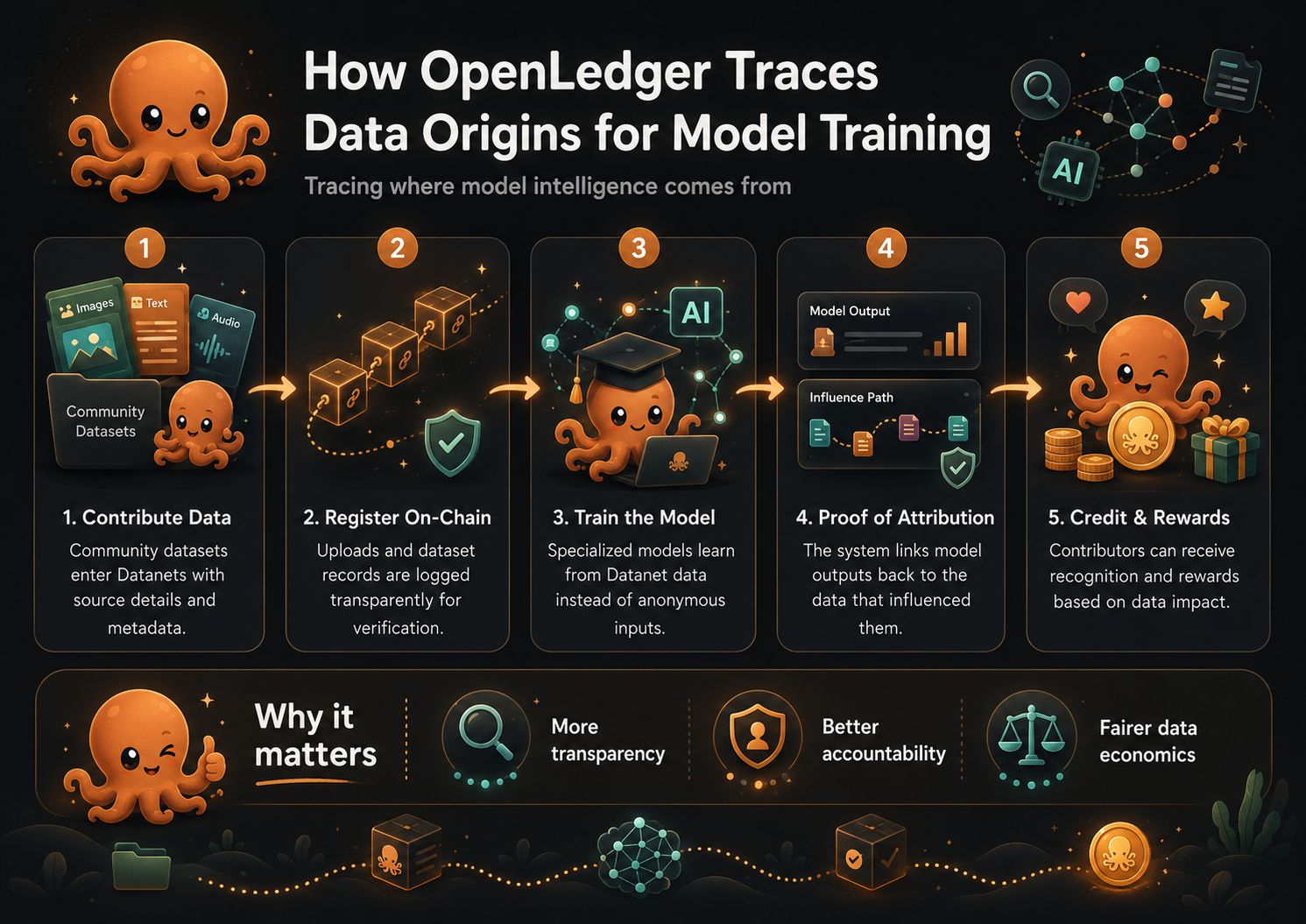
That sounds clean on paper. Reality is not clean.
Data is messy. It overlaps. It gets copied, edited, translated, summarized, remixed, and sometimes poisoned. The hard part is not saying “we value contributors.” Anyone can say that. The hard part is building a system that can still identify influence after training has turned thousands or millions of inputs into statistical behavior. OpenLedger’s Proof of Attribution paper tries to address that gap directly. It says models log training provenance through DataNets, allowing deterministic tracking of which datasets contributed to a model version, and it proposes different attribution methods for small and large models.
This is where the title becomes interesting to me. “How OpenLedger Traces Data Origins for Model Training” is not really about a database feature. It is about refusing to let AI pretend it arrived from nowhere.
The usual AI pipeline feels like a room with no windows. Data goes in. A model comes out. Then people argue afterward about copyright, bias, ownership, accuracy, and compensation. By then, the trail is already blurred. OpenLedger appears to be trying to move the receipt closer to the beginning. When a contribution enters a Datanet, it carries identity, metadata, and intended use. During training and later inference, the system is designed to measure which data had influence, record that influence, and connect it back to contributors. Its docs describe influence scores, training logs, and rewards based on the impact of contributions on model outputs.
I like the ambition because it answers a real discomfort. Not every useful AI contribution looks like code. Sometimes the valuable thing is a clean dataset, a specialized archive, a corrected label, or knowledge from a small community that big models usually flatten into anonymity. If OpenLedger’s system works as described, origin becomes part of the model’s life rather than an afterthought.
But I would not call this solved. Attribution in AI is not the same as tracing a wallet transaction. A model does not “remember” every source in a simple human way. Influence can be approximate, uneven, and context-dependent. OpenLedger’s own paper reflects that by discussing different approaches, including influence-based methods and token-level tracing for larger language models. That tells me the system is not magic; it is an attempt to make a difficult problem measurable enough to become auditable. 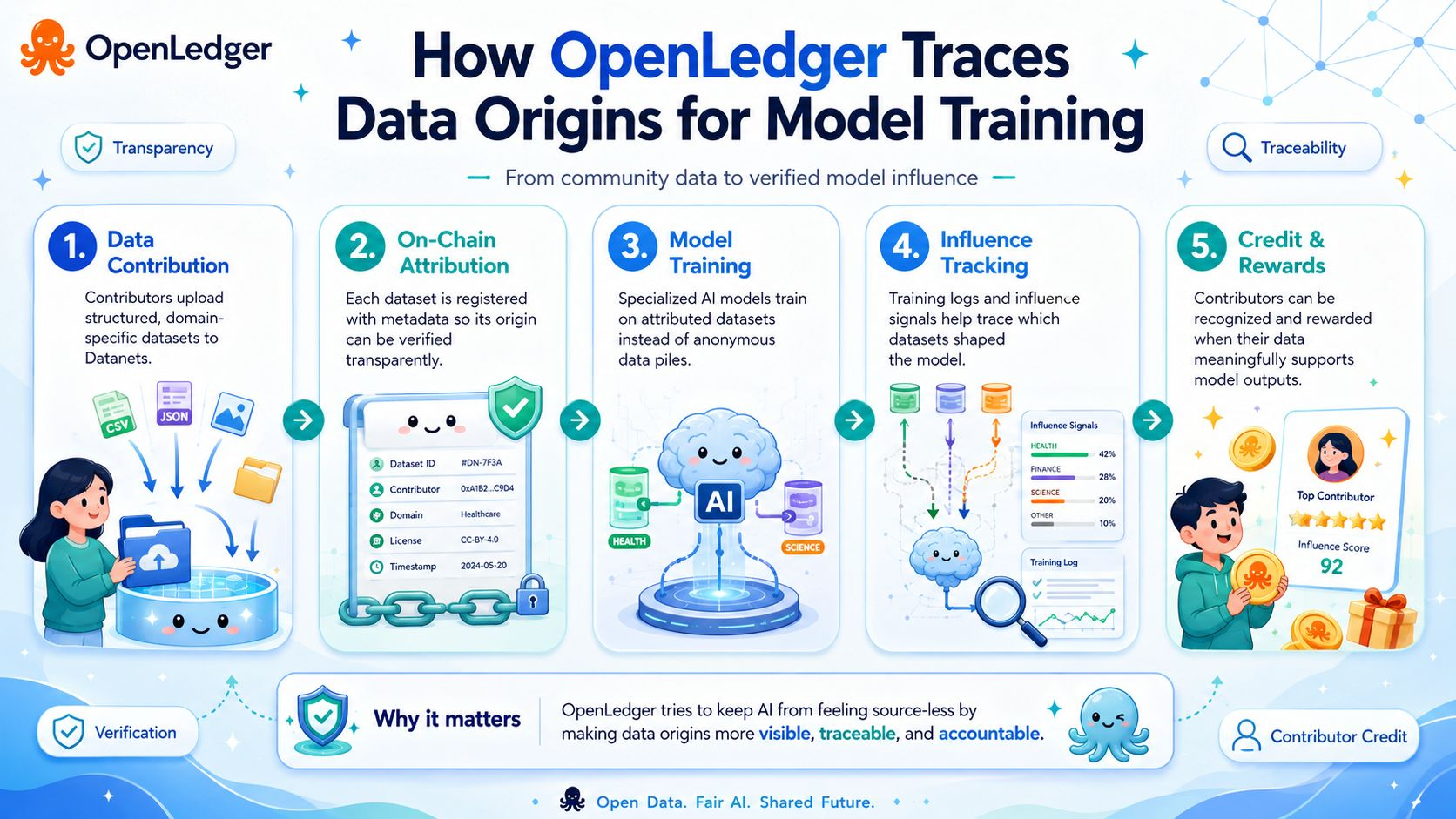
The better way to see OpenLedger, then, is not as a promise that every AI answer will suddenly become perfectly fair. It is more cautious than that. It is an effort to build a culture of receipts into model training. Who contributed? What was used? Which dataset mattered? Who deserves credit when value is created?
Maybe the real test will not be whether OpenLedger can describe this elegantly. It already can. The test will be whether contributors, developers, and model users keep caring about origins once the output becomes useful, fast, and profitable.
That is usually when people stop asking where things came from. OpenLedger is betting that, in AI, we may finally need to start.

