Market felt a little flat today. Not crashing, not running, just that in-between mood where you keep refreshing and nothing really moves. So I ended up doing what I probably shouldn't do when I'm bored — I started digging into things I'd been putting off.
I'd been loosely following OpenLedger and $OPEN for a while. Not seriously. It kept showing up in the tokenized data conversation and I kept skimming past it thinking, okay, another project promising contributors a cut of their data value. I've seen that pitch before. We all have.
But something shifted when I stopped reading the pitch and started looking at what the model actually does structurally.
Here's where I got stuck. Most of the conversation around tokenized data participation treats it like a fairness upgrade. You, the contributor, finally get paid instead of the platform. That's the emotional frame. And it's not wrong exactly, but I think it quietly buries the more interesting economic thing happening.
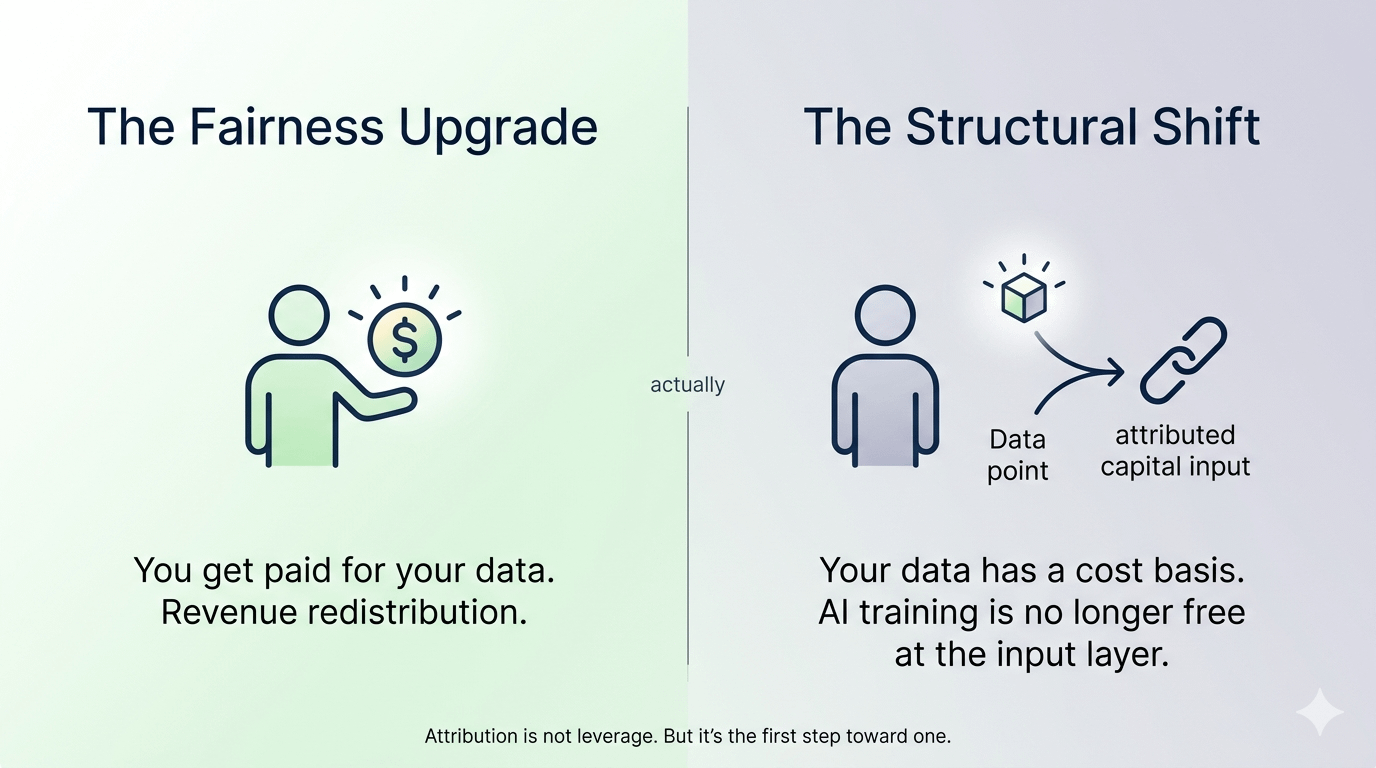
When contribution becomes traceable and attributed on-chain, you're not just getting a slice of revenue. You're creating a new asset class. Your data history becomes something closer to a productive input with a ledger — not just a product that got extracted once and sold. The distinction matters more than it sounds at first.
I thought the value capture story was mainly about redistribution. But actually it's about what happens when data stops being a consumed resource and starts behaving more like contributed capital. That's a different set of economic implications entirely.
If that holds, then the interesting question isn't whether contributors earn more — it's whether attribution at scale changes how AI development gets funded. Right now, model training is essentially free at the input layer. Data contributors don't set prices, don't negotiate terms, don't retain upside. OpenLedger's architecture, if the attribution layer actually functions downstream and not just at the submission interface, would start to introduce something like a cost structure into that input layer. Which is uncomfortable for a lot of parties who benefit from it staying free.
That's the part that made me pause. Not the token. The structural pressure it puts on an assumption that's been invisible because it was never challenged.
But here's the part that bothers me. Attribution is not the same as leverage. Knowing your contribution is logged is a long distance from having meaningful economic power over how it's used. The mechanism that connects those two things — traceability to actual pricing power — isn't obviously in place yet. And I kept circling back to this: most contributors will never verify whether their attribution persists through downstream licensing. The system can prove it. That doesn't mean it routinely shows you that it has.
I'm not fully convinced this holds under pressure at scale. When millions of data points are attributed and the market for them starts to form, who actually negotiates? Who aggregates enough to have standing? Individual contributors with small data footprints might find themselves technically attributed but economically marginal — which isn't so different from where they started.
And there's a governance layer here I haven't resolved. If $OPEN becomes the mechanism through which contribution value is priced and distributed, then token concentration becomes a quiet override on the fairness premise. I don't know enough yet about how that's structured. That part I'm still sitting with.
What I keep coming back to is the economic framing shift itself. Whether or not OpenLedger executes it cleanly, the idea that data input into AI systems should carry attributed capital-like properties is probably a real evolution in how this industry gets priced eventually. The project might get it half right, or wrong entirely, and the idea still matters.
Anyway. Charts still look sideways. I'll probably just watch how this plays out.
@OpenLedger #OpenLedger