Gândire onestă... când Steve Jobs a anunțat iPhone-ul în 2007, mulți oameni au întrebat "cine are nevoie de asta, Nokia funcționează bine." Această întrebare nu a fost greșită. A durat doar câțiva ani să înțelegem răspunsul. Văzând OpenLedger pentru prima dată mi-a adus în minte aceeași întrebare, iar de data aceasta am refuzat deliberat să răspund repede.🤔
Așadar, hai să mă gândesc la asta cum trebuie.
Problema la care OpenLedger răspunde este reală și asta contează. În acest moment... pipeline-urile de antrenament AI consumă volume enorme de date, dar aproape nimeni nu vorbește despre unde provine efectiv acea dată. Cine a contribuit, cum a fost verificată și dacă contributorul a primit ceva în schimb sunt întrebări care rămân în mare parte fără răspuns.... Acea tăcere nu este accidentală. Este o lacună structurală de care sistemele centralizate beneficiază păstrând tăcerea. OpenLedger se poziționează direct în interiorul acelei lacune, ceea ce este fie curajos, fie ambițios, în funcție de cum vezi lucrurile.
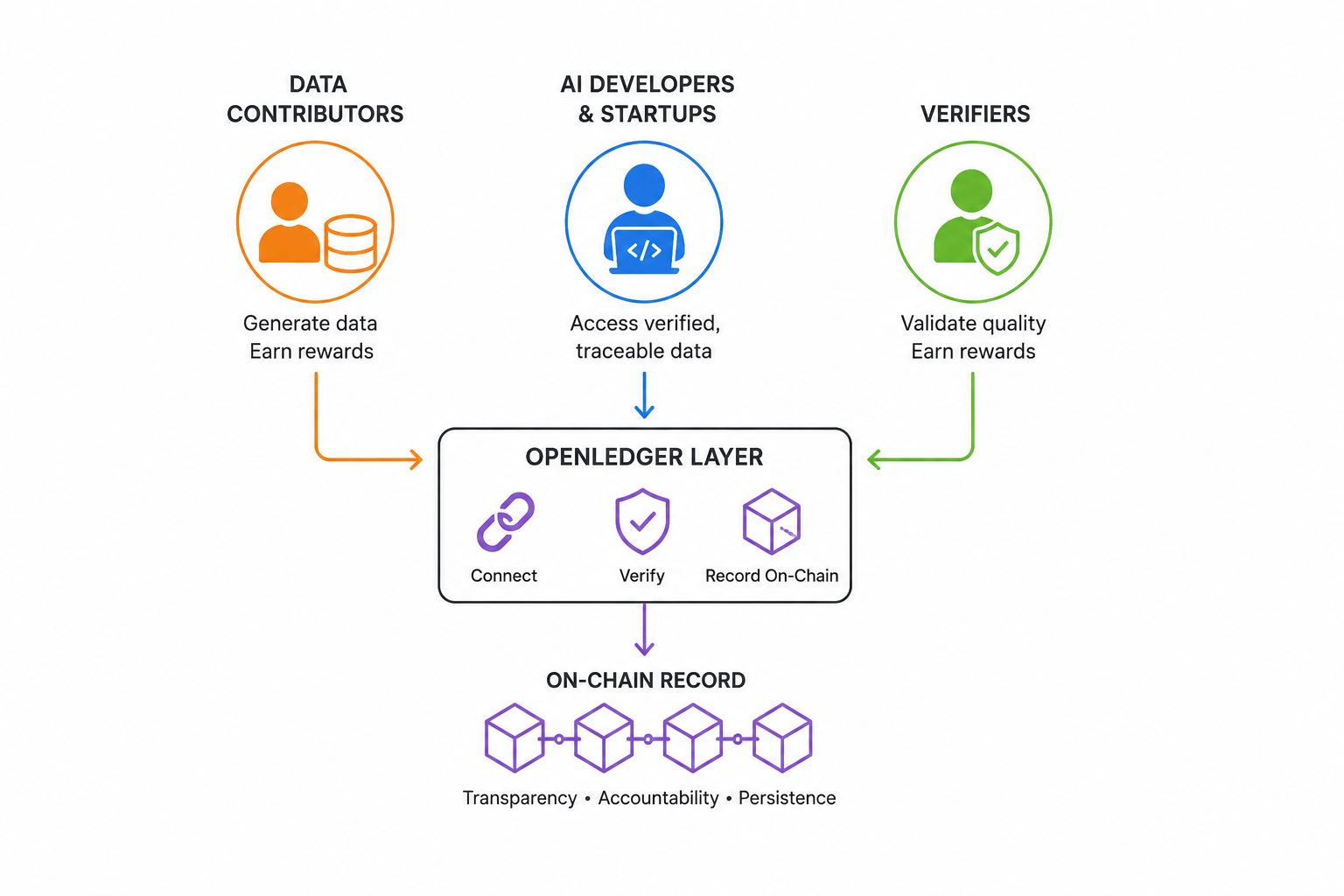
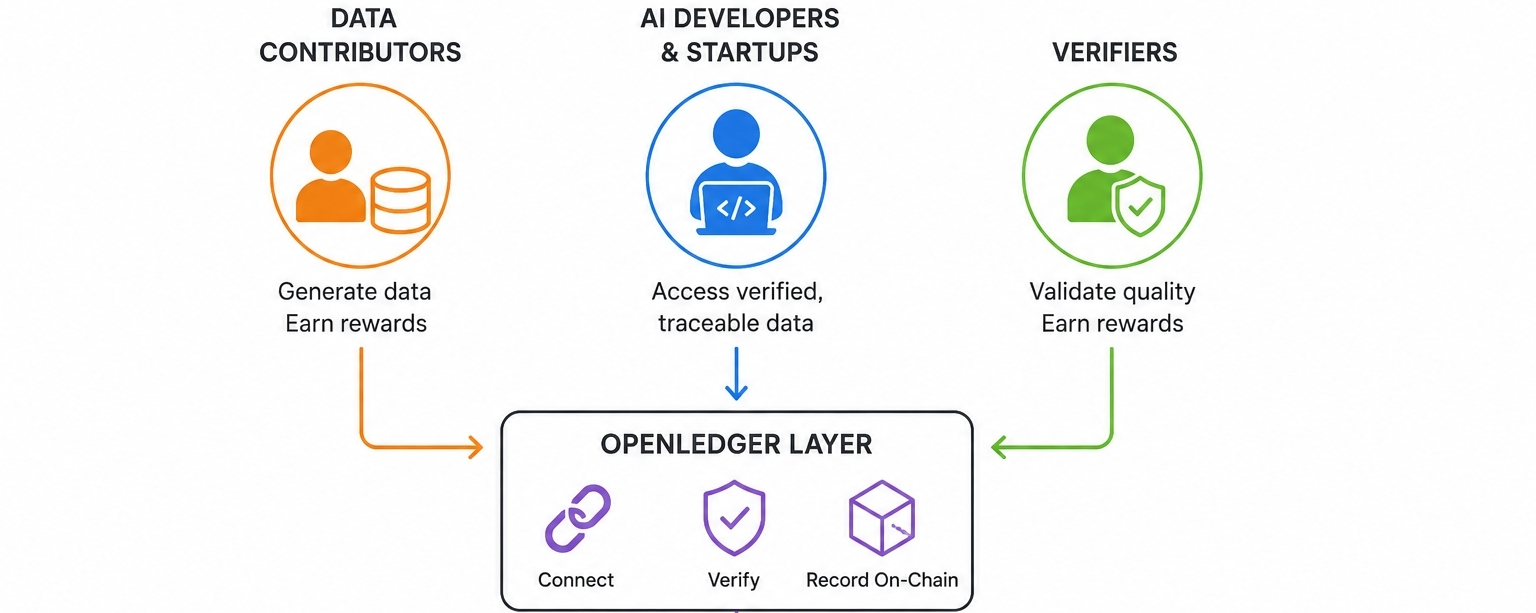
Iată ce găsesc cu adevărat interesant în legătură cu arhitectura. OpenLedger nu încearcă doar să construiască o piață. Încercă să conecteze trei grupuri distincte care în prezent nu au o infrastructură comună: dezvoltatori care au nevoie de date curate și verificabile, contribuitori care produc aceste date fără compensație și verificatori care pot valida calitatea. Elementul de înregistrare pe blockchain este ceea ce face ca acest lucru să fie diferit de un schimb standard de date. Înregistrarea pe blockchain nu înseamnă doar transparență. Înseamnă responsabilitate care persistă. Aceasta este o distincție semnificativă.
Acum partea onestă.
Pentru dezvoltatorii de AI și startup-uri, propunerea de valoare este cea mai clară. Accesarea datelor verificate și trasabile fără a depinde de un singur furnizor centralizat este ceva ce multe echipe își doresc cu adevărat. Întrebarea este dacă ecosistemul OpenLedger ajunge la dimensiunea în care acest lucru devine practic.
Pentru contributorii de date zilnice, teoria este convingătoare, iar realitatea este mai dificilă. Ideea că cineva care generează date utile ar trebui să primească o parte din valoarea acestora este filozofic sănătoasă. Dar adopția printre utilizatorii non-crypto necesită reducerea fricțiunii pe care majoritatea protocoalelor de infrastructură încă o întâmpină.😤
Pentru $OPEN ca o considerație de investiție, teza valorii token-ului depinde de faptul că acest strat este folosit efectiv la un volum semnificativ. Aceasta nu este o critică; este doar secvența onestă a modului în care token-urile de infrastructură își derivă valoarea.
Și scepticismul pe care nu-l pot ignora: straturile de infrastructură care promit descentralizare au apărut în mai multe cicluri crypto. Multe au avut whitepaper-uri solide și probleme reale de rezolvat. Adoptarea a rămas slabă deoarece alinierea stimulentelor s-a rupt undeva între teorie și practică. OpenLedger va face față aceleași probe. Întrebarea guvernării rămâne, de asemenea, nerezolvată în mintea mea. Descentralizat în arhitectură nu înseamnă automat descentralizat în practică, iar cine controlează efectiv deciziile la nivel de protocol în timp merită urmărit.
Revenind la referința lui Steve Jobs pentru că își merită locul aici. Problema iPhone-ului era reală înainte ca soluția să existe. Oamenii pur și simplu nu puteau vedea toată forma problemei încă. Problema provenienței datelor în antrenarea AI-ului este reală astăzi, vizibilă astăzi și în creștere. Fie că OpenLedger devine soluția sau pur și simplu o încercare timpurie care informează ceva mai bun mai târziu, nu pot spune cu certitudine. Dar pot spune că problema pe care o abordează nu va dispărea. Aceasta, cel puțin, îmi menține atenția asupra $OPEN.
Notă: NFA ~ DYOR...