There is a version of the distributed AI argument that almost everyone makes, and it is boring. The argument goes: centralized AI is expensive, concentrated in the hands of a few, and therefore bad. Decentralized AI distributes the cost, opens the door to more participants, and therefore good. That framing is fine as far as politics goes. But it misses the more interesting question entirely.
The interesting question is not about cost or access. It is about whether a distributed system can produce intelligence that a centralized one structurally cannot. When I spent more time inside what #OpenLedger is actually building, that question started to feel less hypothetical.
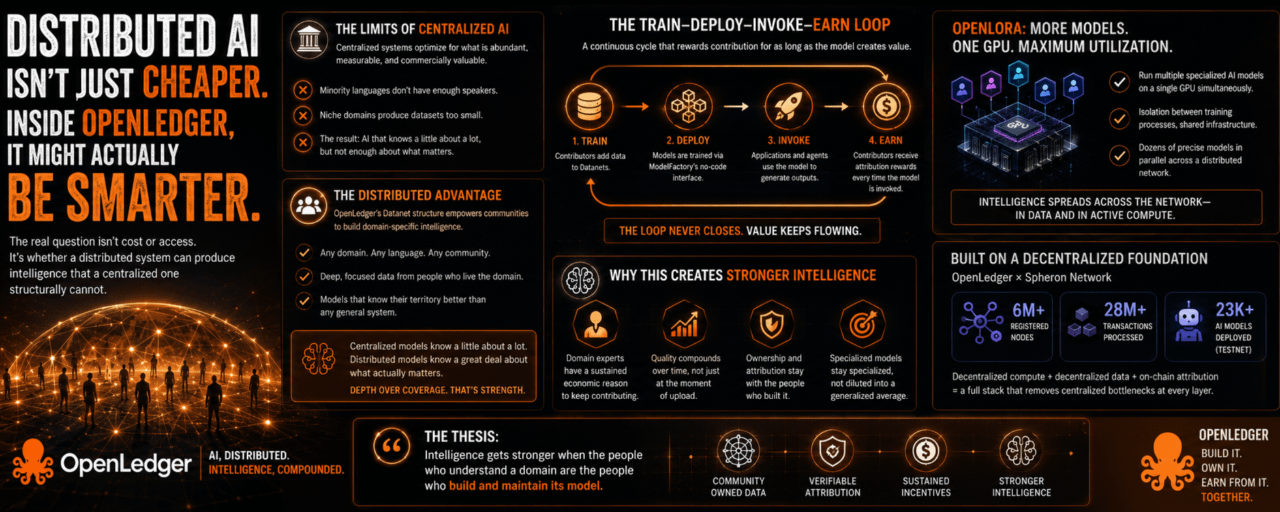
Start with what centralization does to data. When one organization controls the training pipeline, it also controls what gets included. The incentive is always toward data that is abundant, easy to label, commercially valuable, and representative of the majority. Minority language communities do not have enough speakers to justify the cost. Niche professional domains produce datasets too small to move benchmark numbers. A centralized AI system is not malicious. It just optimizes for what is measurable, and what is measurable at scale tends to reflect whoever already has scale.
OpenLedger's Datanet structure creates a different kind of pressure. Each Datanet is domain-specific, meaning a community of contributors who care about a particular field can pool their knowledge independently of whether that field is commercially obvious. A minority language does not need to justify its existence to an AI company. It just needs enough people who care about it to contribute into a dedicated Datanet. The model trained on that Datanet will understand that language better than any general system ever would, not because it had more compute, but because it had more focused, relevant data from people who actually live inside the domain.
That is where the "stronger" argument starts to feel real. A centralized model trained on everything knows a little about a lot. A distributed network of specialized models, each trained on deep, domain-specific data from actual domain participants, knows a great deal about its territory. The comparison is not just about coverage. It is about depth. And depth is exactly what most real-world applications actually need.
OpenLoRA made this logic more concrete. The system allows multiple specialized AI models to run on a single GPU simultaneously, maintaining isolation between training processes while sharing the underlying infrastructure. Dozens of narrow, precise models can operate in parallel across a distributed network without each one demanding its own dedicated hardware. The intelligence spreads across the network not just in data but in active computation, and the models stay specialized rather than collapsing into a generalized average.
This sits underneath something OpenLedger calls a train-deploy-invoke-earn loop. Data gets contributed to Datanets. Models get trained through ModelFactory's no-code interface. Those models get deployed and called by applications and agents. And contributors whose data shaped those models keep receiving attribution each time the model generates output. The loop does not close after training. It stays open for as long as the model stays useful.
What that creates is something centralized AI development cannot replicate: a system where people with deep domain knowledge have a sustained economic reason to keep improving their contribution. A doctor who uploads anonymized case data to a medical Datanet is not making a one-time donation. They are entering a relationship with a model that continues rewarding them as long as that model keeps being invoked. The incentive to maintain quality does not expire after the first upload. It compounds over time, which changes what kind of data actually enters the system.
The Spheron Network partnership reinforced this direction. Decentralized compute infrastructure paired with decentralized data and attribution creates a full stack that removes centralized bottlenecks at every layer. Developers building AI agents no longer need to route through a single cloud provider that can revoke access unilaterally. Both the intelligence and the infrastructure running it are distributed and verifiable on-chain.
Six million registered nodes. Twenty-eight million transactions processed. Twenty-three thousand AI models deployed during testnet. Those numbers describe network density forming before mainnet even launches. And network density is exactly what distributed intelligence systems need to function well. A Datanet with ten contributors produces a narrow SLM. A Datanet with ten thousand contributors begins to rival what any centralized organization could build for that domain, with the added property that contributors retain ownership of what they built.
What I keep returning to is this: the distributed AI argument is usually made on behalf of fairness and accessibility. Both are good reasons but not technical ones. OpenLedger gives the argument a technical dimension most people have not worked through. Distributed does not just mean cheaper or more open. When the distribution is organized around domain-specific intelligence, maintained by contributors with genuine expertise, and reinforced by incentives that reward sustained quality, the system starts producing something a centralized model was never going to build on its own.
Whether @OpenLedger can deliver this at scale is genuinely open. The engineering problems are hard. But the underlying thesis, that intelligence gets stronger when the people who understand a domain are also the people who build and maintain its model, is structurally sound in a way that deserves more serious attention than it usually gets.