I keep coming back to OpenLedger, and honestly, that surprises me.
A few months ago, I placed it in the same category as many AI-blockchain projects: interesting narrative, ambitious promises, but difficult to separate from the noise. Then I started paying closer attention to what has actually been happening behind the scenes. The more I looked, the more I noticed something different. Not necessarily a guaranteed success story, but a project quietly assembling pieces that seem connected to a larger vision.
A recent conversation reminded me of this.
Earlier this year, a friend of mine built a small online design community. Nothing huge, just a group of creators sharing templates and artwork. One day he discovered some of his designs had appeared inside AI-generated outputs that looked suspiciously familiar. He could not prove where the data came from. He could not track usage. He definitely could not collect compensation.
That experience stuck with me because it highlights one of the biggest unresolved problems in artificial intelligence today: attribution.
Who owns the data?
Who contributed value?
Who gets paid when that data helps train a model?
This is exactly where OpenLedger appears to be focusing its attention.
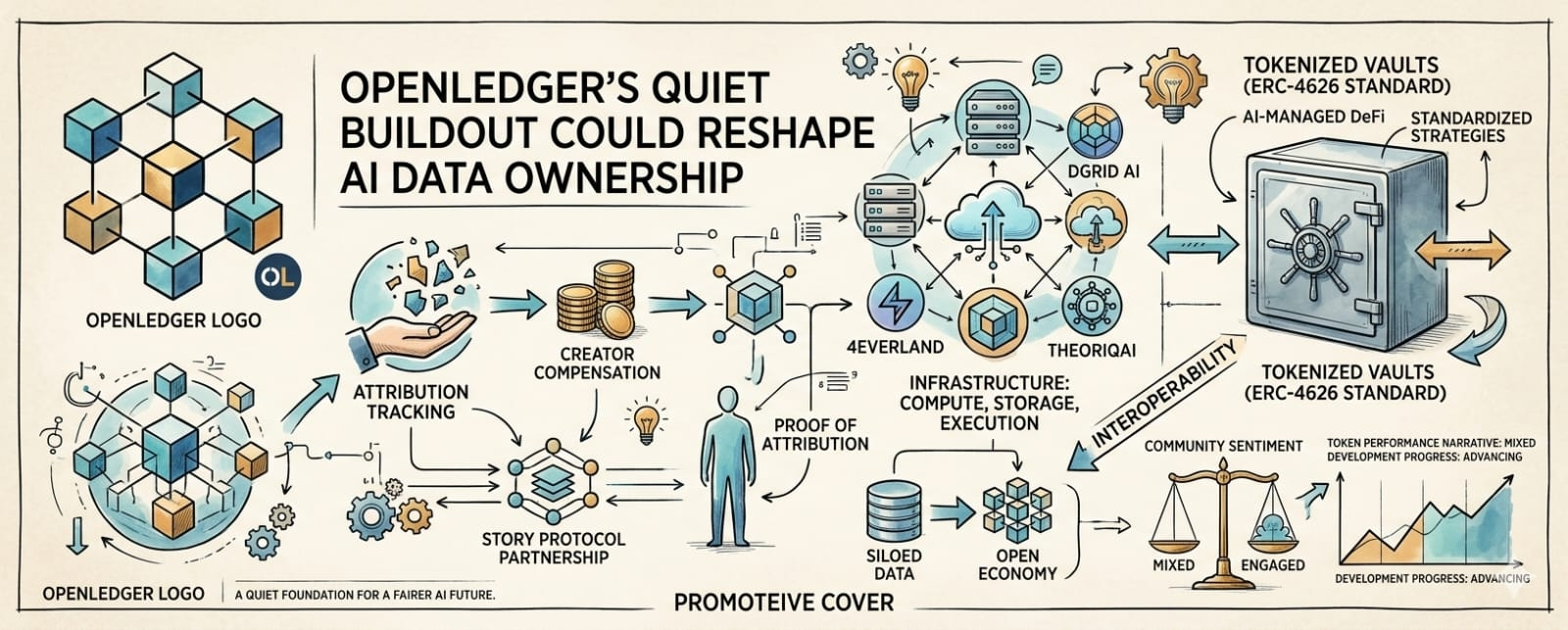
The development that caught my eye was the partnership with Story Protocol announced in late January. The goal is straightforward in theory but difficult in practice: create a rights-cleared framework for AI training data. Instead of treating training data as an invisible resource, the system aims to track intellectual property usage and create mechanisms that could reward creators whose work contributes to model development.
The timing feels important.
Regulators around the world are paying increasing attention to AI training practices. Questions about copyright, ownership, and licensing are becoming impossible for the industry to ignore. OpenLedger seems to be positioning itself as infrastructure for a future where data provenance matters.
Whether it works at scale remains an open question.
Tracking attribution across massive datasets is not simple. However, solving difficult problems is often where real opportunities emerge. If AI eventually moves toward transparent data sourcing, projects working on attribution today may find themselves in a much stronger position tomorrow.
What makes this more interesting is that OpenLedger is not limiting itself to data rights.
In March, the project adopted the ERC-4626 standard, which focuses on tokenized vaults. On the surface, this sounds technical. Underneath, it represents a push toward standardized AI-managed DeFi strategies.
I think of it like replacing dozens of isolated spreadsheets with a common operating system.
Instead of every application creating its own yield framework from scratch, ERC-4626 allows different systems to interact using a shared standard. OpenLedger appears to be exploring how AI can manage vault strategies while maintaining interoperability across platforms.
That does not guarantee superior returns.
In fact, I remain skeptical whenever anyone suggests AI can automatically outperform markets. Financial markets are competitive by nature. Yet standardization itself has value. Sometimes the infrastructure matters more than the immediate outcome.
Another aspect worth watching is the infrastructure stack being assembled.
Back in January, OpenLedger partnered with 4EVERLAND to strengthen cloud-related capabilities. Around the same period, collaboration with DGrid AI focused on decentralized computing resources. Then came the TheoriqAI partnership, which explored AI agents capable of performing DeFi-related tasks.
Viewed individually, these announcements might seem ordinary.
Viewed together, a pattern starts to emerge.
Storage.
Compute.
Execution.
Agent functionality.
Data attribution.
These are not isolated components. They resemble pieces of a broader architecture designed to support AI-powered applications operating in decentralized environments.
Whenever I evaluate early-stage ecosystems, I try to ask a simple question: are they building products, or are they building foundations?
Foundations usually take longer to gain recognition because they are less visible. Users notice applications. Developers notice infrastructure.
OpenLedger increasingly feels like a project focused on infrastructure.
That distinction matters.
The market often rewards narratives first and utility later. But long-term value tends to come from systems that other builders can use.
Community sentiment remains mixed, which is understandable.
There has been discussion around community-driven buyback proposals aimed at improving token stability. To me, that suggests the project has experienced its share of market pressure. Price performance and development progress do not always move together. In crypto, they frequently travel in opposite directions for extended periods.
That is why I try not to evaluate projects exclusively through price charts.
Speaking of charts, here is the framework I use when thinking about OpenLedger right now:
Data Attribution Progress: Improving
Infrastructure Partnerships: Expanding
AI Integration Strategy: Advancing
Standardization Efforts: Strengthening
Market Adoption: Still Uncertain
Token Performance Narrative: Mixed
The largest opportunity may be the enormous market of siloed data that OpenLedger frequently references.
Data has become one of the most valuable resources in the digital economy, yet much of it remains disconnected, inaccessible, or uncompensated. If the concept of Proof of Attribution functions effectively, it could introduce entirely new economic models for AI development.
That is the big if.
Corporations accustomed to free data access may resist systems that require ongoing royalty payments. Adoption challenges should not be underestimated. Good technology alone does not guarantee behavioral change.
Still, I find the direction compelling.
Most AI discussions focus on bigger models, faster inference, or more powerful agents. OpenLedger is asking a different question: how do we fairly distribute value to the people and data sources that make AI possible?
That question may end up being more important than many investors currently realize.
For now, I am keeping it on my watchlist.
Not because of hype.
Not because of price action.
Because the project appears to be addressing a structural problem that the AI industry will eventually have to confront. The partnerships, vault integrations, infrastructure collaborations, and attribution efforts suggest a team building toward a long-term objective.
Whether that objective translates into widespread adoption remains uncertain.
But the foundation being assembled today looks far more substantial than it did just a few months ago.

#SolsticeInstitutionsCryptoInfra #SuiMainnetResumes #CustodiaBankFedAppealExtension #AxeComputeAethirDeal