I’m watching OpenLedger pretty closely lately, and honestly, I think most people still misunderstand what it’s trying to build.
Everybody keeps obsessing over the surface layer of AI. Better chatbots. Faster outputs. Smarter agents. Viral demos. Cool screenshots for engagement farming on X. Same cycle every week. And look, I get it. That stuff grabs attention fast.
But here’s the thing.
AI doesn’t run on magic. It runs on data. Massive amounts of it. Human behavior, conversations, images, transactions, patterns, decisions, context. All of it feeds the machine. Yet the people contributing that informational layer usually disappear from the economic equation the second the model finishes training.
That’s the part people don’t talk about enough.
Right now the system works like this: platforms absorb data, models monetize intelligence, infrastructure owners compound value, and contributors basically walk away with nothing long term. Data acts like disposable fuel. One-time use. Burn it, extract value, move on.
I’ve seen this pattern before in tech.
Social media monetized attention while users created the content. Search engines monetized intent while people generated behavioral signals for free. AI’s pushing the same model even further now because informational extraction happens at a much deeper level once machine learning systems absorb everything into model weights.
And honestly? That structure probably doesn’t hold forever.
That’s where OpenLedger gets interesting.
The protocol seems less focused on chasing short-term AI hype and more focused on rebuilding the ownership layer underneath AI economies themselves. Big difference. Most projects want attention. OpenLedger looks like it wants infrastructure.
Those are not the same thing.
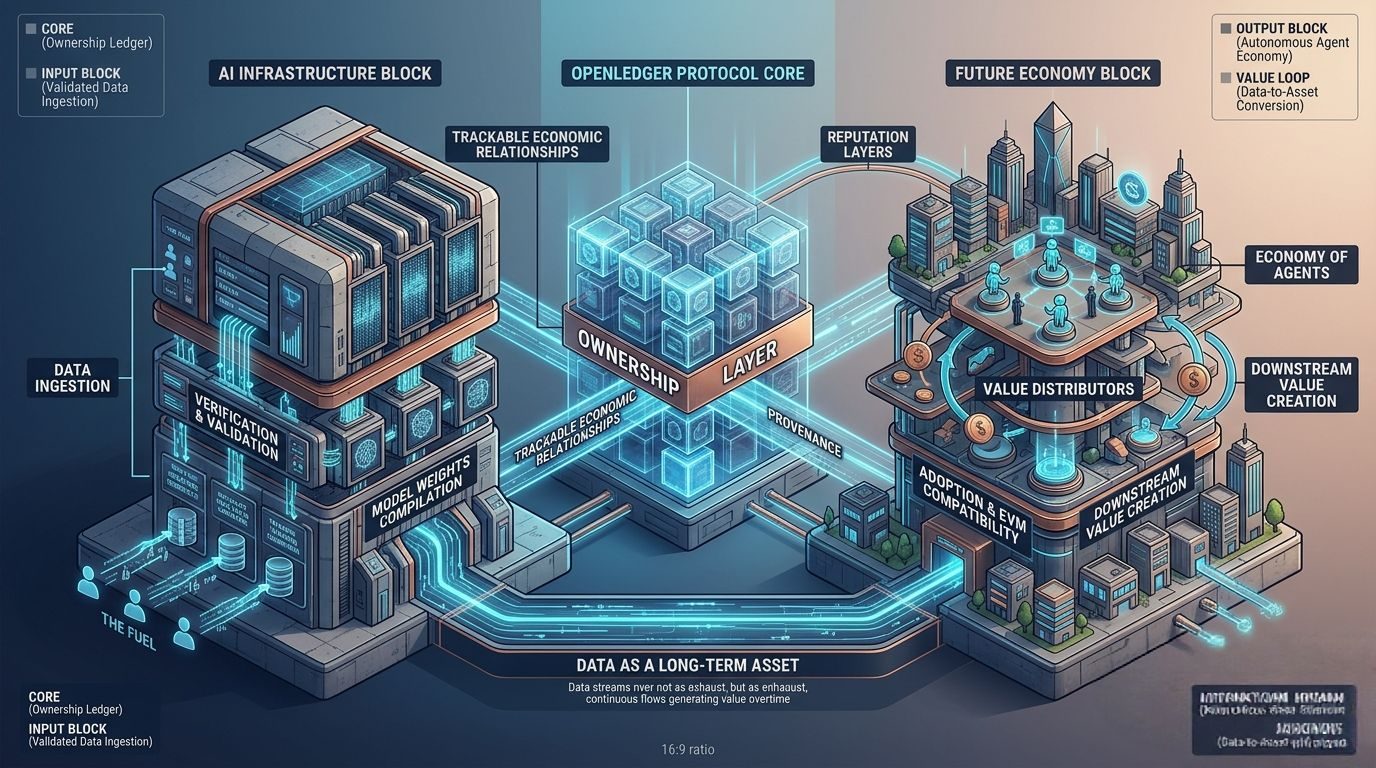
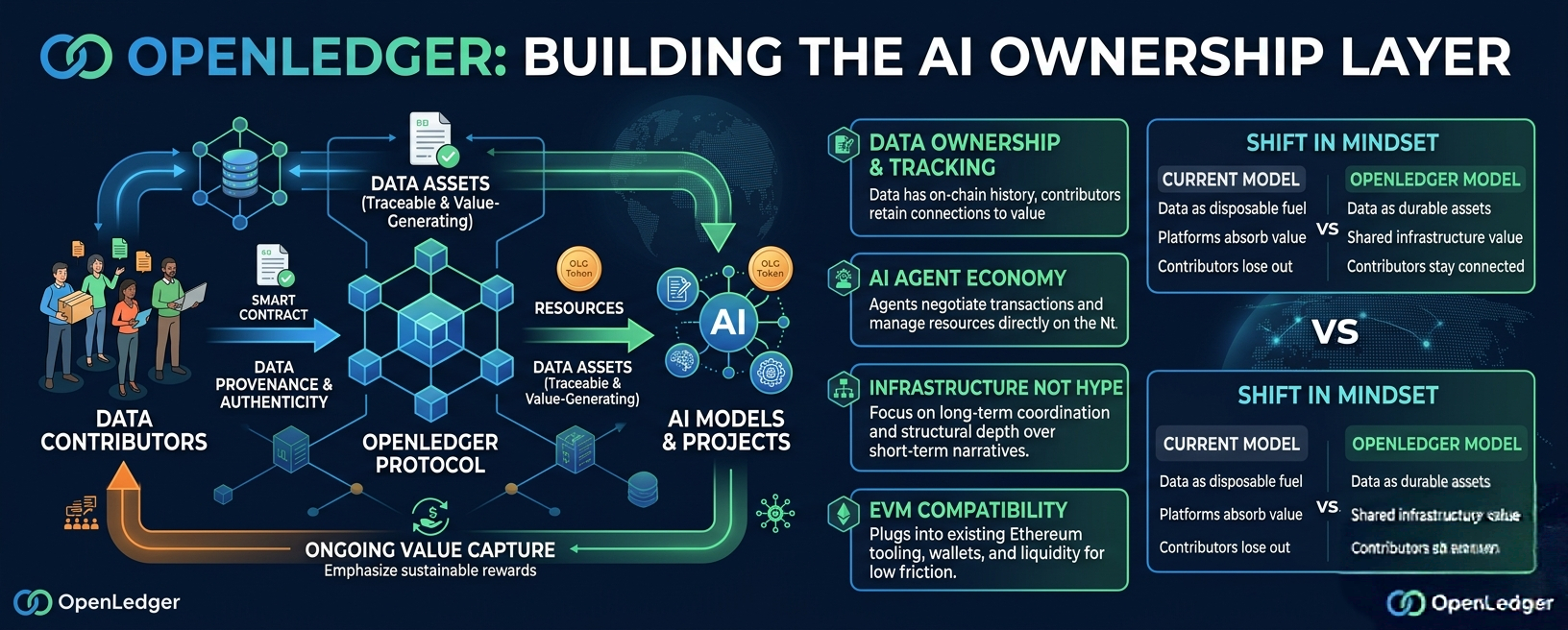
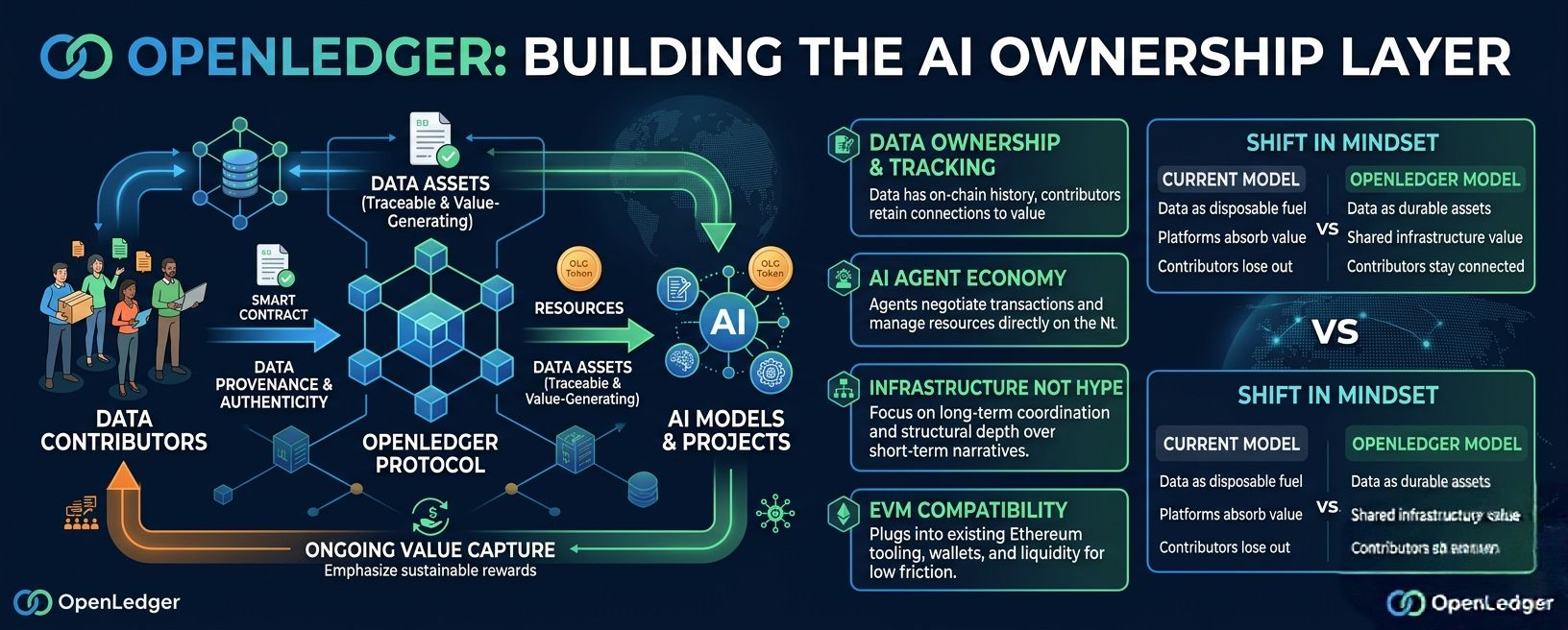
The core idea is actually pretty straightforward once you strip away all the crypto language. OpenLedger wants data to behave like an asset that keeps generating value over time instead of acting like a disposable input that loses all economic connection after ingestion.
Simple idea. Huge implications.
Because once you start tracking provenance on-chain, contributors don’t just vanish after supplying data. Their participation stays economically visible inside the network. That creates a very different relationship between models, datasets, contributors, and downstream value creation.
And look, provenance sounds boring until you realize how important it becomes at scale.
Everybody screams about model performance. Very few people ask where the data came from, who supplied it, whether the information quality remains reliable over time, or who captures upside once AI systems start generating serious economic output.
That conversation matters more than the flashy demos, honestly.
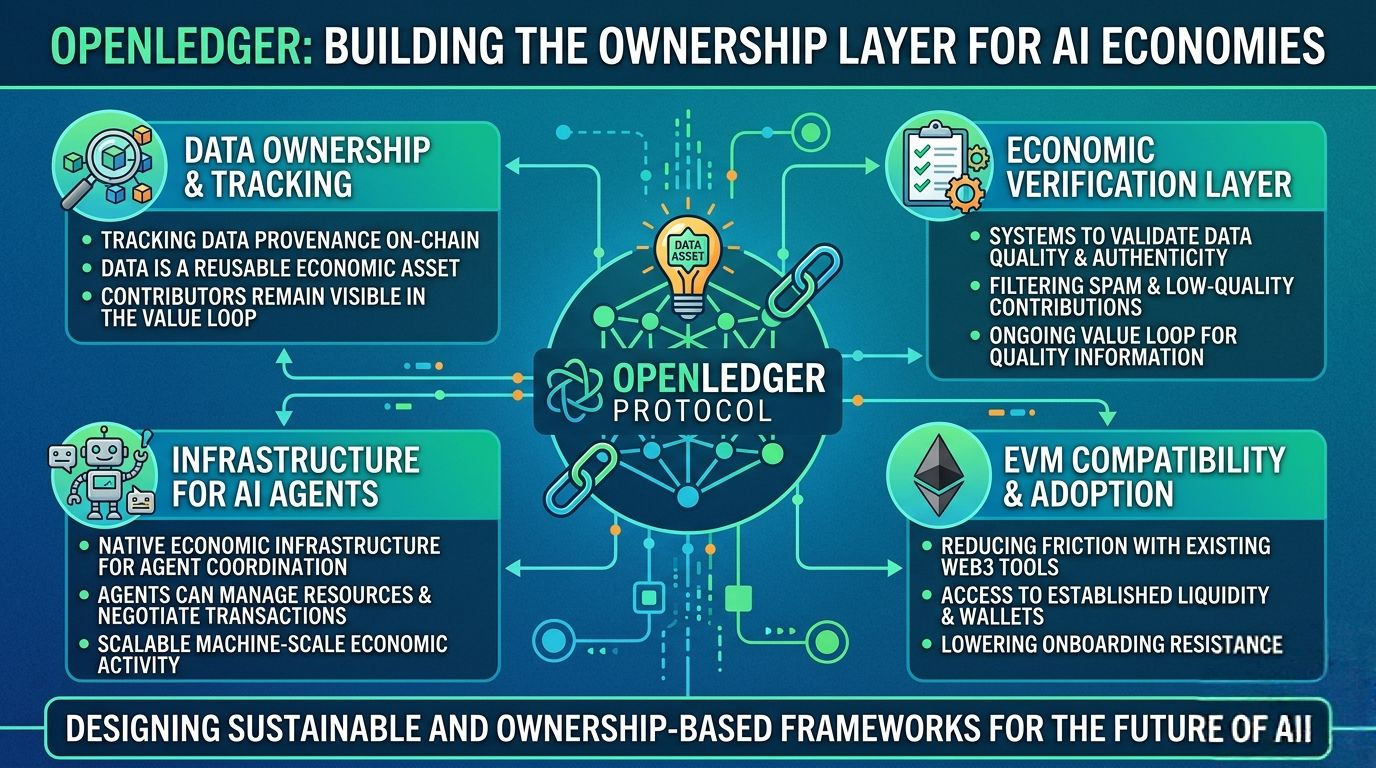
OpenLedger basically treats datasets, models, and AI activity as infrastructure components with traceable economic relationships attached to them. Instead of creating a dead-end extraction pipeline, the protocol tries to create an ongoing value loop where contributors remain connected to future monetization.
That’s a massive shift in mindset.
Because AI increasingly looks like a coordination problem, not just a compute problem.
Who supplies quality data?
Who verifies authenticity?
Who filters spam?
Who owns the outputs?
Who captures value once autonomous systems start interacting with each other continuously?
These questions get harder as AI scales. Not easier.
And I think that’s why OpenLedger’s architecture stands out to me. The blockchain part doesn’t feel bolted on for marketing. The chain actually functions as the accounting and ownership layer governing informational contribution itself.
That’s a much deeper use case than slapping tokens onto an AI app and calling it “decentralized.”
People throw around the word infrastructure constantly in crypto, but most projects really mean speculation wrapped in technical branding. Let’s be real. Markets reward narrative speed way faster than structural depth. Fast-moving AI stories pump hard because traders chase momentum, not coordination architecture.
Same thing happens every cycle.
Meanwhile the systems that actually matter long term usually build quietly underneath the noise until dependency forms around them. Cloud infrastructure worked like that. Ethereum itself worked like that for years. Even DeFi liquidity rails looked boring before the ecosystem suddenly depended on them.
I think OpenLedger might sit in that category.
Now the AI agent side makes things even more interesting.
Most people still frame agents as productivity tools. Automate a workflow. Run a task. Execute trades. Fine. But OpenLedger seems to push agents deeper into the economic layer itself. Agents don’t just use the network here. They participate directly inside it.
That matters a lot more than people realize.
Because once AI agents start coordinating services, negotiating transactions, accessing datasets, managing resources, or optimizing financial activity autonomously, they need native economic infrastructure underneath them. Otherwise you’re forcing machine-scale coordination into systems originally designed for humans manually clicking buttons and signing transactions one at a time.
That obviously breaks at scale.
And honestly, I think people underestimate how important OpenLedger’s EVM compatibility is too. It sounds less exciting than all the AI narrative stuff, but practical adoption usually depends on reducing friction, not maximizing novelty.
Developers already use Ethereum tooling.
Users already hold EVM wallets.
Liquidity already exists across EVM ecosystems.
Smart contracts already orbit that environment.
So instead of forcing people into some isolated experimental system, OpenLedger plugs directly into infrastructure the broader Web3 market already understands. That lowers onboarding resistance immediately.
Convenience wins more adoption battles than ideology ever will. Always.
But look, this is where things get tricky.
The protocol still faces real structural risks, and pretending otherwise would be dishonest.
The biggest issue probably comes down to quality control. The second you financially reward data contribution, people start gaming the system. Spam datasets appear. Sybil behavior expands. Low-quality informational noise floods the network. That happens in every open incentive structure eventually.
Always.
So OpenLedger’s long-term success probably depends on whether its validation systems, provenance mechanics, and reputation layers can filter garbage without making participation painfully restrictive. Hard problem to solve. Really hard.
Then there’s the incentive dependency issue.
A lot of contributors love the philosophy of “data ownership” while markets stay strong. But crypto history shows how fast ideological alignment disappears once volatility hits hard. People suddenly become transactional when token incentives weaken.
So the real question isn’t whether users support the vision during hype cycles.
The real question is whether the infrastructure remains economically useful when speculation cools down and attention rotates somewhere else.
And honestly, that’s probably the hardest test for any AI infrastructure project right now.
Because markets currently reward velocity over patience. Fast narratives outperform foundational systems constantly. AI speculation moves insanely fast. Infrastructure compounds slowly. Builders think in years while traders think in weeks.
OpenLedger sits directly inside that tension.
Still, I think the protocol is focused on the right problem set. And personally, I care more about that than short-term narrative spikes. The future AI economy probably can’t sustain infinite informational extraction forever while contributors remain economically invisible underneath centralized systems.
At some point ownership matters.
At some point provenance matters.
At some point people start asking who actually benefits once intelligence itself becomes programmable infrastructure.
And honestly, I think that conversation arrives faster than most people expect.