I’ve been watching the AI + crypto space for a while, and one thing keeps standing out: the entire market is almost hypnotized by the surface layer. Everyone is talking about which model is more powerful, which agent is more autonomous, and which token is pumping fastest.
But the deeper I look, the more I believe the real battle isn’t happening at the inference or chatbot level. It’s happening much lower, at the invisible infrastructure layer where data is created, attributed, valued, and ultimately captured.
This is precisely why OpenLedger started to stand out to me.
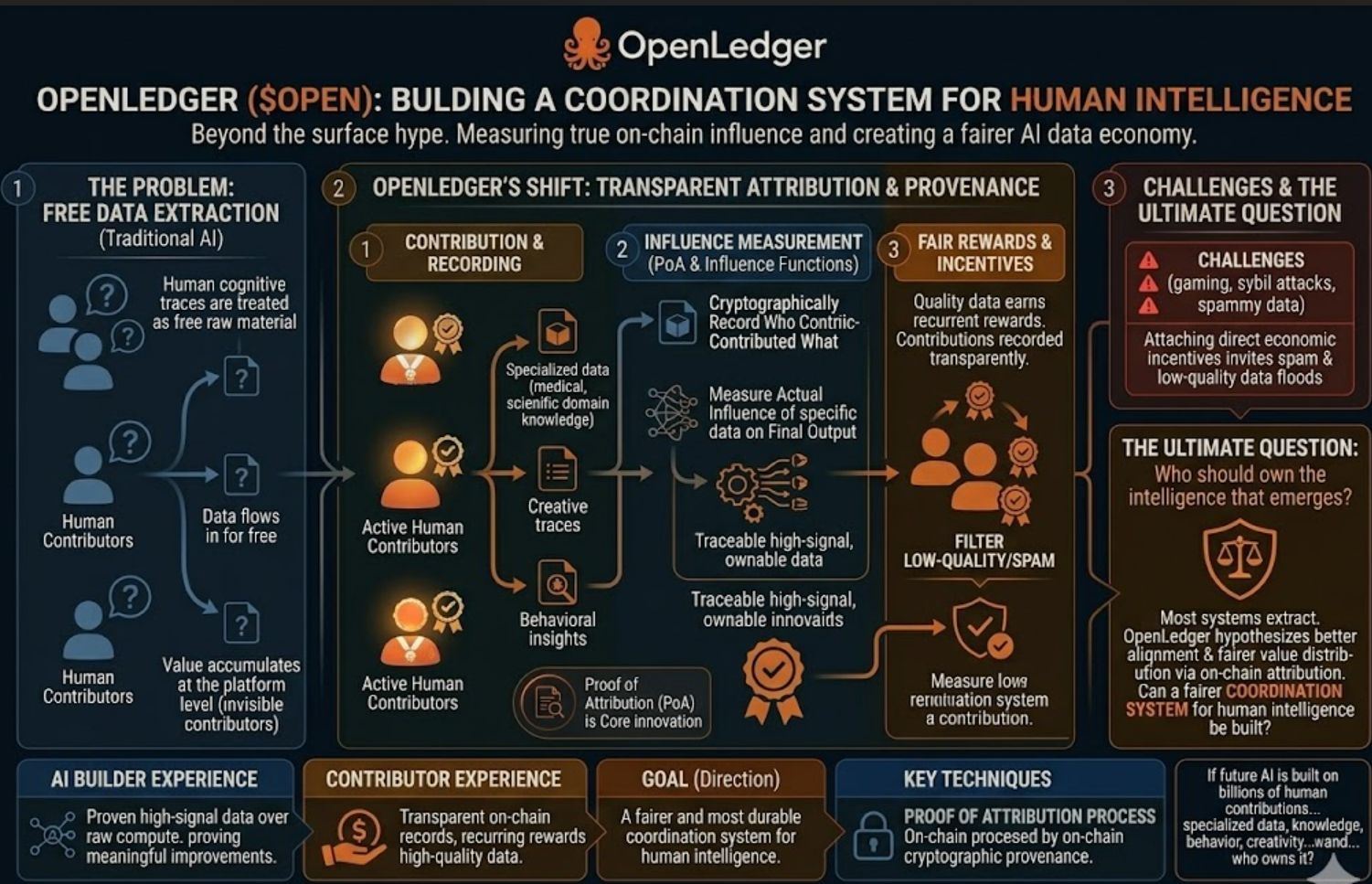
Rather than building just another AI application or agent framework, OpenLedger is attempting something more fundamental: turning data contribution, model refinement, and inference activity into true on chain economic primitives. Using their Proof of Attribution system, they cryptographically record who contributed what data and crucially, measure the actual influence that data had on the final output through influence functions. This creates verifiable, transparent provenance on chain.
For developers and AI builders, this is a meaningful shift. In a world increasingly flooded with synthetic data, being able to prove “this specific dataset meaningfully improved the model” becomes extremely valuable. It moves the conversation from raw compute power to traceable, high signal, ownable data.
For regular contributors, the experience also feels different. Instead of feeding data into a black box centralized model and receiving nothing in return, participants can see their contributions recorded transparently. Quality data has the potential to earn recurring rewards, while low quality or spammy inputs can be filtered through reputation and scoring mechanisms.
However, this approach comes with serious challenges. When you attach direct economic incentives to data contribution, you immediately invite spam, gaming, sybil attacks, and low quality synthetic data floods. Blockchain can perfectly record provenance, but determining the true “meaning” and quality of data at scale is an incredibly hard coordination problem. AI data economies risk becoming the next version of content farms and SEO spam, except on a much larger scale.
#OpenLedger appears to understand this tension. Their architecture focuses heavily on the attribution layer, provenance tracking, and economic coordination rather than just flashy agent demos. Still, no one has fully solved these problems yet.
The bigger, more uncomfortable question that lingers is this: If the future of AI is built on billions of human contributions, our knowledge, behavior, creativity, and specialized data, then who should actually own the intelligence that emerges from it?
Most current systems operate on pure extraction: data flows in for free, value accumulates at the platform level, and contributors remain invisible. @OpenLedger offers a different hypothesis, that transparent, on chain attribution could create better incentive alignment and fairer value distribution.
Whether this vision can survive real world pressures (spam, gaming, legal ambiguity around data ownership) remains to be seen. But the direction feels important. In a tokenized AI future, the real competition may not be about who builds the smartest model, but who builds the fairest and most durable coordination system for human intelligence.
Because ultimately, AI isn’t built by compute alone. It’s built from the collective cognitive traces of millions of people. The question of who gets to own and benefit from that intelligence may define the next era of the internet.

