Market felt unusually flat today. Not crashing, not pumping — just that weird sideways energy where everyone's watching the same tickers and nothing's really moving. I ended up doing what I always do in those moments: falling down a rabbit hole.
Started with something unrelated — I was reading about a lawsuit, actually. One of those ongoing cases where a major AI lab gets sued by writers claiming their work was used to train models without permission. I'd seen the headline before and usually scrolled past. But this time I stopped.
Because I realized I'd been thinking about it completely wrong.
I always assumed the AI training data debate was about copyright. Legal stuff. Who owns what. Which text got scraped, which images got used, whether some novelist in Ohio can sue a lab in San Francisco.
But that's not actually the problem.
The problem is simpler and weirder: the entire AI industry runs on a massive transfer of value — from millions of humans who created content, answered questions, wrote things, built datasets — to a handful of companies who turned that into something worth hundreds of billions. And almost nobody in that chain got anything.
So I started looking at OpenLedger, mostly out of curiosity after seeing $OPEN get mentioned a few times this week.
And something clicked.
What OpenLedger is trying to do isn't just "decentralize AI" — that phrase has been used so many times it means nothing now. What they're actually building is closer to a ledger of contribution. A way to track where training data came from, who produced it, and create a mechanism for that value to flow back.
The insight that got me is this: right now, AI companies treat training data like a natural resource. You find it, you extract it, you refine it. Nobody asks who put it there.
OpenLedger is treating it more like labor. You contributed something. You should have a record of that. Maybe even a claim on what it produced.
That's not a technical change. That's a conceptual shift about what data is.
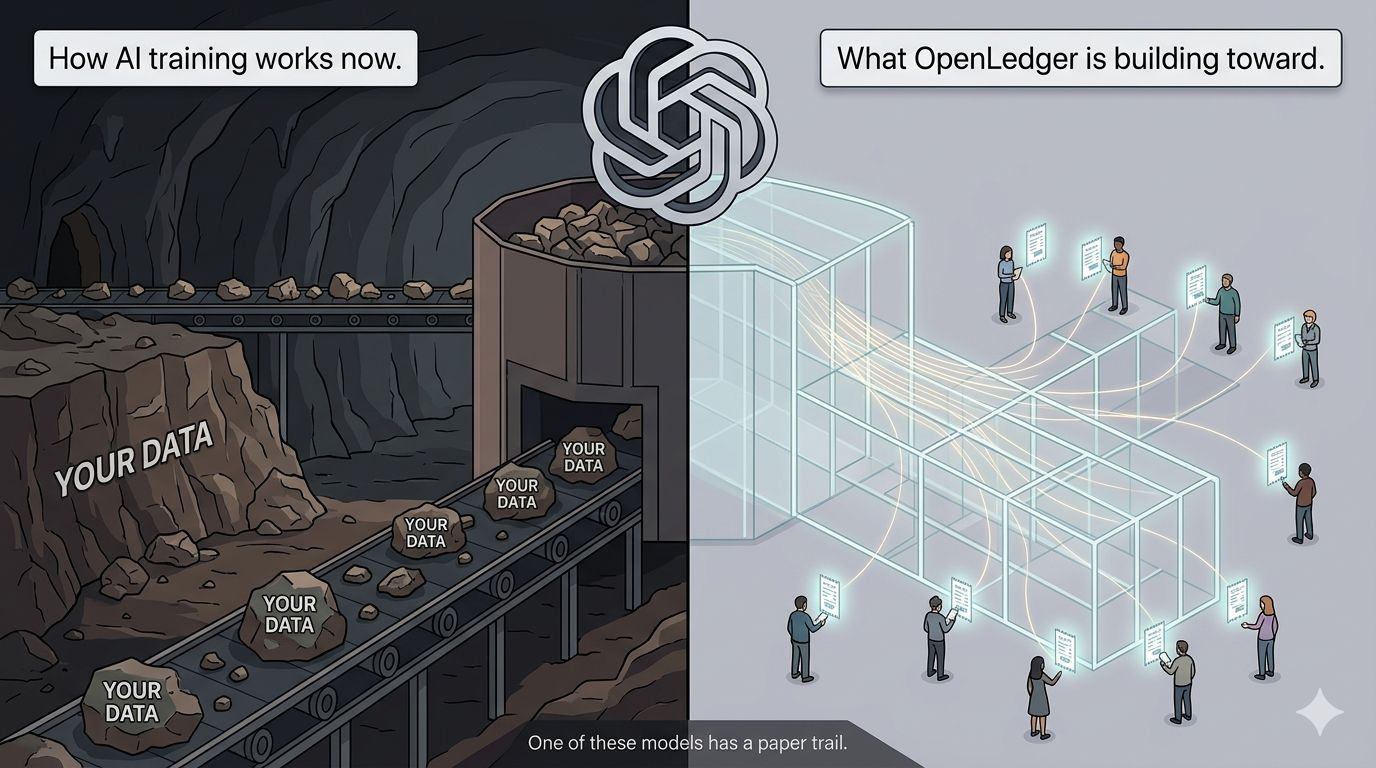
I thought at first this was just another data marketplace — like, "upload your data, get tokens." That model has failed a dozen times.
But actually, what's different here is the ledger layer. It's not just about buying and selling data. It's about provenance. Traceability. The idea that when a model gets trained, there's a verifiable record of the ingredients. Which is something no major AI lab currently wants to exist, by the way. That's worth sitting with.
Here's the part that bothers me though.
I'm not fully convinced this holds under real pressure. Because the entities with the most to lose from transparent AI training — the ones spending billions on compute and model development — are also the ones with the least incentive to plug into a system that creates accountability for them. They can just… not use it. Build their own pipelines. Use synthetic data. Keep doing what they're doing.
So OpenLedger's actual bet isn't just "we built a better system." It's "we can make the ecosystem around fair AI training large enough that ignoring it becomes costly." That's a much harder thing to pull off. It depends on developers choosing it, data contributors showing up, and enough network density that opting out feels like a disadvantage.
Does that happen? I genuinely don't know. The incentive alignment for smaller AI developers is real. The incentive for the big ones is basically zero until there's regulatory pressure — and that's moving slower than everyone pretends.
What makes it interesting as a token thesis is that $OPEN isn't just betting on AI adoption broadly. It's betting on a specific crack forming — between the people who create AI training value and the people who currently capture it. That crack is real. You can see it in the lawsuits, in the creator backlash, in the weird quiet unease that even people inside AI labs sometimes express.
Whether OpenLedger specifically is the thing that fills that crack, or whether it's just early positioning in a space that eventually matters — that part I'm still working through.
Anyway. Market's still sideways. I've been staring at this chart for twenty minutes and it hasn't done anything useful. Probably close the tab and make coffee.
But I keep thinking about that framing — data as labor, not resource. It's one of those ideas that, once you see it, makes the whole industry look slightly different.
@OpenLedger #OpenLedger