OpenLedger este unul dintre acele proiecte pe care nu vreau să le laud prea devreme.
Am văzut acest market reciclând aceeași prezentare de prea multe ori. AI. Date. Proprietate. Recompense. Decentralizare. Cuvintele încep să sune ca un zgomot după un timp, mai ales când jumătate din proiectele care le folosesc nu trec de o pagină de aterizare curată și câteva fire de discuție entuziaste.
Dar OpenLedger are o parte la care tot revin.
Se uită la partea urâtă a AI-ului pe care majoritatea oamenilor o evită încă: problema datelor.
Nu e problema „AI are nevoie de mai multe date”. Toată lumea spune asta. Partea asta e evidentă.
Problema reală este cine este plătit când acele date încep să creeze valoare.
În acest moment, AI se simte ca o mașină uriașă care mănâncă tot ce-i iese în față. Scriere umană, cercetare, note de piață, cod, muncă de creator, cunoștințe din comunitate, postări aleatorii, seturi de date curățate, seturi de date zgomotoase, totul. Totul intră. Modelul devine mai inteligent. Produsul se vinde. Contributorul de obicei nu primește nimic.
Asta e fricțiunea.
Și, sincer, aici începe să aibă sens ideea OpenLedger. Încercă să construiască un sistem în care datele nu dispar doar într-un model AI ca fumul. Proiectul vrea ca datele să aibă o urmă. O sursă. O înregistrare. O dovadă de vreun fel care să spună, da, această contribuție a avut importanță.
Asta sună simplu până când te gândești efectiv la ea.
Atribuirea AI nu e o problemă ușoară. E complicată. Modelele sunt complicate. Influența datelor nu e întotdeauna curată. O bucată de informație poate modela un output direct. Alta poate doar să îmbunătățească modelul în fundal. Unele date sunt utile. Unele sunt gunoi. Unele sunt copiate din materiale copiate. Unele par valoroase până încerci să le folosești.
Asta e munca grea cu care OpenLedger trebuie să facă față.
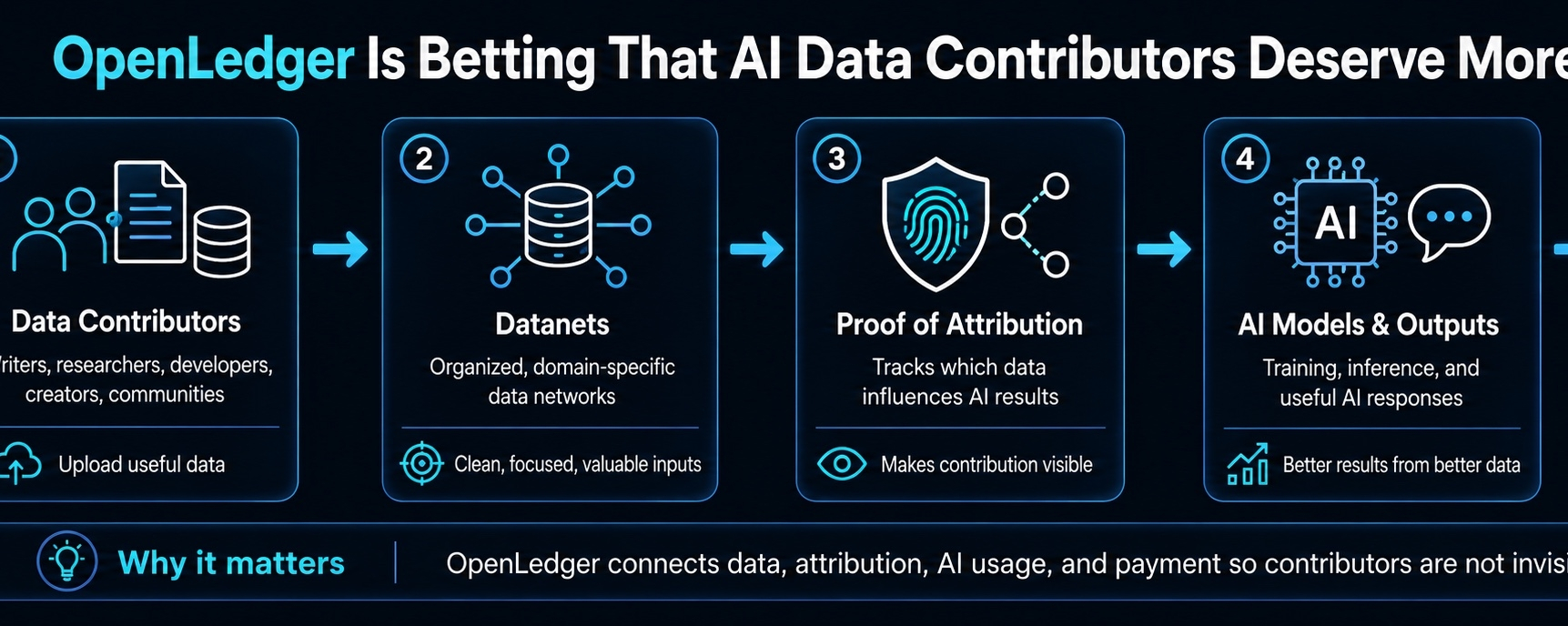
Proiectul folosește Prova de Atribuire ca idee centrală. Scopul este să urmărească cum contribuie datele la output-urile AI și apoi să conecteze acea contribuție la recompense. Îmi place direcția. Nu o să mă prefac că e deja rezolvat, pentru că asta ar fi lene. Dar cred că aceasta este întrebarea corectă de pus.
Dacă datele tale ajută un model AI să devină mai bun, de ce ești invizibil?
Asta lovește.
Pentru că economia actuală a AI este construită în mare parte pe contributorii invizibili. Oamenii creează cunoștințe, platformele captează valoarea, iar restul sunt informați că așa funcționează progresul. Am văzut același lucru și în crypto. Utilizatorii bootstrap rețele, comunitățile creează atenție, contributorii timpurii duc greutatea, apoi câștigul se concentrează în tăcere în altă parte.
Sector diferit. Aceeași bătaie de cap.
OpenLedger încearcă să se opună acestei situații transformând contribuția de date într-un lucru măsurabil și recompensabil. Nu doar „upload și speră”. Nu doar farming de puncte goale. Versiunea mai puternică a acestui proiect este acolo unde datele utile pot fi urmărite, clasificate, folosite și plătite pe baza impactului real.
Asta e versiunea de urmărit.
Versiunea mai slabă e ușor de imaginat. O inundație de upload-uri de slabă calitate. Oameni care urmăresc recompense. Seturi de date devin zgomotoase. Atribuirea devine prea complexă pentru utilizatorii normali. Constructorii apar pentru stimulente și pleacă când recompensele se usucă.
Am văzut acel film.
Așadar, testul real nu e dacă OpenLedger are o idee bună. O are.
Testul real este dacă sistemul poate separa semnalul de gunoi.
De aceea contează Datanets. OpenLedger folosește Datanets ca rețele de date concentrate în loc să arunce totul într-un morman uriaș. Acea parte se simte practică. AI nu are nevoie de date aleatoare nesfârșite. Are nevoie de date curate, utile, specifice care chiar îmbunătățesc output-ul.
Un model AI crypto are nevoie de informații native în crypto.
Un asistent de trading are nevoie de o structură reală de piață.
Un model de cercetare are nevoie de un context curat.
Un instrument pentru constructori are nevoie de date tehnice care să nu devină învechite după trei luni.
Datele proaste nu sunt doar inutile. Sunt scumpe. Pierd timp, adaugă zgomot și fac modelul mai rău.
Așadar, dacă OpenLedger poate face Datanets utile, asta devine stratul de bază real. Nu cuvintele fancy. Nu narațiunea. Calitatea datelor.
Privesc și cum se integrează contributorii în asta.
Cele mai multe proiecte vorbesc despre comunitate ca și cum ar fi o decorație. Modelul OpenLedger depinde de faptul că contributorii sunt de fapt valoroși. Oamenii aduc date. Ei ajută la organizarea lor. Ei sprijină rețeaua. Devine parte din lanțul de valoare AI în loc să rămână în afara lui, aplaudând în timp ce altcineva monetizează munca lor.
Asta e ideea, cel puțin.
Și este una bună.
Dar nu mai ofer încredere gratuită.
Un proiect ca acesta trebuie să dovedească că contributorii pot câștiga ceva semnificativ, nu doar praf simbolic. Trebuie să dovedească că constructorii vor să folosească stratul de date. Trebuie să dovedească că atribuirea poate funcționa într-un mod care să nu devină o altă cutie neagră cu un branding mai frumos.
Pentru că dacă utilizatorii tot nu înțeleg cum se mișcă valoarea, atunci întregul lucru începe să pară prea familiar.
Tokenul OPEN stă în acea tensiune.
Dacă ecosistemul crește, dacă Datanets devin utile, dacă constructorii AI se integrează efectiv, dacă contribuția de date creează o cerere reală, atunci tokenul are un motiv să conteze. Dar dacă activitatea este subțire și povestea rămâne mai mare decât utilizarea, piața se va sătura în cele din urmă.
Așa se întâmplă întotdeauna.
Narațiunile pompează întâi. Utilizarea este verificată mai târziu. Acea distanță este locul unde multe proiecte mor.
OpenLedger e interesant pentru că nu urmărește o problemă mică. Proprietatea AI va deveni o luptă mai mare, nu mai mică. Datele sunt deja valoroase. AI le face și mai valoroase. Și odată ce oamenii își dau seama că munca lor a ajutat la antrenarea unor unelte care acum concurează cu ei, conversația devine mai grea.
Cine deține inputul?
Cine câștigă din output?
Cine este șters în mijloc?
Asta e unde OpenLedger încearcă să se poziționeze.
Respect asta.
Nu pentru că sună curat, ci pentru că sună greu. Cele mai bune probleme în crypto sunt de obicei așa. Cele ușoare sunt copiate, reciclate și transformate în zgomot într-un singur ciclu. Cele dificile durează ani, îi ard pe oameni, și contează doar dacă cineva continuă să construiască prin partea plictisitoare.
OpenLedger încă trebuie să treacă prin acea parte plictisitoare.
Partea în care ideea întâlnește utilizatorii reali.
Partea în care recompensele trebuie să aibă sens.
Partea în care calitatea datelor este testată.
Partea în care constructorii decid dacă asta este util sau doar un alt strat pe care îl pot ignora.
Asta e ce urmăresc.
Pentru că dacă OpenLedger poate transforma datele din ceva ce AI consumă în ceva ce oamenii pot de fapt să dețină, să urmărească și din care să câștige, atunci are un adevărat drum.