
Có một thời điểm tôi dành khá nhiều thời gian quan sát các hệ thống trong mảng AI và hạ tầng dữ liệu, đặc biệt là các mô hình liên quan đến crypto infrastructure.
Sáng ngày hôm nay, tôi ngồi khoảng hơn 1 giờ để rà lại dữ liệu từ 4 luồng hoạt động khác nhau, tổng cộng hơn 30 điểm cập nhật trạng thái được đẩy qua nhiều lớp công cụ. Khi nhìn lại toàn bộ chuỗi đó, tôi bắt đầu thấy rõ một điều: từng bước xử lý riêng lẻ đều “ổn”, nhưng khi ghép lại thì không phải lúc nào cũng còn giữ nguyên ý nghĩa ban đầu của yêu cầu.
Trong trạng thái đó, tôi nhận ra một điều khá quen thuộc trong thị trường này: nhiều hệ thống không thất bại vì sai kỹ thuật, mà vì lệch khỏi mục đích ban đầu khi đi qua nhiều tầng xử lý. Rất nhiều thiết kế tập trung vào thông lượng hoặc độ ổn định vận hành, nhưng lại bỏ ngỏ câu hỏi quan trọng hơn: liệu kết quả cuối cùng còn phản ánh đúng lý do khởi tạo hay không?
Đó là lý do tôi dừng lại ở OpenLedger. Điều khiến tôi chú ý không phải là tốc độ xử lý hay cách hệ thống mở rộng, mà là hướng tiếp cận xoay quanh việc bảo toàn “ngữ cảnh” khi dữ liệu đi qua các lớp độc lập.
Điều tôi thấy rõ nhất là một dạng sai lệch thường bị che khuất: hệ thống vẫn vận hành trơn tru, nhưng ý nghĩa ban đầu của yêu cầu có thể bị biến dạng dần theo từng bước xử lý.
Nhiều hệ thống hiện tại tối ưu từng tầng riêng lẻ. Kết quả đầu ra ở mỗi bước đều hợp lý nếu đứng độc lập, nhưng khi ghép lại thì không còn giữ được sự nhất quán với mục tiêu gốc.
OpenLedger tạo cảm giác như đang đi ngược lại xu hướng đó.
Thay vì chỉ truyền dữ liệu, hệ thống cố gắng duy trì một chuỗi liên kết giữa trạng thái, quyền hạn và mục tiêu khởi tạo xuyên suốt toàn bộ quá trình.
Một truy vấn hay hành động trong hệ thống như vậy không chỉ là input để xử lý, mà là một thực thể có lịch sử, điều kiện hình thành và định hướng kết quả.
Với tôi, đây là điểm quan trọng hơn cả hiệu năng: khả năng giữ cho “ý định ban đầu” không bị phân mảnh qua từng lớp trung gian.
Nhìn từ góc độ công việc hàng ngày của tôi - đặc biệt là khi theo dõi các chương trình airdrop và viết nội dung phân tích trên X - tôi thấy một điểm tương đồng khá rõ. Mỗi ngày tôi phải xử lý khoảng 10 - 15 nhiệm vụ nhỏ: kiểm tra điều kiện dự án, xác minh on-chain, tổng hợp thay đổi từ nhiều nguồn khác nhau. Vấn đề không nằm ở từng bước riêng lẻ, mà nằm ở việc giữ nguyên “mục tiêu cuối” của cả chuỗi hành động: thứ mình đang tối ưu là lợi ích thực sự hay chỉ là hoàn thành từng task rời rạc. Nếu không giữ được ngữ cảnh đó, rất dễ rơi vào trạng thái làm đúng từng bước nhưng sai toàn bộ chiến lược.
Nhìn sâu hơn vào cách tiếp cận này, có thể thấy OpenLedger đang thử đặt ra một nguyên tắc thiết kế khác với phần lớn hệ thống hiện tại: không chỉ đảm bảo dữ liệu đi qua được, mà đảm bảo dữ liệu đi qua mà không mất nghĩa.
Các mô hình phổ biến trong thị trường thường ưu tiên tốc độ, độ mượt và khả năng mở rộng. Nhưng đổi lại, chúng có xu hướng làm mờ đi mối liên kết giữa hành động và mục tiêu ban đầu.
Trong khi đó, một kiến trúc chú trọng vào tính liên tục của ngữ cảnh buộc phải chấp nhận nhiều lớp kiểm tra và chi phí phối hợp cao hơn.
Đây chính là một dạng đánh đổi rõ ràng: hiệu suất ngắn hạn so với độ chính xác về mặt ý nghĩa dài hạn.
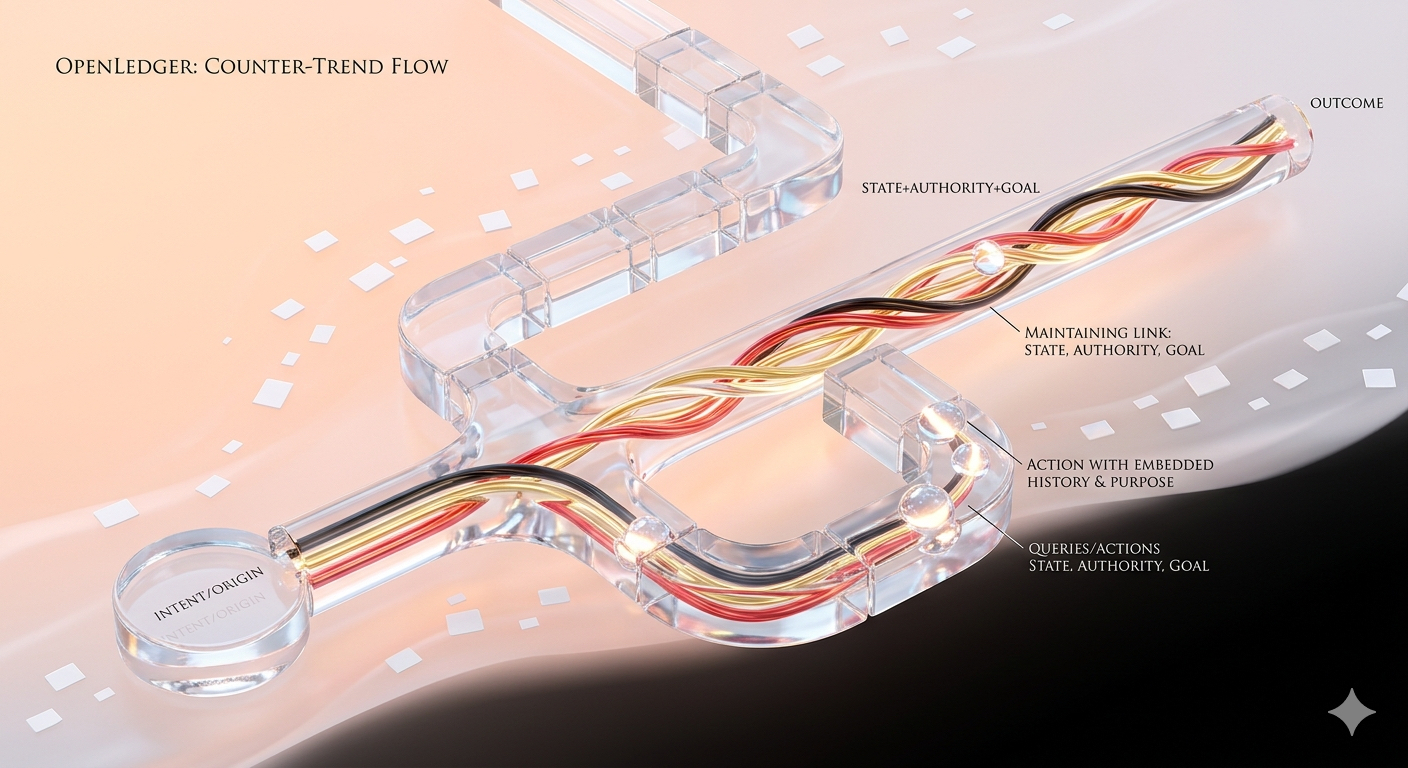
Và có lẽ chính vì nhận ra điều đó, OpenLedger được đặt trong bối cảnh như một thử nghiệm về việc liệu hệ thống phân tán có thể giữ nguyên “logic gốc” của một hành động hay không, thay vì chỉ đảm bảo nó được thực thi thành công.
Tất nhiên, hướng đi này sẽ không đơn giản.
Càng cố duy trì sự toàn vẹn của ngữ cảnh bao nhiều thì hệ thống càng phải chấp nhận thêm độ phức tạp trong xác minh và đồng bộ giữa các lớp bấy nhiêu.
Nhưng nếu nhìn theo góc độ dài hạn, đây có thể là cái giá cần thiết để tránh một vấn đề khó đo lường hơn rất nhiều: hệ thống vẫn chạy đúng, nhưng không còn làm đúng điều nó được tạo ra để làm.
Sau cùng, mình nghĩ rằng: câu hỏi quan trọng không nằm ở việc hệ thống nhanh đến đâu, mà là liệu nó có còn giữ nguyên ý nghĩa ban đầu sau khi đi qua toàn bộ chuỗi xử lý hay không ?