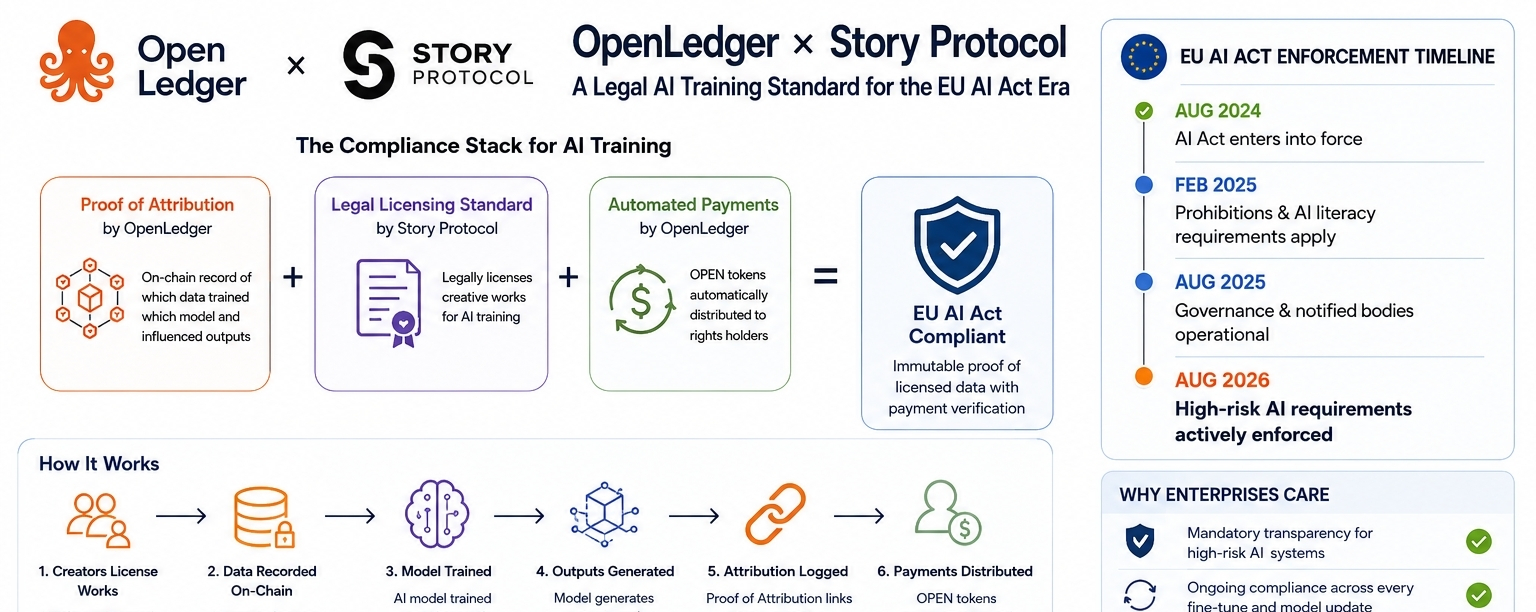
I was reading about the EU AI Act enforcement timeline when i found a partnership that made the regulatory angle click differently
I had been tracking the EU AI Act compliance requirements loosely for a few months mostly as background context, not as something directly relevant to what i was looking at on openledger. then i came across the Story Protocol partnership announcement and sat down to actually map out what the two things mean together. the connection i hadn't made before was how specific the regulatory tailwind is — and how directly openledger's existing architecture answers the compliance question that enterprises and AI developers are about to face whether they want to or not.
the thing that made me go back and read more carefully was a single detail in the partnership framing. Story Protocol created a standard for legally licensing creative works for AI training with automated payments to rights holders. openledger's Proof of Attribution records which data trained which model and distributes OPEN tokens automatically to contributors when their data is used. those two things together legal licensing standard plus on-chain attribution record plus automatic payment l form a compliance stack that i hadn't seen assembled anywhere else. i spent time mapping out what that actually means for an enterprise or AI developer trying to demonstrate regulatory compliance. [PE]
the setup is this. the EU AI Act and emerging regulatory frameworks in multiple jurisdictions are moving toward requiring AI developers to demonstrate data provenance — where training data came from, whether it was licensed with consent, and how it influenced model outputs. the current industry answer to that question is largely a combination of internal documentation, terms of service agreements, and voluntary disclosure. none of that is cryptographically verifiable. none of it is immutable. openledger's PoA mechanism is. every dataset used in training is recorded on-chain with a cryptographic link to the model it trained and the outputs it influenced. the Story Protocol partnership adds the legal licensing layer on top of that on-chain record meaning the compliance answer isn't just "we have documentation," it's "here is an immutable on-chain record of licensed data with automated payment proof."
what this means for enterprise adoption specifically
what makes this structurally significant is the timing. the EU AI Act's compliance requirements for high-risk AI systems are moving into active enforcement. enterprises building AI systems that touch hiring, credit, healthcare, or legal decisions are facing mandatory transparency requirements that their current infrastructure cannot satisfy. a centralized database of training data records can be edited. an internal policy document can be revised. an on-chain PoA record with Story Protocol licensing cannot be altered retroactively — and that distinction is exactly what regulatory compliance requires.
the part that surprised me was how the investor composition connects to this. HashKey Capital one of openledger's backers is a Hong Kong-based institutional fund with deep ties to regulated financial markets in Asia. their portfolio focuses specifically on infrastructure that can operate in compliance-heavy environments. they don't typically back narrative plays. the fact that HashKey is in the cap table, combined with a Story Protocol partnership that directly addresses the EU AI Act compliance problem, suggests the enterprise regulatory market was part of the thesis from early in the protocol's development not something added later as a pivot.
why the automation layer is the part regulators actually care about
what i kept thinking about while going through this is that regulatory compliance in AI has a second problem beyond provenance it's ongoing. a company that demonstrates clean data provenance at model launch still needs to demonstrate it for every fine-tuning cycle, every model update, every new dataset added. manual compliance documentation at that frequency is operationally unsustainable for most organizations. openledger's attribution engine update from January 2026 specifically addressed this ensuring data-output links remain intact even as models are updated and fine-tuned. that's not a feature for researchers. that's a feature for legal and compliance teams.
what i'm not fully clear on yet is the enterprise sales motion. the technical compliance stack is real — PoA plus Story Protocol licensing plus attribution engine continuity across model updates is a genuinely strong answer to the regulatory question. but enterprise adoption requires more than a strong technical answer. it requires procurement processes, SLA guarantees, dedicated support infrastructure, and enterprise-grade documentation that i haven't seen published yet. i went looking for case studies or named enterprise pilots and couldn't find them. that gap between technical readiness and enterprise sales readiness is what i'm watching. [PE]
what i'm watching: whether named enterprise pilot announcements come through HashKey's institutional network before the September 2026 token unlock, whether Story Protocol's legal licensing standard gets referenced in any EU AI Act compliance guidance from regulators, and whether the attribution engine audit trail gets packaged into a compliance product with enterprise documentation.
still trying to find evidence that the enterprise sales infrastructure exists at the same level as the technical compliance stack the regulatory tailwind is real, the architecture answers the question, but named customers would change this from a thesis to a proven market 🤔
