Điểm nghẽn lớn nhất trong việc phát triển AI hiện tại mà mình thấy có lẽ không nằm ở compute layer hay kích thước mô hình, mà nằm ở data value chain (chuỗi giá trị dữ liệu), cho tới khi thử nhìn lại cách các LLM đang tiêu thụ chất xám của chúng ta, @OpenLedger lại là một trong những cái tên khiến mình phải đặt câu hỏi lại toàn bộ cách một AI model đang vận hành và phân phối lợi ích.
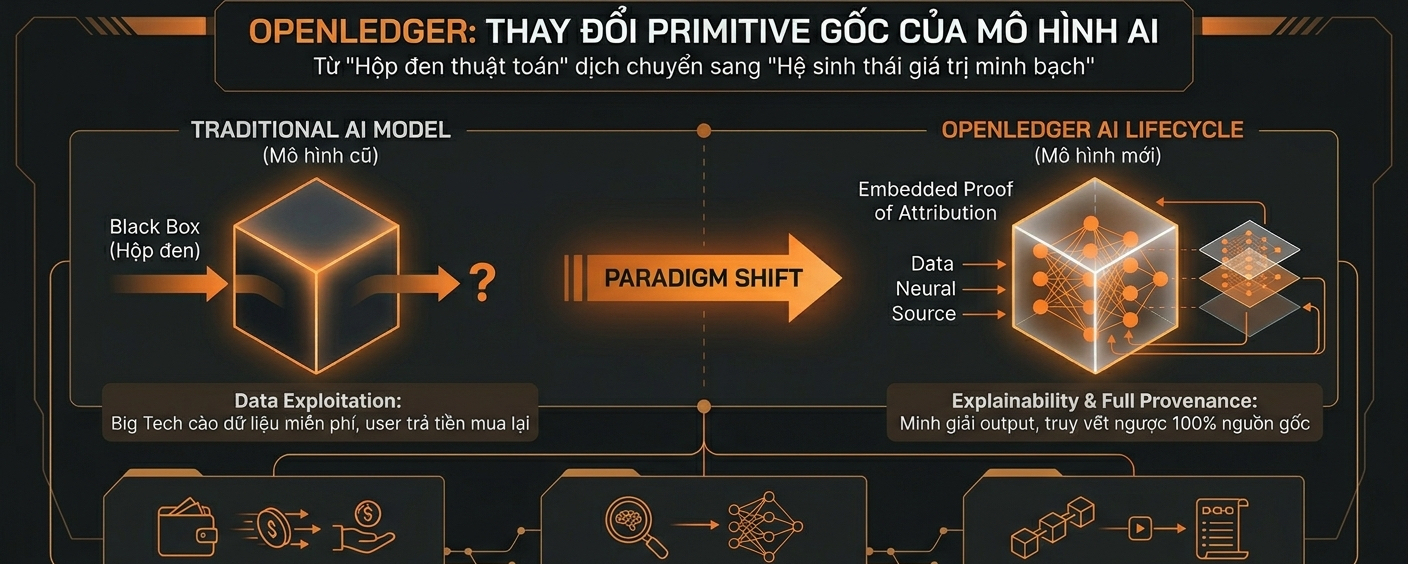
Trước đây mình hay nghĩ vấn đề của AI phi tập trung (Decentralized AI) chỉ nằm ở việc gom chip, tối ưu tốc độ render hoặc giảm latency cho inference. Gom được nhiều node, chạy model mượt, chi phí rẻ từng được xem là tiêu chuẩn tối ưu. Nhưng khi nhìn lại kỹ hơn, mình bắt đầu thấy vấn đề không nằm ở “năng lực xử lý”, mà nằm ở giả định nền tảng phía dưới: các model hiện tại luôn hoạt động như một cái hộp đen (black box) – lấy data của cộng đồng để train, nén nó thành các checkpoint tĩnh, rồi trả ra kết quả mà không có bất kỳ cơ chế đối chiếu ngược nào về quyền sở hữu hay tính giải trình.
Toàn bộ hệ thống từ thu thập dữ liệu, scraping, tokenization cho tới training đều xoay quanh một pipeline cố định: contributor đưa data thô, hệ thống nạp vào để tối ưu weight, rồi model tự sinh output dựa trên đống weight đó. Trong pipeline này, mối quan hệ giữa người đóng góp dữ liệu và mô hình bị cắt đứt hoàn toàn ngay sau khi giai đoạn training kết thúc. Data contributor không có cách nào chứng minh giá trị đóng góp của mình, và user cũng không thể biết tại sao mô hình lại đưa ra câu trả lời đó.
Đây là điểm rõ nhất mình thấy OpenLedger đang thay đổi thông qua cơ chế Proof of Attribution. Họ không bắt đầu từ việc cố gắng build một mô hình lớn hơn để cạnh tranh với Big Tech. Họ thay đổi luôn primitive gốc trong kiến trúc nhúng của model. Trong thiết kế của họ, mỗi model không còn là một khối ma trận toán học vô danh nữa, mà được nhúng thẳng một cơ chế bằng chứng liên tục (embedded attribution layer) để quản lý vòng đời dữ liệu.
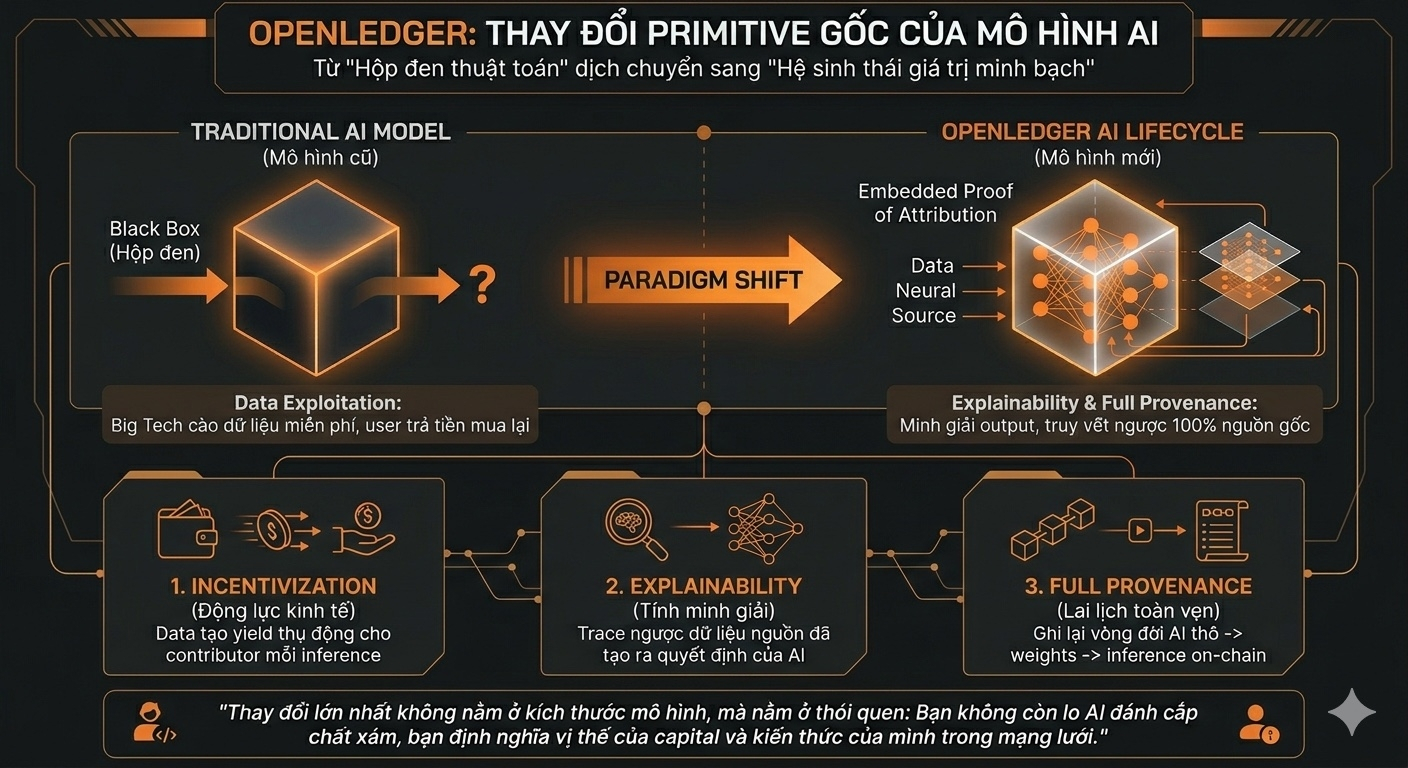
Điểm khác nằm ở chỗ data không được xử lý như một input một lần (one-time input). Trong hệ thống của OpenLedger, đóng góp của data contributor được mã hóa và theo dõi liên tục thông qua ba trục cốt lõi: incentivization, explainability, và full provenance. Những yếu tố này không tồn tại riêng lẻ mà được giữ như một bộ khung ràng buộc chặt chẽ vào cấu trúc nội bộ của model, thay vì là một layer bổ sung bên ngoài.
Trước khi bất kỳ output nào được sinh ra, hệ thống của OpenLedger phải chạy một pipeline đối chiếu ngược. Nghĩa là system không chỉ sinh text hay tạo kết quả, mà còn phải chuyển đổi output đó thành một cấu trúc giải trình (explainability mapping), trong đó từng cụm dữ liệu đầu ra được trace ngược về các nguồn đóng góp ban đầu, gán trọng số động dựa trên context của prompt và mức độ ảnh hưởng của dữ liệu gốc đối với kết quả cuối cùng.
Ví dụ, nếu mô hình đưa ra một câu trả lời tối ưu hóa thanh khoản cho một cấu trúc DeFi phức tạp, hệ thống không chỉ trả kết quả một cách khơi khơi. Nó tự động bóc tách xem nguồn dữ liệu từ researcher nào, snapshot từ on-chain indexer nào đã đóng góp vào quyết định này để kích hoạt cơ chế trả thưởng (incentivization) theo thời gian thực cho họ.
Tức là model không còn là một black box tiêu thụ dữ liệu thụ động, mà trở thành một interface phân phối giá trị sòng phẳng giữa data contributor và user cuối.
Họ không đẩy sự mâu thuẫn về bản quyền và tính chính xác của dữ liệu về phía người dùng tự mò mẫm. Thay vào đó, OpenLedger đưa toàn bộ sự minh bạch xuống system layer, nơi hệ thống không chỉ ghi nhận data contributor một lần lúc train, mà liên tục cập nhật và giải quyết xung đột lợi ích theo từng lượt inference của model.
Mình bắt đầu nhận ra một hệ quả rất rõ của thiết kế này. Trong các mô hình AI truyền thống, rủi ro về tính đúng đắn được xử lý ở phía con người, con người đọc kết quả rồi tự dùng trực giác để đoán xem AI có đang "ảo tưởng" (hallucinate) hay không. Trong OpenLedger, sự mơ hồ (ambiguity) đó bị triệt tiêu bằng lớp provenance layer – hệ thống ghi lại toàn bộ vòng đời của AI (AI lifecycle) từ nguồn dữ liệu gốc, quá trình fine-tuning cho đến trạng thái weight hiện tại để đảm bảo tính toàn vẹn tuyệt đối.
Nếu không có cơ chế này, hệ thống vẫn trả ra kết quả chính xác về mặt cú pháp, nhưng có thể sai lệch hoàn toàn về mặt ngữ nghĩa tài chính hoặc kỹ thuật nếu data nguồn bị nhiễm bẩn hoặc bị thao túng mà không ai biết. Điều nguy hiểm là mô hình không báo lỗi, nó vẫn chạy đúng logic, chỉ là priority của dữ liệu nguồn đã bị bóp méo.
Mình từng thấy điều tương tự khi test các agent phân tích dữ liệu on-chain: kết quả nhìn rất mượt nhưng hóa ra lại lấy từ một tập data cũ đã lỗi thời. Với OpenLedger, vấn đề này được giải quyết triệt để vì lai lịch của mô hình (full provenance) được cố định và xác thực rõ ràng.
Trong kiến trúc này, rủi ro không còn là "data inconsistency" nữa, mà dịch chuyển thành "attribution execution". Tức là giá trị cao nhất của AI không nằm ở việc nó thông minh đến đâu, mà nằm ở việc kết quả nó trả ra có thể truy vết và tin cậy được bao nhiêu phần trăm.
Theo mình, đây là điểm thay đổi lớn nhất. AI model không còn là một công cụ trung lập để con người khai thác miễn phí nữa. Nó trở thành một thực thể kinh tế minh bạch, nơi bạn định nghĩa giá trị chất xám đóng góp, và hệ thống sẽ tự xử lý phần chia sẻ lợi ích tương ứng trên mạng lưới.
Nhìn từ góc độ trải nghiệm thực tế, điều này kéo theo một thay đổi khá rõ mà cả builder lẫn user sẽ gặp trước tiên: cách chúng ta tương tác với AI mỗi ngày.
Nếu AI thật sự chuyển sang intent có embedded proof như OpenLedger, trader hay researcher không còn cần phải mù quáng tin vào các câu trả lời vô căn cứ của chat bot nữa.
Thay vào đó, workflow sẽ chuyển sang kiểu kiểm toán hệ thống: check xem nguồn data tạo ra câu trả lời này đến từ đâu, độ uy tín thế nào trước khi bấm nút execute. Phần còn lại không phải là nghi ngờ AI, mà là tracking xem hệ thống đã ghi nhận đúng giá trị đóng góp của mình chưa.
Điều này nghe có vẻ xa, nhưng nó sẽ làm thay đổi một thứ rất quen thuộc: cảm giác e dè khi chia sẻ chất xám lên không gian mạng.
Trong mô hình cũ, việc giữ kín dữ liệu cốt lõi thường tạo cảm giác an toàn hơn vì sợ bị Big Tech "cào" mất. Trong mô hình OpenLedger đang đi, việc đóng góp dữ liệu chất lượng lại trở thành một cách tối ưu hóa asset, vì giá trị của bạn không còn nằm ở việc bạn giấu data tốt đến đâu, mà nằm ở việc data của bạn được embedded vào model sâu đến đâu.
Và nếu điều này đúng, thì thứ thay đổi đầu tiên không phải là số lượng parameter của mô hình, mà là thói quen của toàn bộ cộng đồng làm dữ liệu.
Không còn bắt đầu ngày mới bằng việc lo lắng chất xám của mình bị AI đánh cắp, mà bắt đầu bằng việc xác định: hôm nay data của mình sẽ đóng góp vào những model nào, và liệu một kiến trúc như OpenLedger có đang biến kiến thức của mình thành một nguồn yield thụ động thực sự hay không?