I was thinking about @OpenLedger from the opposite direction today.
Usually, when people discuss AI blockchain projects, they start with the opportunity. Data becomes monetizable. Models become assets. Agents become economic actors. Liquidity enters places where value used to be trapped. That is an interesting thesis, and it is part of why $OPEN keeps appearing in conversations around AI infrastructure.
But the more useful question may be less comfortable: what could slow this down?
Not because the idea is weak. Actually, the opposite. Strong infrastructure ideas often fail or move slowly when they collide with existing behavior, regulation, cost structures, and institutional habits. So instead of treating #OpenLedger like a finished answer, it may be better to ask what has to go right before it becomes widely used.
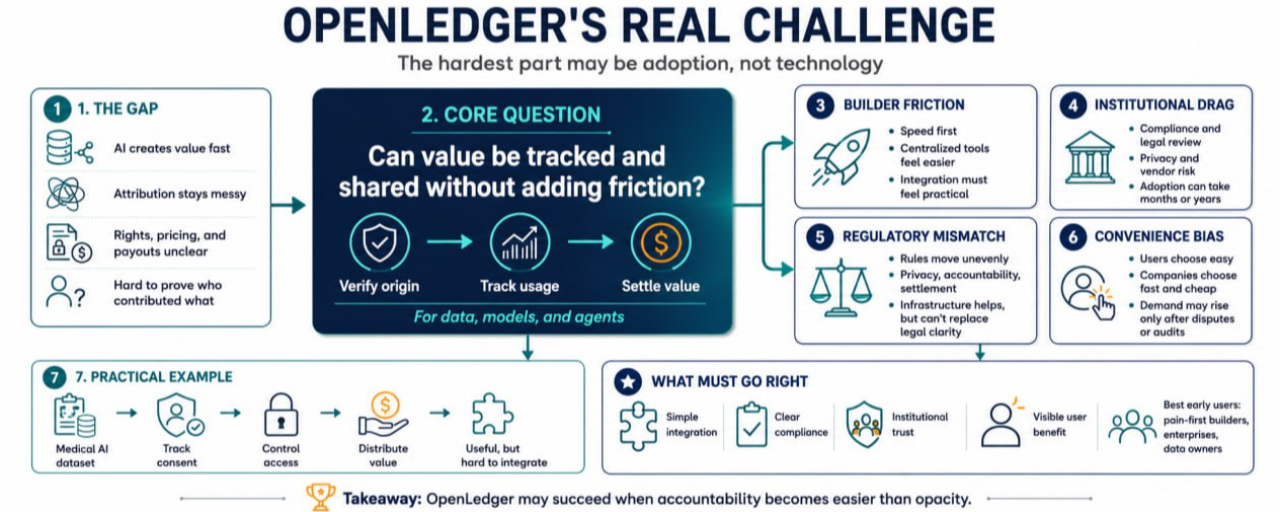
The Problem Before OpenLedger
AI is already spreading through business workflows, but the economic layer around it is messy.
A company may use third-party data, fine-tune models, deploy agents, and automate decisions without having a clean way to track who contributed what. Users often do not know how their data is used. Builders may not know how to price AI assets. Institutions may want better audit trails but hesitate to expose sensitive operations. Regulators are still trying to understand where responsibility begins and ends.
This creates a strange gap. AI can create value quickly, but proving where that value came from is much harder.
OpenLedger’s focus on unlocking liquidity to monetize data, models, and agents speaks directly to that gap. Still, having the right problem does not guarantee easy adoption.
Risk One: Builders May Avoid Extra Friction
Builders usually care about speed first.
If a developer can ship an AI app using a centralized API, a simple database, and a payment provider, they may not immediately care about deeper attribution or settlement. Early-stage teams are often fighting for users, not designing perfect economic infrastructure.
This is a real adoption risk for OpenLedger. Even if verifiable data flows and monetization rails are useful, builders need them to feel practical. If integration feels heavy, documentation feels unclear, or benefits arrive too late, many teams may postpone using it.
The challenge is not only technical. It is behavioral. People adopt infrastructure when it removes pain they already feel.
Risk Two: Institutions Move Slowly
Institutions may need OpenLedger-like infrastructure, but they are rarely fast adopters.
Banks, insurers, healthcare firms, universities, logistics companies, and public agencies care about compliance, procurement, legal review, vendor risk, data privacy, and internal approval. Even when the benefits are obvious, implementation can take months or years.
For institutions, the promise of monetizing AI data flows is not enough. They need confidence that the system can meet audit standards, security requirements, reporting obligations, and regulatory expectations.
This is where @OpenLedger has to be more than an interesting network. It has to become boring in the best possible way: reliable, understandable, and easy to justify inside a risk committee.
Risk Three: Regulators May Not Move in Sync
AI regulation is still uneven.
One jurisdiction may focus on privacy. Another may focus on model accountability. Another may care about financial settlement, consumer protection, or data localization. For a system that deals with AI assets, data rights, agent activity, and value distribution, this creates a complex environment.
OpenLedger could help by making flows more transparent and traceable. But regulators may still disagree on what counts as acceptable proof, lawful data use, or fair compensation.
That uncertainty can slow adoption. Institutions may wait for clearer rules before committing deeply. Builders may avoid regulated use cases. Users may remain skeptical if they do not understand how their rights are protected.
Infrastructure can support compliance, but it cannot replace legal clarity.
A Practical Example: A Medical AI Dataset
Imagine a company wants to build an AI tool that helps clinics analyze patient intake forms.
The data has value. The model has value. The agent that routes cases has value. But the risks are serious. Patient privacy must be protected. Consent must be clear. Access must be controlled. If the tool improves outcomes or reduces costs, there may be questions about who benefits financially.
OpenLedger-style infrastructure could help track permissions, usage, and value distribution. That would matter to builders, institutions, users, and regulators.
But adoption would still be difficult. Healthcare organizations may worry about compliance exposure. Lawyers may question whether the settlement model fits existing rules. Patients may not trust vague promises about data monetization. Integration with old systems may be expensive.
So the value proposition is real, but the path is not automatic.
Risk Four: The Market May Prefer Convenience
The biggest risk may be that many people say they want transparency, but choose convenience.
Users click through terms they do not read. Companies choose tools that are cheaper and faster. Builders optimize for launch speed. Institutions often delay infrastructure changes until risk becomes unavoidable.
That does not mean OpenLedger cannot work. It means demand may grow gradually, especially after disputes, audits, or regulatory pressure make opaque AI systems more costly.
In other words, the need for OpenLedger may become obvious only when the current way of building AI starts breaking under real-world pressure.
Grounded Takeaway
The most likely early users of OpenLedger may be builders who already feel the pain of AI attribution, data monetization, agent settlement, or institutional compliance. It may also appeal to data owners who want compensation, enterprises that need auditability, and teams building AI workflows where trust matters more than speed alone.
It might work if #OpenLedger makes verification and value distribution feel simpler than managing private agreements, manual audits, and unclear ownership records. It could fail or move slowly if integration is too difficult, regulations remain confusing, or users and companies keep choosing convenience over accountability.
That is why I see $OPEN less as a simple AI narrative and more as a test of market behavior. Do people only want smarter AI, or do they also want AI systems that can prove how value is created and shared?
Not financial advice.
What do you think is the biggest barrier for OpenLedger: regulation, builder adoption, institutional trust, or user awareness?