
Conferința Dartmouth: Acolo unde a fost născut „AI”
În vara anului 1956, John McCarthy, Marvin Minsky, Claude Shannon și Nathaniel Rochester s-au adunat la Dartmouth College pentru Proiectul de Cercetare de Vară pe tema AI.
Aici a fost pentru prima dată folosit termenul „Inteligență Artificială”. Propunerea a afirmat:
„Fiecare aspect al învățării sau orice altă caracteristică a inteligenței poate fi, în principiu, descrisă atât de precis încât o mașină poate fi făcută să o simuleze.”
Nu a fost un hackathon de codare. A fost un plan pentru un domeniu, indicând rețele neuronale, căutare, raționament simbolic și limbaj. Visul a fost stabilit.
Pentru a afla mai multe:
Conferința Dartmouth
De la Regulile la Învățare: Perceptronul
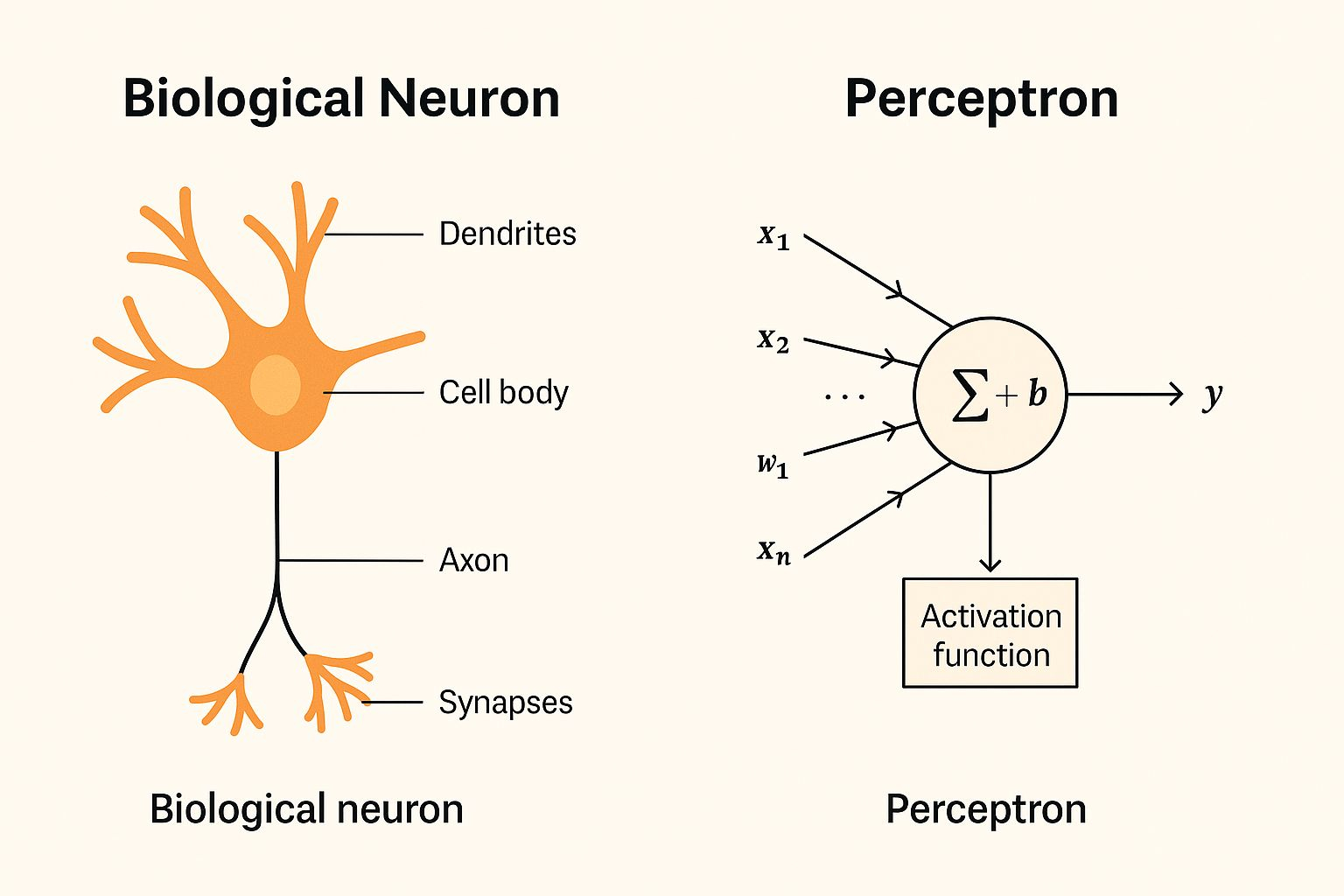
În 1957, Frank Rosenblatt a întrebat: ce-ar fi dacă mașinile ar putea învăța ca neuronii? A introdus perceptronul, primul model matematic al unui neuron.
Perceptronul ia intrări, le multiplică cu greutăți, adaugă un bias și le trece printr-o funcție pas cu pas:
f(x) = h(w ⋅ x + b)
Intrări (xi) = caracteristici, precum valorile pixelilor
Greutăți (wi) = importanța fiecărei caracteristici
Bias (b) = ajustează limita decizională
Funcția pas (h) = ieșire binară (1 sau 0)
Aceasta a făcut ca perceptronul să fie un clasificator liniar, capabil să tragă o limită dreaptă între clase.
Rosenblatt a construit și hardware: Mark I Perceptron (1960). Avea o matrice 20×20 de celule foto care acționau ca o retină, conectate aleator la unități de asociere, cu greutăți ajustabile implementate prin potențiometre. Motoarele actualizau aceste greutăți în timpul învățării.
A fost capabil să clasifice modele simple și a creat un entuziasm masiv. The New York Times a afirmat chiar că ar putea, într-o zi, să meargă, să vorbească și să fie conștient (
Arhiva NYT, 1958).

Dar avea limite: nu putea rezolva probleme precum XOR, care nu sunt separabile liniar.
📖 Află mai multe:
Perceptron (Wikipedia),
Lucrarea lui Rosenblatt din 1958 (PDF).
Modele de Limbaj și Predicția Următorului Cuvânt
În paralel, o idee foarte diferită se contura. Ar putea mașinile să prezică text în loc să raționeze logic?
Claude Shannon (1948–1951): A măsurat entropia engleză prin întrebarea oamenilor să ghicească următoarea literă. Acest lucru a dovedit că limbajul este predictibil din punct de vedere statistic.
N-gramuri (anilor 1960–1970): În loc de raționament complet, aproximează prin a privi ultimele câteva cuvinte. Un model trigram prezice P(wt | wt−2, wt−1).
Corpora: Corpul Brown (1961) a furnizat 1M cuvinte de text, permițând testarea modelelor statistice.
Aplicații: Experimentele timpurii de recunoaștere a vorbirii la IBM și Bell Labs în anii 1970 au folosit modele n-gram cu metode de netezire precum Good-Turing și ulterior Kneser-Ney.
Acest lucru este important deoarece LLM-urile moderne folosesc încă același obiectiv: prezicerea următorului token. Diferența constă în scală și arhitecturi neuronale, nu în scop.
Află mai multe:
Click Aici!
AI simbolic și Sisteme de Expertiză
După Dartmouth și Perceptron, anii timpurii au fost dominați de AI simbolic. Cercetătorii au construit sisteme de expertiză: programe care codificau cunoștințe specifice domeniului ca reguli logice.
Exemplu: MYCIN (1972) la Stanford. A folosit ~600 de reguli pentru a recomanda antibiotice pentru infecții. În cazuri restrânse, a performat la fel de bine ca medicii.
Dar AI simbolic s-a confruntat cu blocajul achiziției de cunoștințe. Scrierea și întreținerea regulilor pentru domenii reale, haotice, a devenit imposibilă. Aceasta a început căutarea unei alternative în moduri diferite.
Prolog: Programare în Logică
În 1972, Alain Colmerauer și Philippe Roussel au introdus Prolog („Programare în Logică”). Spre deosebire de programarea imperativă, Prolog era declarativ. Scriai fapte și reguli, iar sistemul deducea răspunsuri.
Exemplu:
cat(tom).
mouse(jerry).
hunts(X, Y) :- cat(X), mouse(Y).
Interogare: ?- hunts(tom, jerry). → adevărat
Prolog a alimentat AI simbolic și a fost central în Proiectul Computerelor de a Cincea Generație din Japonia (1982–1992), care a investit 400M $ în construirea de mașini inteligente de raționare.
Învățarea Automată: Datele Devine Profesorul
📖 Lecturi suplimentare: Teoria Învățării Statistice – Vapnik, Fundamentele Învățării Automate – Mohri, Rostamizadeh, Talwalkar
Până în anii 1980, AI simbolic era blocat. Regulile nu puteau captura haosul nesfârșit al lumii reale. Noua idee a fost radicală: în loc să scrii regulile manual, hrănește sistemul cu date și lasă algoritmul să descopere regulile de unul singur.
Aceasta a marcat nașterea învățării automate. Tranziția nu a fost doar filosofică, ci profund matematică. Vladimir Vapnik și Alexey Chervonenkis au formalizat ideea prin Teoria Învățării Statistice.
Problema centrală a fost generalizarea: având un set finit de date de antrenament, cum poate un model să facă predicții precise asupra cazurilor nevăzute? Vapnik și Chervonenkis au introdus idei cheie:
Dimensiunea VC: o măsură a capacității unei clase de model
Minimizarea Riscului Empiric (ERM): minimizează eroarea de antrenament
Minimizarea Riscului Structural (SRM): echilibrează eroarea de antrenament cu complexitatea modelului pentru a evita supraînvățarea
Aceasta a făcut ca învățarea automată să devină o știință în loc de o ghicitoare.
Algoritmi Timpurii: Arbori, Bayes și Margini
Odată ce teoria a fost stabilită, algoritmii practici au început să contureze industriile.
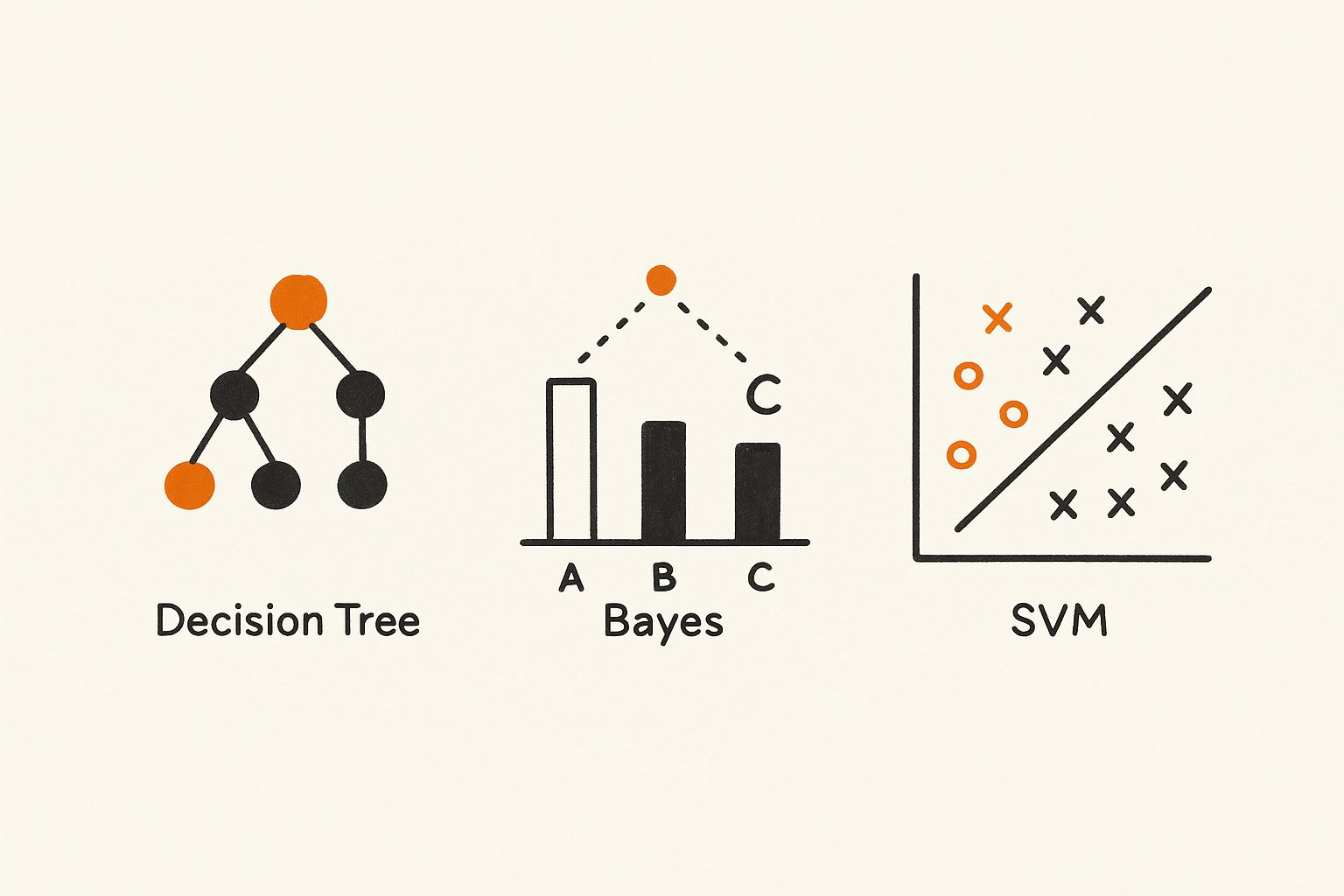
Arbori Decizionali
Ross Quinlan a introdus ID3 în 1986. Arborii decizionali împart datele pas cu pas, creând reguli if-then direct din exemple. Au fost interpretabili și utili în detectarea fraudelor, diagnosticul medical și segmentarea clienților.
Naive Bayes
Rădăcină în teorema lui Bayes, Naive Bayes presupune că caracteristicile sunt independente. În ciuda acestei simplificări, a funcționat bine pentru clasificarea textului. În anii 1990, a alimentat filtrele de spam și clasificarea documentelor la scară.
Mașini cu Vectori de Sprijin (SVM-uri)
Introduse de Vapnik în anii 1990, SVM-urile aveau scopul de a găsi hiperplanul care separa cel mai bine clasele prin maximizarea marginii. Au excelat în recunoașterea scrisului de mână, detectarea fețelor și bioinformatică, arătând o putere puternică de generalizare în spații de dimensiuni înalte.
📖 Află mai multe:
Învățarea Arborilor Decizionali (Wikipedia),
Naive Bayes (Wikipedia),
Mașini cu Vectori de Sprijin (Wikipedia).
Rețele și Producția Back-propagation
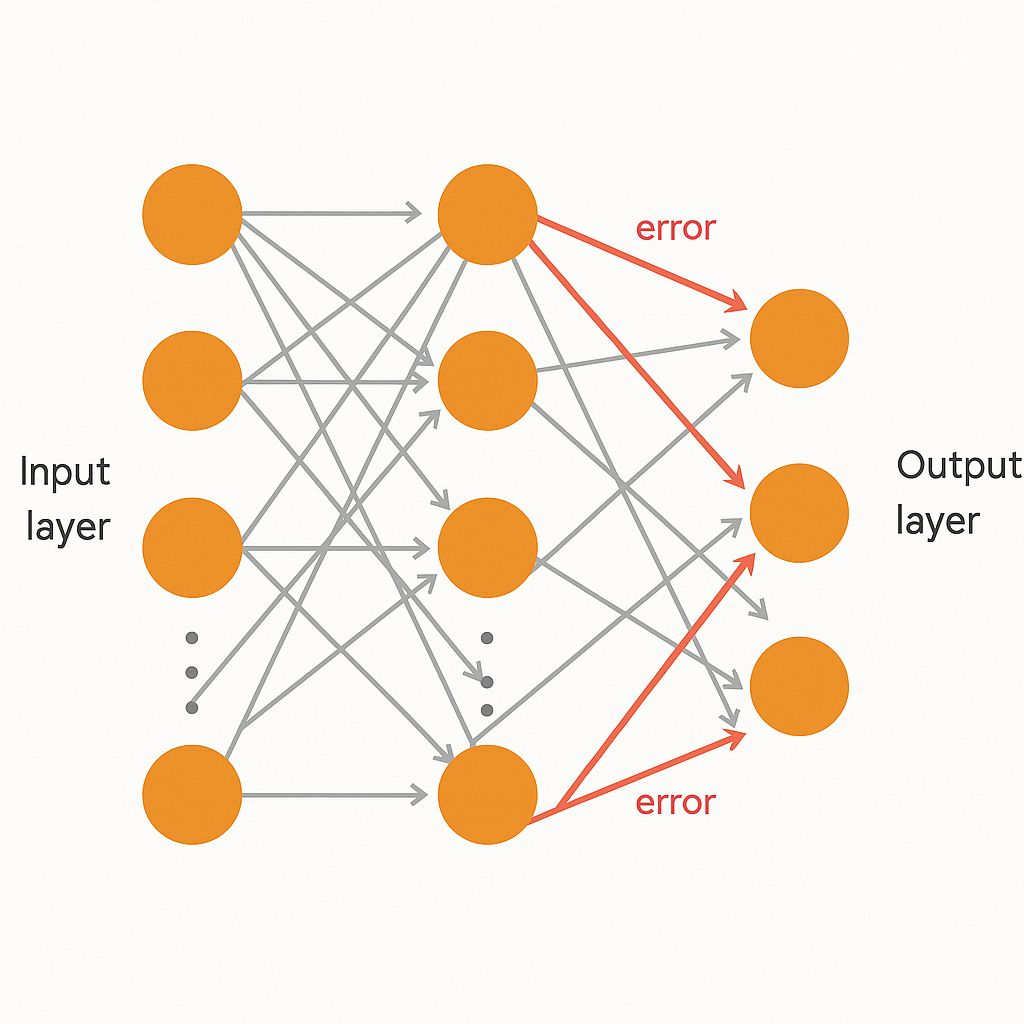
Creierul uman construiește înțelegerea în straturi: de la margini la forme la obiecte. Un singur perceptron nu putea face asta, dar perceptronii multilayer (MLP-uri) puteau.
În 1986, Rumelhart, Hinton și Williams au popularizat backpropagation, o metodă de antrenare a acestor rețele multilayer. Erorile din stratul de ieșire au fost propagate înapoi, ajustând greutățile în straturile anterioare pas cu pas.
Backpropagation a folosit gradient descent, împingând greutățile spre valori care au redus eroarea. Acest lucru a făcut ca MLP-urile să fie suficient de puternice pentru a aproxima aproape orice funcție, un fapt dovedit ulterior de Teorema Aproximării Universale.
Deși limitat de puterea de calcul și de seturile mici de date ale vremii, backprop a pus bazele rețelelor neuronale care aveau să domine AI-ul mai târziu.
Află mai multe:
Back-propagation (Wikipedia)
Concluzie: Scena pentru AI Modern
Până în anii 1990, AI stătea pe două picioare puternice. Pe o parte, algoritmii de învățare automată, cum ar fi arborii decizionali, Naive Bayes și SVM-urile alimentau aplicații în finanțe, sănătate și telecomunicații. Pe de altă parte, rețele neuronale cu backpropagation aveau puterea teoretică de a aproxima aproape orice, dar erau restricționate de limitele datelor și ale calculului.
Paralel cu acestea, a existat un fir mai tăcut, dar la fel de important în modelarea limbajului. De la experimentele timpurii ale lui Claude Shannon cu predictibilitatea în textul englezesc la modelele n-gram și cercetările în recunoașterea vorbirii, ideea de a prezice următorul cuvânt a devenit o modalitate practică de a captura tipare în limbaj.
Când seturi mari de date au apărut în anii 2000 și GPU-urile au deblocat scala, aceste trei curente au început să se convergă. Algoritmi orientați de date, rețele neuronale cu backpropagation și tradiția predicției următorului cuvânt s-au combinat în ceea ce numim acum învățare profundă.
Începuturile umile ale perceptronului, rigoarea teoriei învățării statistice, descoperirea backpropagation-ului și persistența modelării limbajului s-au unit pentru a crea fundațiile AI-ului modern.

În următorul blog, vom explora cum rețelele neuronale au evoluat în CNN-uri, RNN-uri și învățare profundă, și cum necesitatea de putere de calcul și blocajele de date au pregătit terenul pentru nașterea transformatoarelor.
OPENLEDGER
