

E o ironie ciudată în discuțiile noastre despre Web3 și AI. Pe hârtie, lăudăm atribuția curată a AI-ului și proprietatea corectă a datelor. Dar realitatea de pe teren este destul de haotică. Dacă datele tale originale au fost folosite pentru a antrena un model AI masiv, cum îți poți recupera drepturile financiare fără un conflict lung și obositor? Aceasta este diferența practică pe care trebuie să o rezolvăm. Și exact aici, sistemul @OpenLedger oferă o utilitate reală.
Ca un cercetător experimentat în Web3, studiez întotdeauna profund whitepapers și protocoale. Abordarea mea este foarte simplă și fundamentată, fără hype gol, doar o recenzie adevărată, valoroasă și transparentă. Așadar, haideți să înțelegem astăzi#OpenLedger filozofia și mecanismele sale de bază în termeni simpli, ca un profesor. Să le descompunem într-un format direct de întrebări și răspunsuri astfel încât aspectele tehnice complexe să devină complet clare. Aici sunt câteva întrebări despre$OPEN despre care vom afla........ să începem.......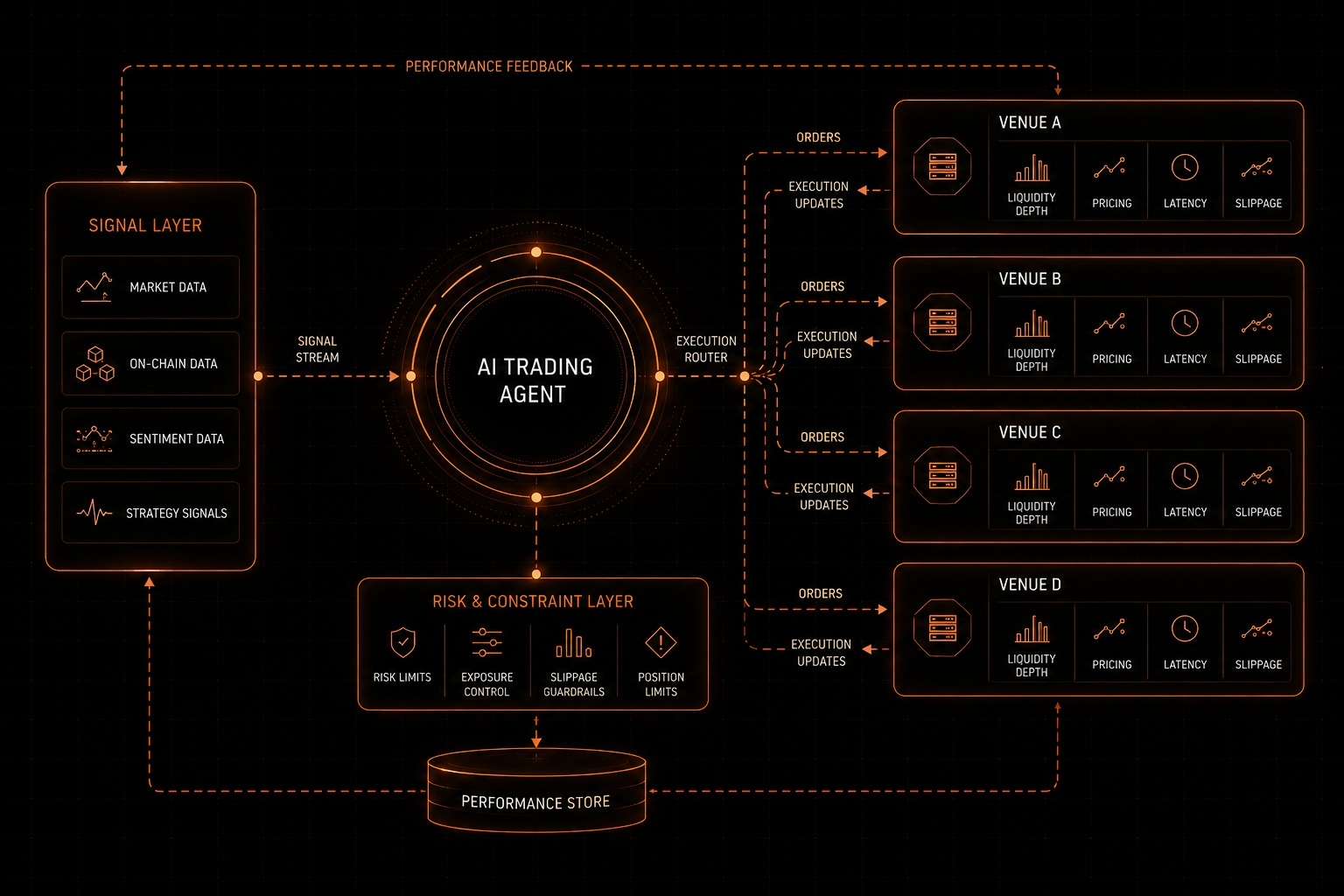
Ce este OpenLoRA exact și cum funcționează mecanismul său de servire a modelului cost-eficient?
Antrenarea continuă și ajustarea modelelor AI este un proces tehnic greu și practic foarte costisitor. OpenLoRA este practic un mecanism care oferă dezvoltatorilor libertatea de a servi modele într-un mod cost-eficient, fără a avea nevoie de resurse centralizate masive. Acesta îi ajută pe dezvoltatori să ruleze modele AI specializate cu mai puțin cod și costuri optimizate. Gândește-te la el ca la un motor inteligent, ușor, care face munca grea, dar fără a consuma combustibil inutil.
Ce rol joacă Zero-Knowledge Proofs (ZKPs) în AI? Oare OpenLedger chiar gestionează în mod securizat inferența AI privată?
Da, frate, absolut. Când vine vorba de adoptarea AI la nivel de întreprindere, confidențialitatea datelor devine cea mai mare obstacol. Companiile mari nu doresc să își hrănească modelele AI deschise cu date sensibile. ZKPs permit aici ca inferența AI să fie complet verificabilă, fără a expune datele confidențiale originale în fața lumii. Asta înseamnă că întreprinderile pot realiza o verificare de încredere, în mod securizat. OpenLedger folosește această dovadă pentru a asigura că datele rămân private și ieșirea modelului AI este fiabil verificabilă.
Acum să discutăm despre cadrul real al acestui ecosistem pur.
Aici intervine logica Open Consensus. Această rețea descentralizată asigură că toate contribuțiile AI sunt validate fără o autoritate centrală. Niciun gigant tehnologic nu va decide singur într-o cameră închisă cât de valoroase au fost seturile de date.
Dar, să fiu sincer, doar a valida deschis nu este suficient. Avem nevoie de o memorie rigidă, indestructibilă, pe care o numim Proveniență a Datelor Immutabile. Acest protocol deschis urmărește cu atenție exact ce date brute au fost utilizate atunci când s-au creat modelele AI și asigură că această istorie nu poate fi niciodată schimbată sau manipulată.
Încerc să înțelegem asta cu un exemplu din lumea reală.
Să presupunem că ești un scientist de date independent sau un artist care a creat un set de date foarte precis și specializat. O mare companie AI a făcut scraping global de date pentru a-și antrena noul model, inclusiv setul tău de date. În lumea Web2 normal, nu vei primi niciodată credit sau un ban. Dacă revendici, va dura ani de zile în instanță. Dar pe rețeaua OpenLedger, proveniența acestor date va fi înregistrată permanent pe blockchain, arătând că datele tale exacte au fost folosite în acel model AI.
Când istoria și proveniența transparentă devin complet clare, atunci atribuirea antrenării modelului AI începe să ofere recunoașterea corectă contributorilor de date originale.
Așadar, cum putem face toate aceste lucruri în final acționabile financiar?
Aici este punctul de cotitură unde tokenomics își arată magia. Dacă proveniența datelor imutabile este memoria și adevărul, atunci tokenul OPEN este acel instrument puternic care transformă aceste revendicări în realitate.
Utilitate și integrarea EVM:
Tokenul OPEN nu este un jargon complex dintr-un whitepaper sau doar un nume fancy. Este motorul financiar al întregului sistem. Sistemul nu doar că urmărește cine a contribuit cu ce date, dar recompensează efectiv contributorii pentru munca lor. Când rețeaua de atribuție se dovedește, smart contracts distribuie automat plăți corecte. Fără certuri, fără intermediari, doar reguli clare și recompense transparente. Și pentru că OpenLedger este complet compatibil cu Ethereum (EVM), întreprinderile și dezvoltatorii Web3 pot integra inteligent portofelele și smart contracts existente cu ușurință.
De ce acum - De ce este important acum?
Cred cu tărie că atribuirea fără gestionarea conflictelor este doar un hobby. Dacă urmărești inteligent cine a contribuit cu ce, dar nu poți soluționa automat disputele financiare pe baza acestora, atunci sistemul tău nu va fi practic viabil comercial. Cu venirea OpenLedger, această infrastructură devine exact un strat de conflict financiar citibil de mașină, unde codul face singur justiția. Nu este o narațiune pe termen scurt de piață bullish sau o hype, ci blocuri fundamentale absolute pentru sustenabilitatea AI în întreprinderi pe termen lung. Semnalele pe care le așteptăm pentru integrarea în utilizare reală și fluxuri de lucru zilnice încep aici.
Mi se pare că în era AI viitoare, datele nu vor fi doar combustibil, ci o clasă de active financiare.
Ultima întrebare pentru tine
Pe măsură ce modelele AI devin din ce în ce mai dependente de datele noastre proprietare și de munca umană, este industria noastră pregătită să gestioneze aceste dispute masive de influență AI în mod complet transparent și pe blockchain?