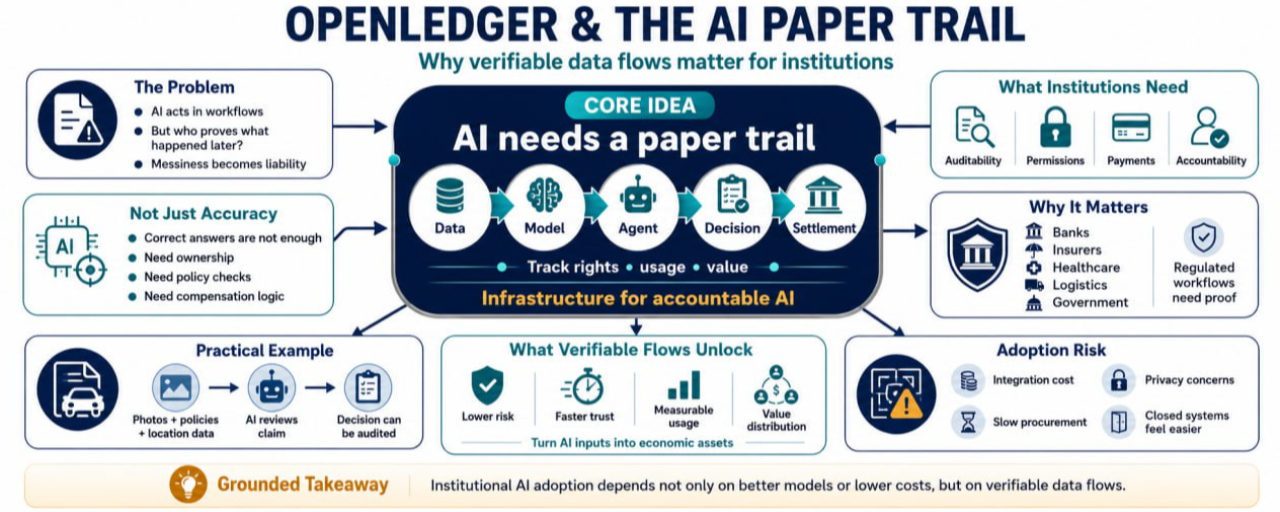
I had a small moment of doubt recently while reading about AI agents being used inside real business workflows. Not the usual doubt about whether AI is useful. That part feels settled enough. My question was simpler: if an AI system makes a decision, uses a dataset, triggers a payment, or recommends an action, who proves what actually happened later?
That question matters more than it sounds. In consumer AI, people often tolerate messy outputs. In institutional environments, messiness becomes liability. A bank, insurer, healthcare platform, logistics company, or government contractor cannot simply say, “the model said so.” Users want better service. Builders want faster deployment. Institutions want efficiency. Regulators want accountability. Those goals collide when the data trail is unclear.
This is where @OpenLedger becomes interesting to me. Not as a magic fix, but as infrastructure for a problem that is usually hidden until something goes wrong.
The Problem Is Not Just AI Accuracy
Most AI discussions focus on model performance. Is the answer correct? Is the agent fast? Is the system cheaper than a human team?
Those are important questions, but institutions usually ask another layer of questions. What data was used? Who owned it? Was permission granted? Was the model allowed to access that source? Did the agent follow policy? Who gets paid if the data or model creates value?
Without answers, AI workflows become hard to audit. A company may save money today, but face disputes later over compliance, licensing, privacy, or settlement. That is why centralized AI infrastructure can feel incomplete. It may provide compute, APIs, and dashboards, but not always a shared record of rights, usage, value creation, and compensation.
For small apps, that may be acceptable. For regulated industries, it is a serious blocker.
Why Verifiable Data Flows Matter
Institutions do not adopt infrastructure just because it sounds elegant. They adopt it when it lowers operational risk.
A verifiable AI data flow means the path from data input to model use to agent action can be tracked with more confidence. Not every detail needs to be public, but the system should be able to prove that certain rules were followed. This includes ownership, access, permissions, payments, and settlement.
That is where OpenLedger’s focus on unlocking liquidity for data, models, and agents connects to the real world. If data and AI assets can be monetized, then usage must be measurable. If usage is measurable, value distribution becomes possible. If value distribution becomes possible, then institutions can start treating AI inputs as economic assets rather than invisible backend resources.
This is also where $OPEN fits naturally into the discussion. The token is not the whole story. The more important question is whether the network around OPEN can support credible coordination between data contributors, model builders, agent operators, users, and enterprises.
A Practical Example: Insurance Claims
Imagine an insurance company using AI agents to process damage claims after a flood.
The agent reviews photos, policy documents, location data, repair estimates, and historical claim patterns. A user wants a fast payout. The insurer wants fraud control. A builder provides the AI workflow. A third-party dataset improves risk scoring. Regulators may later ask why a claim was approved, reduced, or denied.
In a weak system, the company only has internal logs and vendor promises. That may not be enough if customers dispute decisions or regulators investigate bias.
With infrastructure like OpenLedger, the workflow could become more structured. Data sources could have clearer ownership and access records. Model contributions could be tracked. Agent actions could be tied to settlement logic. Value could flow back to contributors whose data or models helped create the final output.
This does not remove legal responsibility. It may simply make responsibility easier to assign.
The Human Side: Trust Is Expensive
People often talk about trust like it is a feeling. In institutions, trust is a cost center.
If an AI system cannot be explained or audited, companies add manual reviews, legal checks, compliance teams, vendor audits, and slower approval processes. That increases cost and reduces the efficiency AI was supposed to create. $PLAY
OpenLedger could matter because it aims at the coordination layer, not just the intelligence layer. Builders need a way to plug AI assets into workflows without creating ownership confusion. Users need confidence that systems are not exploiting their data silently. Institutions need records that can survive audits. Regulators need enough visibility to enforce rules without blocking useful innovation.
That balance is difficult. But the need for it is real.
The Risk: Adoption May Be Slower Than the Idea
The cautious view is important here. Institutions move slowly, especially when legal exposure is involved. Even if OpenLedger provides useful infrastructure, adoption could be slowed by integration costs, unclear regulations, enterprise procurement cycles, privacy concerns, or competition from existing cloud and compliance vendors.
There is also a behavioral problem. Many companies like the benefits of AI but dislike exposing how their systems actually work. Verifiability sounds good until it forces uncomfortable transparency.
So the question is not whether OpenLedger has a relevant thesis. I think it does. The question is whether enough builders and institutions will accept a more accountable AI economy instead of staying with closed systems that feel easier in the short term.
Grounded Takeaway
The real users of OpenLedger may not be casual AI consumers at first. They may be builders creating agent workflows, institutions managing regulated data, data owners looking for compensation, and compliance teams trying to reduce ambiguity. $ALT
It might work if OpenLedger can make AI data flows easier to verify, monetize, and settle without adding too much friction. It could fail if institutions decide the cost of changing systems is higher than the risk of staying centralized and opaque.
That is why #OpenLedger is worth watching with a calm lens. Not as a hype cycle, but as part of a bigger question: can AI systems become economically useful while also being legally accountable?
Not financial advice.
What do you think matters more for institutional AI adoption: better models, lower costs, or verifiable data flows?