There comes a point in every tech cycle when the language starts to smell a little too clean.
You hear it in pitch decks.
You see it in launch posts.
You can almost feel it in the wording.
Everything is “infrastructure.” Everything is “the future of ownership.” Every new project is apparently here to fix the internet, banking, gaming, AI, identity, labor, and maybe your Wi-Fi router too.
I am tired of that kind of talk.
So let’s talk about OpenLedger without dressing it up like a miracle.
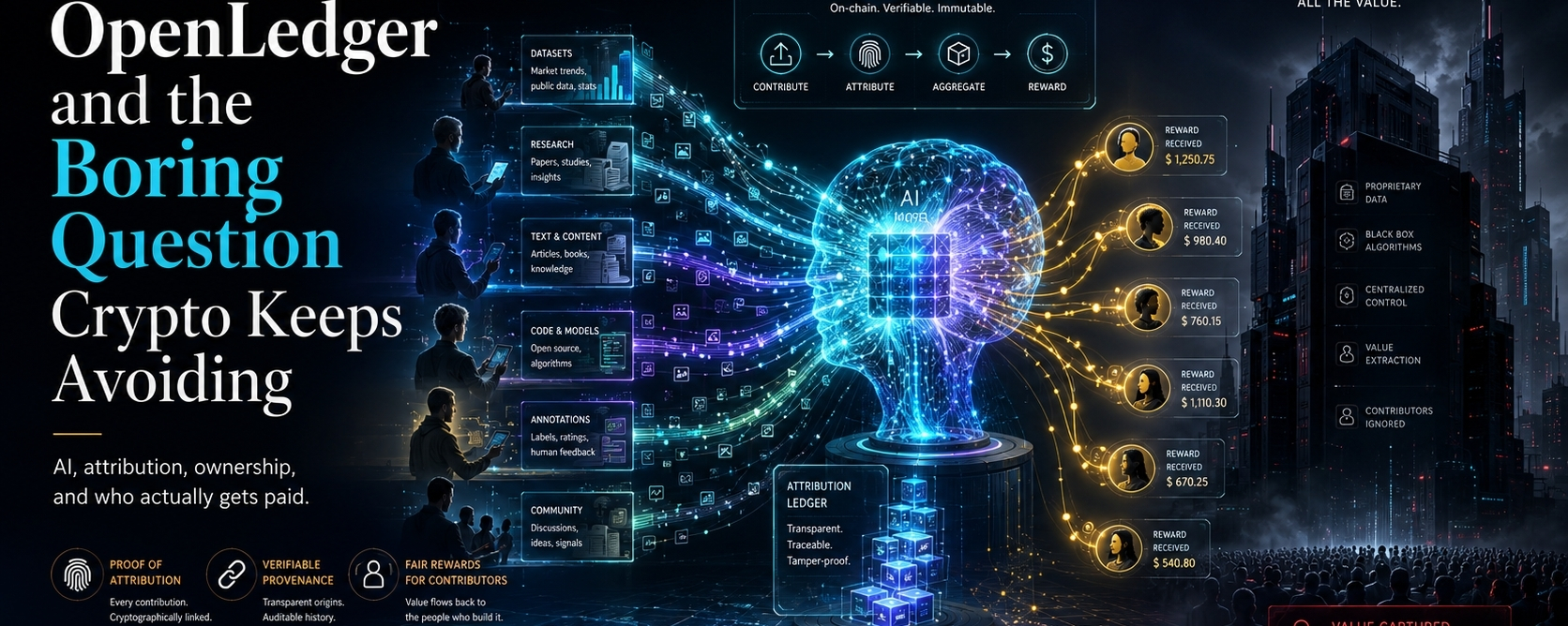
At the center of it, OpenLedger is trying to deal with a real problem in AI: people, data, and communities help create value, but once the machine starts producing useful results, most of those contributors disappear from the story. The model gets praised. The app gets users. The platform collects the money. The people who helped shape the system are treated like background noise.
That is the uncomfortable part.
OpenLedger’s bet is that this cannot go on forever. Not morally. Not economically. And maybe not legally either.
That is where the project becomes worth looking at.
Not because of the branding. Not because of the big words. Because of the plumbing underneath.
Features Are Cheap Now
A few years ago, launching an AI product felt impressive. Now, honestly, a lot of people can stitch together a chatbot, connect it to an API, add a clean dashboard, and call it a platform before the weekend is over.
That may sound rude.
It is also not far from the truth.
AI is full of features now. Upload this. Fine-tune that. Deploy an agent. Ask a model. Generate a workflow. Build a tool that summarizes your inbox, writes your posts, plans your day, and still somehow fails when you say, “Make it sound more human.”
Of course features matter. Bad software is still bad software. Nobody wants to use something clunky just because the idea behind it sounds clever.
But features are no longer enough.
The harder question is: who actually gets paid when the system works?
That is where OpenLedger starts to feel less like another AI tool and more like an attempt to build something deeper. It is not only asking people to build models, agents, or datasets. It is asking whether the people who contribute data, context, and improvements can be seen at all.
And being seen is not a soft issue.
In AI, being seen can mean money. It can mean ownership. It can mean leverage. It can mean the difference between helping build the machine and being quietly eaten by it.
AI Has a Memory Problem
AI systems can remember a lot.
They remember patterns. They remember styles. They can write code, explain legal documents, answer questions, imitate tones, and produce confident paragraphs even when they should probably slow down.
But most AI systems do not remember who they owe.
They do not clearly show which dataset helped shape an answer. They do not tell a contributor, “Your work made this model better, and now that model is earning money.” They do not usually send value back to the people whose knowledge made the system useful.
OpenLedger wants to put attribution closer to the middle of the machine.
Attribution sounds like a boring word. It feels like something from an academic paper or a copyright dispute. But in AI, it may become one of the most important economic questions of the next decade.
Because if AI keeps feeding on the internet, user behavior, expert knowledge, community data, and human creativity, then sooner or later someone will ask a very basic question:
Who owns the meal?
And “the platform owns it” may not be an answer people accept forever.
Proof of Attribution Is the Real Story
OpenLedger talks about Proof of Attribution. That is where the project becomes interesting.
Not because every crypto project that says “proof of something” deserves applause. Many do not. Crypto has spent years putting the word “proof” in front of ideas that did not need a token, a chain, or a dramatic manifesto.
We have seen that movie.
The ending was not always pretty.
But attribution in AI is not fake. It is a real problem.
If a dataset improves a model, that contribution should be traceable. If a model creates value because of certain training inputs, there should be some way to understand that influence. If people build useful data networks, they should not become invisible once the money starts moving.
That is the promise.
The hard part is making it work outside a nice diagram.
Attribution is messy. AI models are not simple machines where one input leads to one clean output. Influence can be indirect. Data overlaps. Quality is not always easy to measure. Some contributors will bring real value. Others will throw in junk and call it participation.
So the real question is not whether OpenLedger can say attribution matters.
Anyone can say that.
The real question is whether OpenLedger can make attribution useful enough that serious builders actually depend on it.
That is a much higher bar.
Datanets: Organized Human Effort, Basically
OpenLedger’s idea of Datanets is worth paying attention to.
A Datanet is basically a structured pool of data built around a specific purpose. Simple idea. Maybe almost too simple.
But simple does not mean weak.
Most AI data work is ugly behind the scenes. People clean things. Label things. check things. Remove bad entries. Add missing context. Fix weird edge cases. Bring in domain knowledge. Argue about what counts as quality. Then later, a smooth product demo appears and everyone acts like intelligence just fell from the sky.
It did not.
A Datanet makes some of that work more visible. At least that is the idea.
Imagine a group of people building a dataset around a narrow field: gaming behavior, DeFi risk, local farming, healthcare workflows, customer support, logistics, language translation, or anything else where context matters.
The point is not just “more data.”
We already have too much digital junk.
The point is better data.
Data that is more specific. More useful. More trusted. More connected to the real problem.
This matters because the next phase of AI probably will not be only about giant general models. Big models will still matter, yes. But a lot of valuable AI may be smaller, sharper, and trained around very specific needs.
The world does not only need one huge model that vaguely understands everything.
It needs systems that understand the work people are actually doing.
The Ownership Question Nobody Should Skip
This is where I become skeptical.
Crypto loves the word ownership. It may be one of the industry’s favorite words. Own your assets. Own your identity. Own your data. Own your game items. Own your digital life.
Sounds good.
But ownership only matters when things get difficult.
Can you leave? Can you transfer what you own? Can you earn without asking permission from the platform? Can the rules change overnight? Who controls the interface? Who controls the incentives? Who decides which data is valuable and which contributors get ignored?
These are not small questions.
If OpenLedger gives contributors real traceability and real economic participation, then it is doing something meaningful. But if it turns into another points-style game where users feed the system and wait for future rewards, then we have seen this story before.
Different logo. Same carpet.
The real test will come when the market is not excited anymore.
Bull markets make everything look smart. Bear markets ask better questions.
Why This Matters Outside the Crypto Bubble
The easy mistake is to file OpenLedger under “Web3 plus AI” and move on.
That category already has too much noise. Put AI and blockchain in the same sentence and suddenly people start producing sentences nobody would ever say at a kitchen table.
But the problem underneath is bigger than crypto.
AI is creating a value-distribution problem in many industries. Companies want better models. Developers want better tools. Users want useful products. But the people who provide data, expertise, feedback, and context are often pushed into the background.
Think about healthcare. A useful AI assistant may depend on medical knowledge, clinical patterns, and carefully structured information. Who gets credited?
Think about education. A learning model may be shaped by teachers, curriculum designers, students, and feedback loops. Who benefits?
Think about finance. Risk models rely on signals, historical behavior, and expert interpretation. Who owns the intelligence built from all that?
Right now, the answer is often simple:
Whoever controls the platform.
That answer may not age well.
OpenLedger is trying to suggest a different path: track the inputs, credit the contributors, and let value move back through the system.
I like the ambition.
I just do not trust ambition by itself.
What Builders Should Actually Learn From This
The first lesson is that data is not just raw material anymore. It is strategy.
Not all data. Most data is noise. But clean, specific, well-organized, high-signal data? That can become a real advantage.
The second lesson is that attribution should not be treated like a sticker added after launch. If trust matters, attribution has to be part of the system from the beginning.
The third lesson is that communities are not just audiences. They can help build intelligence. That may sound a little cold, but it is true. The better version is this: communities can help create useful systems and share in the upside.
The fourth lesson is more uncomfortable.
If your AI product depends on other people’s knowledge, behavior, writing, feedback, or data, and your plan is to keep all the value for yourself, you may be building on borrowed time.
Maybe regulators notice. Maybe users leave. Maybe competitors offer fairer incentive loops. Maybe nothing happens for a while.
That last one is usually how bad systems survive longer than they should.
The Next Five Years Will Be Less About Chatbots
I do not think the most important AI products of the next decade will all look like chat windows.
Some will. Many will not.
AI will move into workflows, agents, infrastructure, marketplaces, games, research tools, financial systems, and boring back-office processes nobody tweets about. It will become less visible and more powerful. And usually, when technology becomes less visible, accountability becomes more important, not less.
If OpenLedger is right, then the AI economy needs some kind of record layer. Not for ownership theatre. For real provenance. For payments. For trust. For knowing whether a model’s intelligence came from quality work or a giant pile of scraped noise.
But the risks are real.
Attribution can be gamed. Incentives attract farmers. Token rewards can twist behavior. Communities can become extraction zones with nicer branding. And if the product is too hard to use, only insiders will care.
That is the old crypto problem again.
The idea may be good. The system may still become painful to use.
The Hard Part Is Not Launching Tools
OpenLedger can launch products. It can build AI studios, model tools, data networks, attribution systems, and agent infrastructure.
Fine.
The hard part is making people believe the rules will hold.
That is what separates software from systems. Software can look great in a demo. A system has to keep working when incentives get ugly, users get clever, markets cool down, and attention moves somewhere else.
I keep coming back to that.
OpenLedger is not interesting because it says AI data should be monetized. Plenty of people say that.
It is interesting because it points toward a harder question:
Can we build AI systems that remember who helped make them valuable?
Because if we cannot, then the future of AI starts to look very familiar.
A few platforms own the rails.
Everyone else supplies the raw material.
Then we call it progress.
I would rather not.