Am răsfoit whitepaper-ul privind dovezile de atribuire acum câteva zile, așteptând genul acela de prezentare tehnică de nivel înalt pe care majoritatea proiectelor AI blockchain îl folosesc pentru a descrie mecanisme pe care nu le-au implementat pe deplin. Asta e standardul. Publică un whitepaper care sugerează o metodologie, lansează un produs care se apropie de ea și speră că nimeni nu va urmări decalajul dintre cele două. Whitepaper-ul Openledger nu e așa, de fapt. Descrie două abordări specifice de atribuire cu o adâncime tehnică reală: aproximări ale funcției de influență pentru modele mai mici și atribuire de token-uri bazată pe array-uri de sufix pentru cele mai mari. Metodologia e reală. Cineva a gândit cu atenție asta.
apoi am citit abordarea array-ului sufixurilor mai atent.
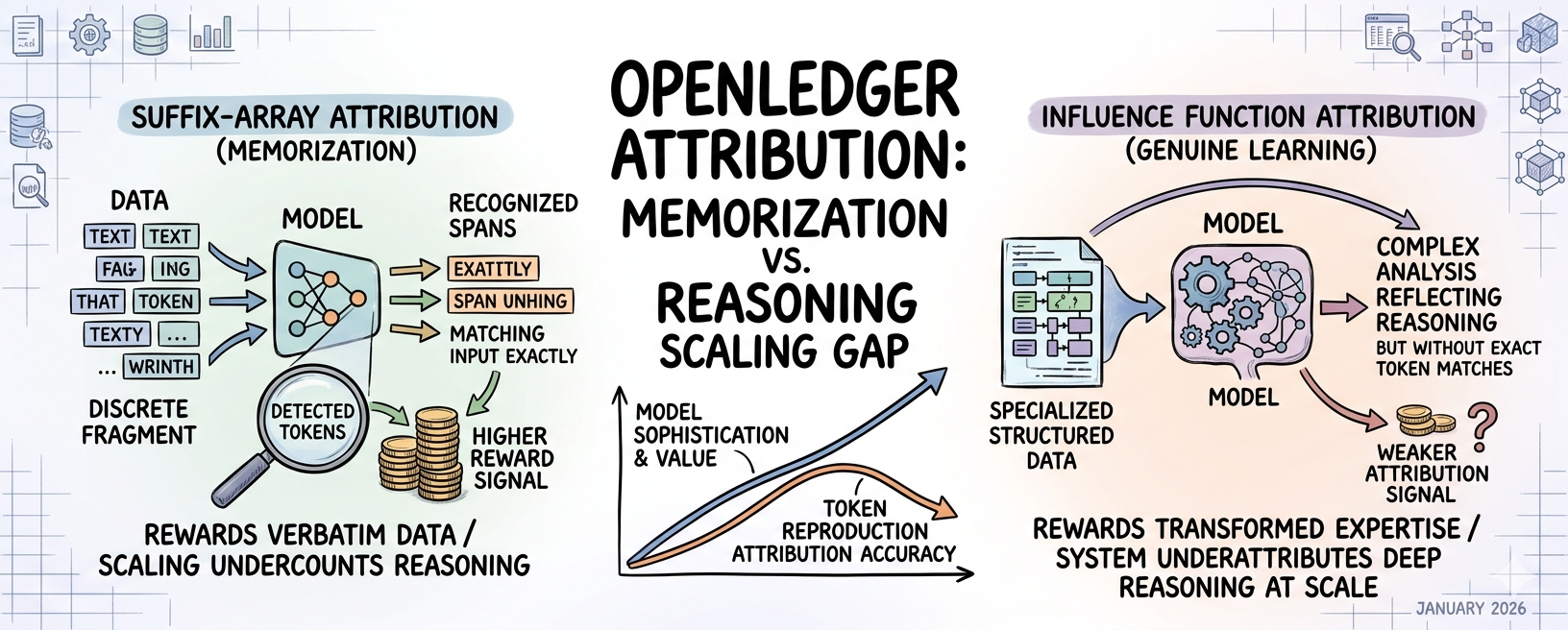
atributia pe baza array-ului sufixurilor funcționează prin comprimarea corpusului de antrenament și verificând dacă tokenurile de ieșire apar în intervale memorate din acel corpus. ideea este că, dacă ieșirea unui model conține secvențe de tokenuri care se potrivesc cu datele de antrenament comprimate, poți atribui acea influență înapoi la contribuabili specifici. este o tehnică legitimă. dar are o proprietate specifică de scalare pe care whitepaper-ul o recunoaște într-un mod pe care majoritatea cititorilor l-ar trece cu vederea fără să se oprească: abordarea identifică intervalele memorate, nu raționarea influențată. un model care a învățat cu adevărat din expertiza domeniului va produce rezultate care reflectă acea expertiză fără a reproduce neapărat secvențe de tokenuri memorate. mecanismul de atribuire recompensează influența detectabilă prin memorare. ar putea subestima sistematic contribuția datelor care au învățat modelul să raționeze mai degrabă decât datele pe care modelul a învățat să le reproducă. 🔍
această distincție contează enorm pentru ceea ce openledger încearcă să construiască. întreaga propunere de valoare a modelelor de limbaj specializate - motivul pentru care există datanets, motivul pentru care contribuabilii ar trebui să ofere date relevante pentru domeniu și nu text extras - este că expertiza autentică în domeniu produce o raționare mai bună, nu doar o memorare mai bună. un model legal antrenat pe analize contractuale structurate ar trebui să producă rezultate care reflectă raționarea legală, nu rezultate care reproduc limbajul legal fidel. dar atribuirea pe baza array-ului sufixurilor măsoară mai fiabil al doilea tip de influență decât primul. pe măsură ce modelele se scalază și rezultatele lor devin mai puțin similare reproductiv cu datele de antrenament și mai cu adevărat transformate de acestea, mecanismul de atribuire poate deveni progresiv mai puțin precis exact atunci când modelele devin cele mai sofisticate și valoroase.
stau cu o implicație specifică a cărei rezolvare completă nu o pot găsi. contribuabilii care oferă cele mai valoroase date sunt experți în domeniu care contribuie cu analize structurate și exemple bine argumentate, mai degrabă decât text brut, și pot fi sistematic subatribuiți comparativ cu contribuabilii care oferă mari volume de date bogate în text, conținând secvențe de tokenuri memorabile. ambele profiluri de contribuabili ar vedea evenimente de atribuire. dar influența expertului contribuabil, care funcționează prin transformare rațională mai degrabă decât reproducerea tokenurilor, ar genera semnale de atribuire mai slabe sub potrivirea array-ului sufixurilor. structura de recompensă pare să funcționeze. distribuția recompenselor în cadrul acelei structuri s-ar putea să nu se potrivească cu distribuția valorii reale contribuie.
am observat ceva structurally similar să se întâmple cu algoritmii de clasificare a motorului de căutare la începutul anilor 2010. algoritmii măsurau ce puteau măsura: densitatea linkurilor, frecvența cuvintelor cheie, repetarea textului, deoarece acele semnale erau tehnic tractabile. ceea ce nu puteau măsura direct era lucrul pe care își doreau cu adevărat să-l măsoare: expertiza autentică și cunoștințele autoritare. rezultatul a fost că conținutul optimizat pentru semnalele măsurabile a avut un rang mai mare decât conținutul cu expertiză autentică până când algoritmii au devenit suficient de sofisticați pentru a închide acel decalaj. optimizarea nu s-a întâmplat pentru că creatorii de conținut erau rău intenționați, ci pentru că măsurarea era sistematic offsetată față de valoarea de bază. mecanismul de atribuire al openledger ar putea fi exact în aceeași etapă timpurie a algoritmului, măsurând un proxy tractabil pentru influență în loc de influență în sine și recompensând proxy-ul în loc de valoare.
elementul cu adevărat puternic aici este că whitepaper-ul recunoaște limitările metodologiei în loc să le ascundă. acea transparență este mai mult decât oferă majoritatea proiectelor de blockchain AI și semnalează că echipa înțelege că măsurarea este o aproximare. actualizarea motorului de atribuire din ianuarie 2026 a fost proiectată specific pentru a menține legăturile dintre date și rezultate pe măsură ce modelele evoluează, ceea ce sugerează că echipa a identificat problema scalării ca fiind ceva care necesită atenție inginerescă activă, mai degrabă decât o preocupare teoretică care să fie notată și uitată.
există o variantă a acestui lucru în care greșesc. openledger ar fi putut implementa o abordare hibridă de atribuire în producție care suplimentează potrivirea array-ului sufixurilor cu ponderarea funcției influenței pentru modele mai mari, folosind metoda mai costisitoare din punct de vedere computațional, dar mai precisă, exact acolo unde metoda mai ieftină devine nesigură. dacă acel hibrid există și funcționează, acuratețea atribuirii nu se degradează la scară, iar contribuabilii experți sunt creditați corespunzător. ceea ce nu am putut găsi în documentația publică a fost vreo confirmare că sistemul de producție folosește o abordare diferită față de descrierea principală din whitepaper pentru modelele mari.
ce aș dori să văd nu este o actualizare tehnică a whitepaper-ului. o defalcare publică reală a metodologiei de atribuire pe baza dimensiunii modelului, specific, care abordare de atribuire este activă pe modelele care sunt în prezent desfășurate pe mainnet și dacă există vreo abordare hibridă sau suplimentară operativă pentru modelele deasupra unui anumit prag de parametru. acea divulgare, apărând din orice actualizare a documentației de la actualizarea motorului de atribuire livrat în ianuarie, mi-ar spune dacă limita de scalare este o aproximare cunoscută pe care echipa o abordează activ sau un decalaj neacceptat între ceea ce descrie whitepaper-ul și ceea ce măsoară sistemul de producție în prezent. absența sa înseamnă că cei mai preciși contribuabili ai openledger - cei ale căror expertiză transformă raționarea modelului mai degrabă decât vocabularul modelului - ar putea fi cei pe care sistemul este cel mai puțin echipat să-i crediteze. ceea ce este un loc ciudat pentru a fi pentru un protocol a cărui întreagă propunere de valoare este că face influența contribuției verificabilă mai degrabă decât asumată.
