The intersection of Artificial Intelligence and decentralized networks has seen immense growth, yet a persistent bottleneck remains scalability and fair resource allocation. Most general-purpose Layer-1 networks fail when processing data-heavy machine learning workflows. This is exactly where the team at OpenLedger is stepping in to change the game, establishing a purpose-built execution layer tailored specifically for verifiable AI data, fine-tuned models, and autonomous on-chain agents.
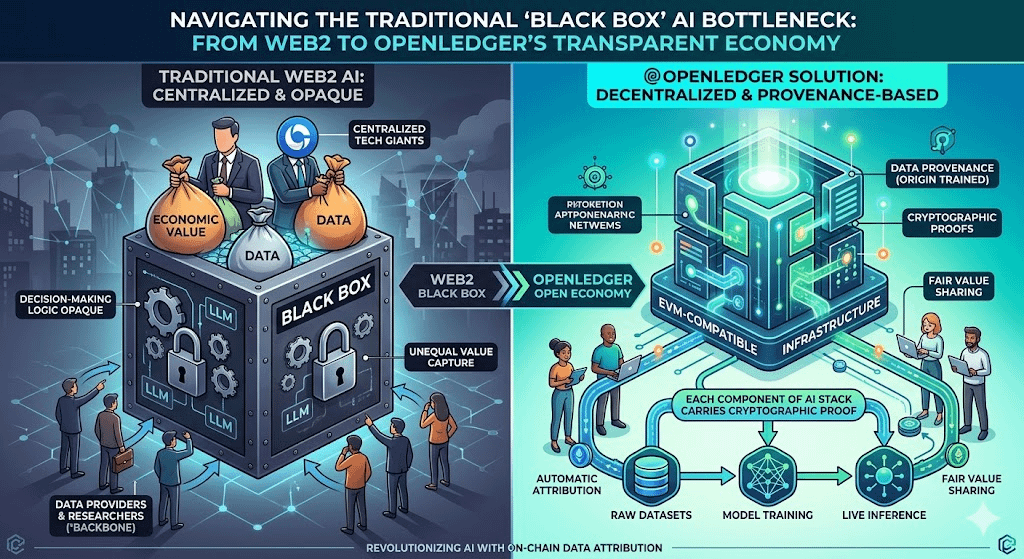
Navigating the Traditional "Black Box" AI Bottleneck
In traditional Web2 setups, data providers and independent model researchers form the backbone of ML innovation, yet centralized tech giants capture the bulk of the economic value. Furthermore, the decision-making logic of these large language models (LLMs) remains completely opaque.
By building an EVM-compatible infrastructure optimized for data provenance, OpenLedger ensures that every component of the AI stack—from the initial raw datasets to live inference—carries cryptographic proof and automatic attribution.
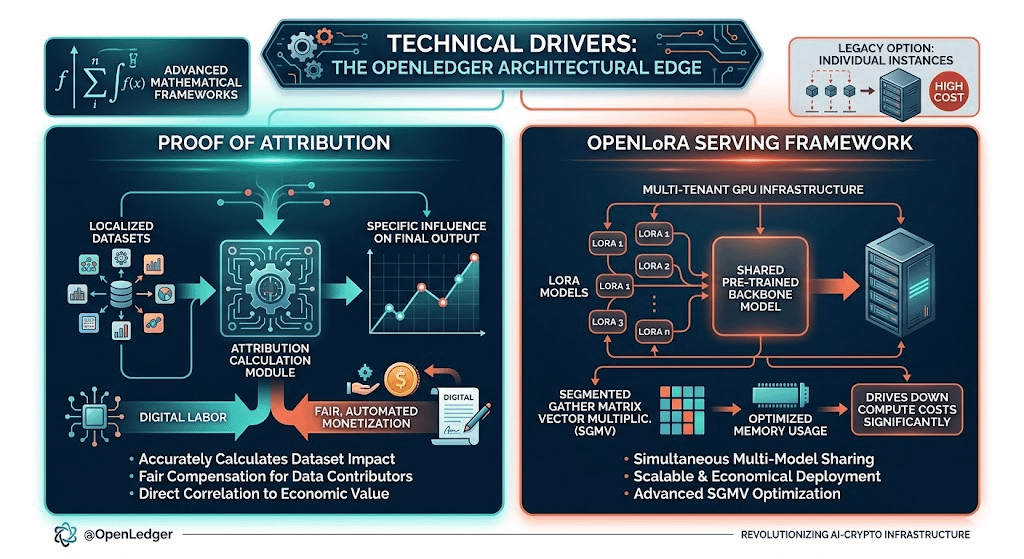
Technical Drivers: Proof of Attribution and OpenLoRA
Two major architectural developments set the project apart in today's crowded AI-crypto landscape:
Proof of Attribution: Using advanced mathematical frameworks, the network accurately calculates the specific influence a localized dataset has on a model's final output. This bridges the gap between digital labor and fair, automated monetization.
The OpenLoRA Serving Framework: Deploying isolated hardware instances for thousands of fine-tuned models is economically unfeasible. OpenLedger utilizes a multi-tenant GPU infrastructure that allows specialized low-rank adaptation (LoRA) models to seamlessly share a single pre-trained backbone model simultaneously. Technologies like Segmented Gather Matrix Vector Multiplication (SGMV) optimize memory usage, driving down compute costs significantly compared to legacy options.
Understanding the Role of $OPEN Ecosystem Tokenomics
The utility of the network is deeply anchored by its native token, OPEN. Within this expanding machine economy, the token functions as a vital incentive mechanism:
Data Sourcing & Staking: Data providers within the ecosystem stake OPEN to guarantee data quality and maintain network integrity.
Fee Redistribution: When AI applications trigger an inference, a portion of the fee is automatically distributed to model creators, validators, data contributors, and stakers.
Supply Sustainability: Out of the capped 1 billion supply, over 61% is strictly earmarked for the community and long-term ecosystem growth, ensuring a community-first structure.
As we see a macro shift from general internet search assistants toward specialized, auditable, and sovereign domain-specific AI models, establishing a transparent asset ledger is crucial. By transforming AI models into ownable, verifiable on-chain assets, #OpenLedger is building a foundation that could very well replace centralized hubs and power the next wave of decentralized intelligence.
Keep an eye on @OpenLedger as they continue to roll out deeper integrations with decentralized compute networks to scale this sovereign data economy.