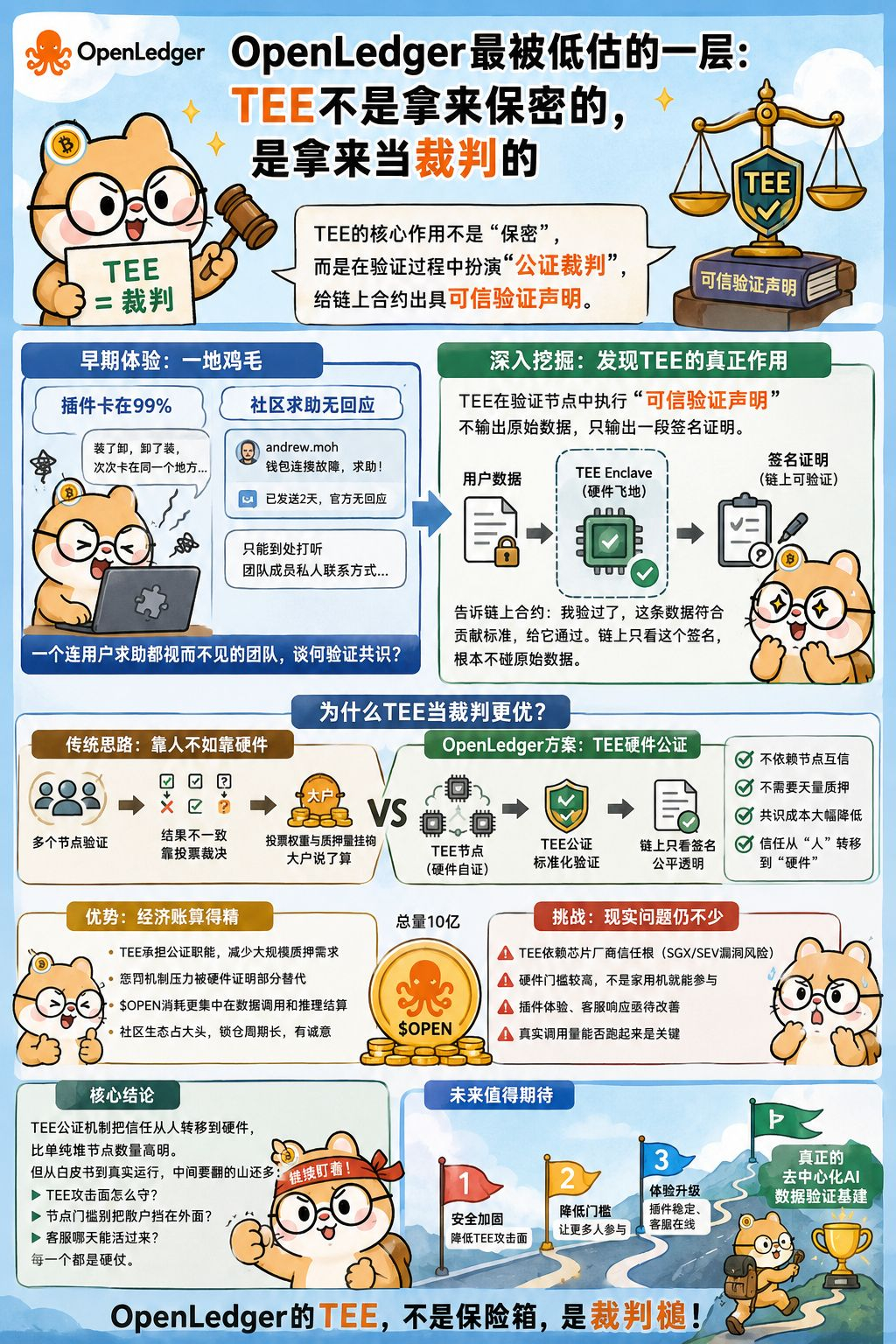
我这人有个习惯,看项目喜欢先翻开发者文档。OpenLedger的docs里,TEE这个词出现了几十次,但大部分外部文章几乎不聊它,要么就随口一句“用了TEE保护隐私”。我越看越觉得不对,如果只是隐私保护,没必要把它塞进验证层的核心逻辑里。
还没等我往深了挖,那股熟悉的无奈感就先来了。我试着装了下插件想跑跑节点环境,结果同步卡在99%,跟之前一个德性。装了卸、卸了装,来回三次,次次卡在同一个地方。说真的,写到这儿我已经不想管它架构多精妙了,光插件事儿就够我拉黑一百遍。一个号称要做AI数据基建的项目,连个浏览器插件都做不稳,你让我怎么信你能管住那么复杂的链上验证?
耐着性子去翻了翻社区,结果就看到那条现在还挂着的帖子。用户andrew.moh在Followin求助,钱包连接故障,两天里在社群反复喊,官方连个已读都没有,最后只能到处打听团队成员私人联系方式。我盯着那条帖子看了很久,心里不是同情,是发凉。一个连用户求助都视而不见的团队,你跟我说它能解决去中心化AI最头疼的验证共识问题?闹呢。这不是能力问题,就是态度问题。
但我这人有个改不掉的倔毛病,越是碰一鼻子灰,越想把它老底翻个底朝天。所以我还是把@OpenLedger 白皮书翻到了共识机制那章,结果找到了一段很容易被跳过的描述。TEE在验证节点里的作用,不仅是给数据加密,而是在执行一个叫“可信验证声明”的东西。翻译成人话就是:节点在拿你的数据跑验证的时候,不是在普通环境里跑的,而是在CPU的硬件飞地里跑的,英文叫Enclave。跑完之后,TEE不输出原始数据,只输出一段经过签名的证明,告诉链上合约:我验过了,这条数据符合贡献标准,给它通过。链上只看这个签名,根本不碰原始数据。
说实话写到这儿我自己都有点绕,这玩意儿不看三遍捋不顺。但没办法,它整个验证逻辑的命门就藏在这几段里。
我当时意识到,这套逻辑的重点根本不是“保密”,而是“公证”。它解决了一个极其难缠的问题,在去中心化网络里,你怎么让一个你没见过、也不信任的陌生人,替你做数据验证,还能相信他没作弊?传统思路是堆验证节点数量,用经济博弈来防止合谋。但OpenLedger走了另一条路:我不管你人可不可信,我信的是你那台机器的CPU芯片。TEE的硬件证明变成了一种链上可信的裁决依据,不需要验证节点之间互相确认,也不需要质押天量代币来发誓你没撒谎。这在架构上等于换了条路,共识成本的大头不靠质押代币来扛了,而是让硬件芯片替你担保。
我试着把这个逻辑跟我以前研究过的项目对照着看。之前看过几个去中心化数据标注的项目,最大的痛点就是验证结果没法统一。同一个图片标注任务,三个节点给三个答案,最后靠投票裁决,但投票权重又跟质押量挂钩,绕了一圈还是大户说了算。OpenLedger这套TEE公证机制,相当于把验证过程标准化了,不是看谁币多,而是看谁的执行环境是干净的、可被硬件自证的。这个想法确实有点东西,不是那种拍脑袋的叙事。
不过说真的,写到这儿我已经对它的架构有点服气了。但服气归服气,坑还是一个都没少。
这种架构的代价很明显。TEE的安全性高度依赖芯片厂商的信任根,Intel SGX和AMD SEV都被学术界挖出过漏洞,虽然实战利用的门槛很高,但这个攻击面是真实挂在那儿的。另外,部署TEE对节点的硬件门槛有要求,不是随便一台云服务器就能跑,这跟去中心化倡导的“家用机也能参与”有点拧巴。
不过回到技术本身,这套验证架构的经济账算得挺精。因为TEE承担了验证的公证职能,系统不需要在每一层都质押大量代币来防范作弊,惩罚机制的压力被硬件证明部分替代了。OPEN代币的消耗场景因此更集中在数据调用和推理结算上,而不是全压在质押风控上。这是一个被严重低估的设计,大部分人聊OpenLedger都在聊数据和AI,很少有人从这个角度去拆。
$OPEN 总量10亿,社区生态占大头,锁仓周期也不短。账面有诚意,但我最在意的还是真实调用量能不能跑起来。如果链上交易大部分还是空投脚本在刷,那这些精妙的设计最后就是一堆漂亮的PDF。
我暂时不会把它一棍子打死。TEE公证机制这种把信任从人转移到硬件的思路,确实比单纯堆节点数量高明。但从白皮书到真实运行,中间要翻的山还多,TEE的攻击面怎么守、节点门槛别把散户全挡在外面、客服哪天能活过来,随便哪个都是硬仗。我打算继续盯着,看这套机制是真能转起来,还是又一场高开低走。#OpenLedger