我自己训的AI模型被人刷了两万次假调用,云账单到现在还挂在我支付宝里。那之后我一直在想一个问题:数据明明是我们自己一条一条产生的,为什么用得起它的偏偏是那些大厂?就是带着这点疑问,我把OpenLedger的白皮书和路线图打印出来交叉读了两遍,发现它想干的事,比我预想的要具体得多。
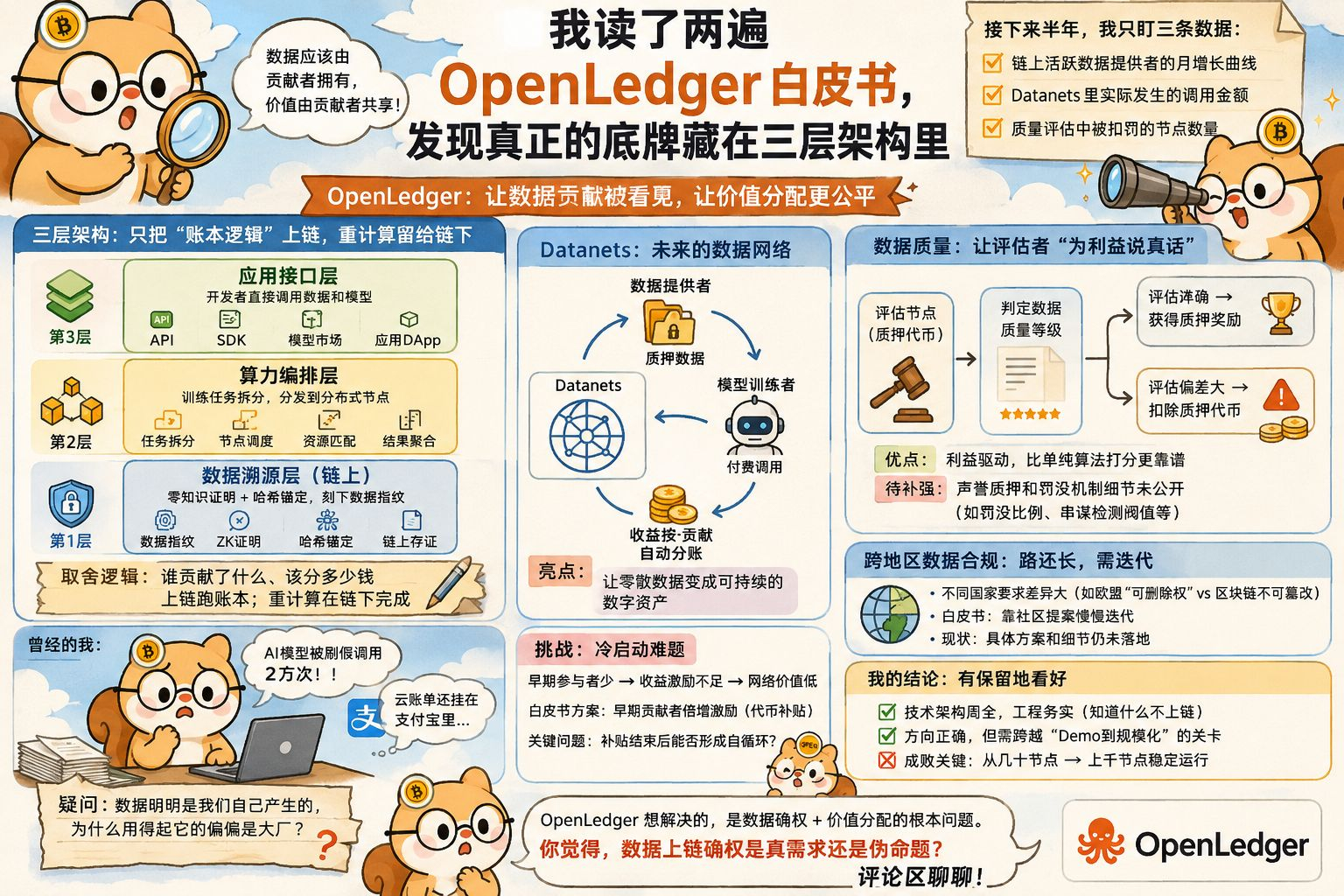
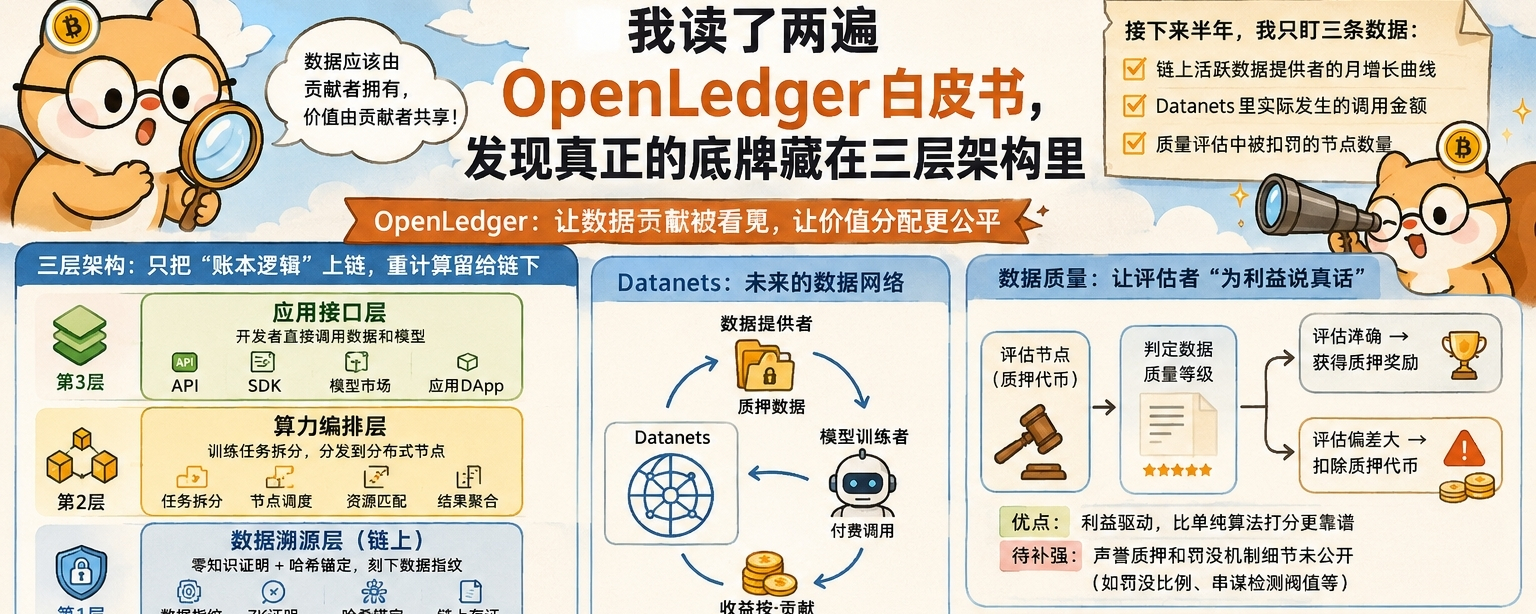
读第一遍的时候我其实没太进入状态,因为市面上太多项目把“数据确权”当口号喊。但第二遍读到“可验证数据贡献证明”那部分时,我开始认真了。@OpenLedger 它把整件事拆成了三层来看。底层管数据溯源,用零知识证明和哈希锚定把你的数据指纹刻在链上,别人能验证这数据确实是你产生的,但看不到原始内容。这点我觉得想得很细,因为企业级用户最怕的就是数据裸奔。再往上一层是算力编排层,负责把训练任务拆碎了分发给分布式节点。最上面才是应用接口,让开发者直接调取数据和模型。三层拆完之后我突然明白了它的取舍逻辑:OpenLedger没有天真到想把整个AI训练流程全部搬上链,那个根本不现实,光是梯度同步的通信开销就能把网络堵死。它走的是一条务实得多的路,只把“谁贡献了什么、该分多少钱”这些账本逻辑放在链上跑,真正的重计算还是在链下完成。你想想,去房管局登记,人家只认你那本产权证,什么时候让你把整栋楼搬过去过?
路线图里规划的Datanets让我既兴奋又有点拿不准。按项目的设想,未来不同领域会形成各自的数据网络,医疗影像一块、金融交易一块,数据提供者把数据质押进去,模型训练者付费调用,收益按贡献自动分账。这个模式要是跑通了,确实能让普通人手里的零散数据变成可以持续产生价值的数字资产。但我反复看了他们目前落地的节点规模,说实话心里还是会多想一想。现在Datanets主要集中在三四个垂直领域,节点数量和白皮书里画的理想规模还有一段距离,这让我忍不住琢磨冷启动这个循环难题到底怎么破。数据网络的价值高度依赖参与者数量,但早期参与者能拿到的收益激励又还不太够。白皮书里提到正在测试“早期贡献者倍增激励”机制,用代币补贴冷启动阶段的数据提供者,这个思路倒不新鲜,关键是补贴阶段结束后能不能形成自循环。写到这儿我其实还在权衡,因为方向确实对,但时间表这东西,币圈老人都懂,中间变数不少。
有个让我觉得OpenLedger想得比较深的地方是它对“数据质量”的处理。以前这类项目最容易出问题的点就是,大家为了获取激励传一堆低质量数据上去,整个网络被无效数据占据。白皮书里设计了一套质量评估机制,让评估节点用代币质押去判定某批数据的质量等级,评估准确就获得质押奖励,偏差太大被扣除质押的代币。这招有意思的地方在于,它让评估者为了自己的利益去说真话,而不是靠道德自觉,比单纯靠算法打分要靠谱得多。但这套机制也有需要补强的地方,白皮书里提了一句“声誉质押和罚没机制”,但具体参数比如罚没比例、串谋检测阈值都没公布。我有段话在文档里标了高亮,就是关于如果评估者串通作恶怎么办,这部分白皮书没有展开,希望后续技术文档能补上。
还有个地方我看了三遍也还在消化,就是跨地区数据合规那块。不同国家对数据的要求差异太大了,欧盟要求数据能删除,但区块链天然不可篡改,这俩怎么找到平衡点?白皮书里说靠社区提案慢慢迭代,但具体方案现在还没看到细节。这个不是OpenLedger一家的问题,整个赛道都在摸索,我只是觉得如果这块不先跑通一个最小可行方案,大规模采用会面临不小的挑战。
总的来说,我对这个项目的态度是有保留地看好。它在技术架构上确实比大多数同行想得更周全,尤其在“什么东西不上链”这个问题上表现出了难得的工程务实性,这一点在容易热闹的赛道里挺加分的。但它的成败最终不取决于白皮书写得多漂亮,而在于能不能跨过从“几十个节点跑通Demo”到“上千节点稳定运行”这道关口。
我已经把$OPEN 放进观察清单,接下来半年只盯三个数据:链上活跃数据提供者的月增长曲线、Datanets里实际发生的调用金额、质量评估中被扣罚的节点数量。如果这三条线都能走出实实在在的上扬趋势,我会考虑提升关注力度。毕竟在这个行业里,白皮书写得漂亮的太多了,真正能跨过Demo到规模化这道关口的,才是值得长期跟踪的项目。数据上链确权这件事,你们觉得是真需求还是伪命题?评论区聊聊。#OpenLedger