Market felt slow today. Not the kind of slow where you step away — the kind where you end up going deeper into things you'd normally skim past.
So I started poking around OpenLedger. Not because I had a thesis. Just because the $OPEN narrative kept coming up and I wanted to understand what was actually underneath it.
Most people frame it as a payment problem. AI companies train on your data, you get nothing, OpenLedger fixes that. Fair enough. But I kept reading and something shifted. The payment problem isn't actually the deepest problem. The deeper problem is that contributors have no idea what their data was worth. They couldn't even ask the right question.
That's the part that stopped me.
When a contributor uploads a dataset to a Datanet on OpenLedger, and a developer trains a model on it, and that model gets used — the Proof of Attribution system logs what happened on-chain. Which data. Which model run. Which inference. Traceable. That's the mechanism. But what it's actually doing, quietly, is collapsing an information gap that nobody was really talking about.
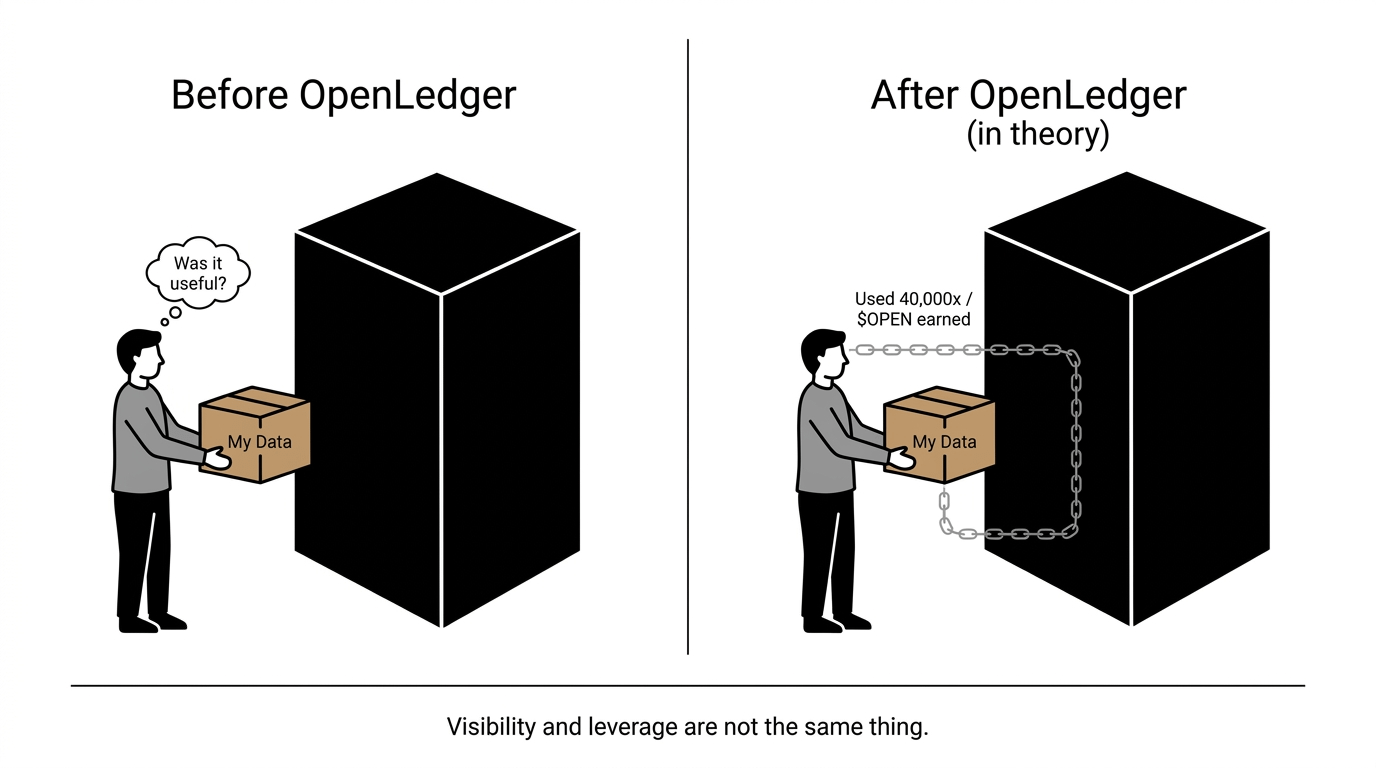
Right now, if you contributed training data to any of the large AI labs — hypothetically, through any of the scraping pipelines or licensing deals — you would have no way of knowing whether your data was noise or signal. Whether it showed up once or thousands of times. Whether it shaped a capability or got filtered out. The company knows. You don't. That's not just unfair, it's structurally disabling. You can't negotiate from a position you can't see.
I thought this was just about attribution rewards at first. It's not. It's about visibility into your own contribution's value — which is a completely different thing.
Because once that information is on-chain and readable, the dynamic changes in a direction people aren't quite accounting for. A contributor who can see that their domain-specific dataset triggered 40,000 inference calls last month is not the same contributor as someone who uploaded blindly and waited. One of them can make decisions. The other one just hopes.
But here's the part that bothers me.
Visibility doesn't automatically mean leverage. Knowing your data was valuable doesn't mean you can do anything about it. If the Datanets are open and the attribution records are public, a sophisticated data broker could read those records, identify what types of data generate the most downstream activity, and flood the network with optimized supply. The original contributors — the ones who built that signal before anyone was tracking it — don't suddenly get protected. They get competed with, this time by people who have the same information they do, but more resources to act on it.
So I'm not fully convinced the asymmetry actually flattens. It might just move. From "companies know, contributors don't" to "informed participants know, casual contributors still don't." Same structure, different players at the top.
I keep going back to the YouTube comparison that floats around in the OpenLedger documentation. YouTube gave creators visibility into views, watch time, revenue per thousand impressions. That transparency did help creators. It also helped creators with large production budgets, SEO consultants, and content farms optimize harder than individual people ever could. Transparency in a competitive system doesn't neutralize the competitive advantage of scale. It sometimes just makes the race more visible while leaving the finishing order mostly intact.
The question I can't resolve is whether OpenLedger's design actually accounts for this, or whether the Proof of Attribution layer is genuinely enough to shift outcomes for the kind of contributor the project is built around rhetorically — individual people, small teams, domain experts. There's something in the ModelFactory layer and the OpenLoRA fine-tuning structure that might matter here, but I haven't gotten far enough in to feel certain either way.
And the developer adoption problem sits underneath all of it. Attribution only means something if models are being trained and queries are being run. Right now the contributor economy is live but the downstream demand that would make attribution payouts real is still forming. People are building the road before the cars exist, which is normal for infrastructure, but it does mean the information asymmetry problem technically isn't solved yet — it's just been designed for.
Anyway. Still watching how this develops. The idea feels right even if the execution has a ways to go.
@OpenLedger #OpenLedger $OPEN