M-am uitat la OpenLedger mai mult timp decât mă așteptam, iar partea ciudată este că proiectul în sine a încetat să fie cea mai interesantă chestiune pe la jumătatea cercetării. Povestea mai mare continua să-mi capteze atenția în altă parte. Fiecare document, fiecare diagramă de arhitectură, fiecare explicație a Proof of Attribution părea să orbiteze aceeași realitate inconfortabilă: AI-ul modern depinde de o cantitate enormă de contribuții umane, totuși aproape niciunul dintre sistemele din jurul său nu este proiectat să-și amintească de unde a venit acea contribuție. Vorbim neîncetat despre modele, inferență, GPU-uri, legi de scalare și agenți din ce în ce mai puternici. Mult mai puțină atenție se acordă originilor economice ale inteligenței în sine. Asta pare a fi un punct orb. Unul în creștere.
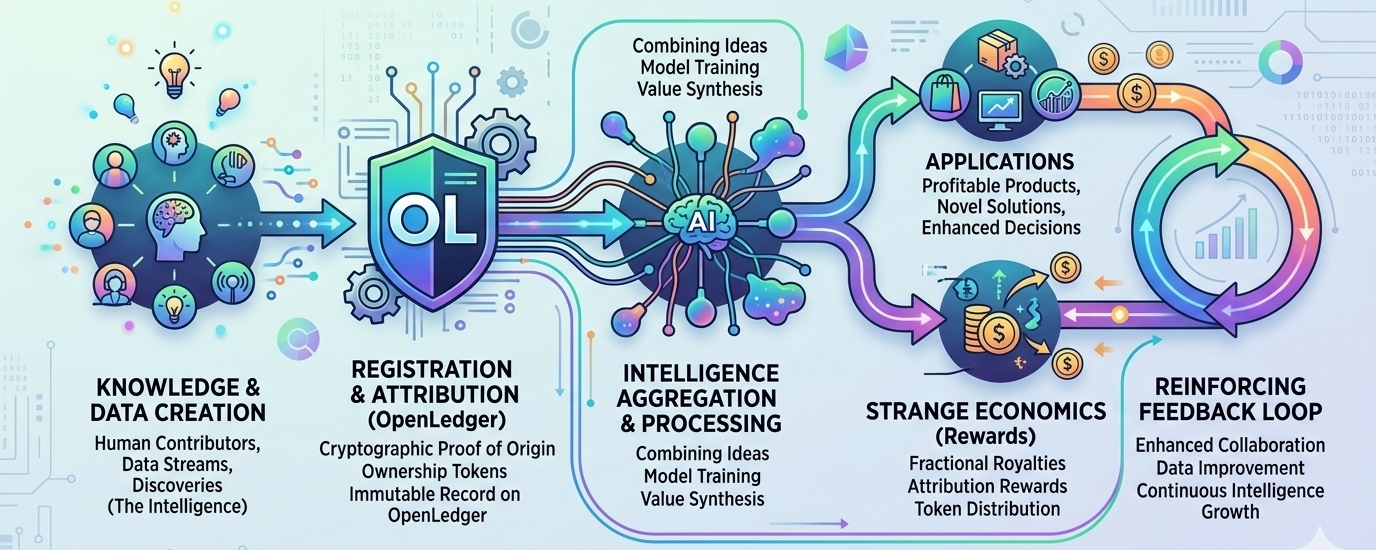
OpenLedger încearcă să construiască infrastructură în jurul acestei probleme. Proiectul se descrie ca o blockchain axată pe AI, unde seturile de date, modelele și agenții pot fi urmărite, atribuite și monetizate printr-un cadru on-chain construit special pentru fluxurile de lucru AI. În loc să trateze datele ca un input de consumabil care dispare în pipeline-urile de antrenare, OpenLedger încearcă să creeze înregistrări permanente care arată cum contribuțiile influențează comportamentul și output-urile modelului. Mecanismul din spatele acestui lucru se numește Dovada Atribuirii, care își propune să lege criptografic contribuțiile de date de rezultatele modelului și să recompenseze participanții conform impactului lor. Pe hârtie, sună aproape evident. Dacă datele creează valoare, contribuabilii ar trebui să primească o parte din acea valoare. Simplitatea ideii este probabil motivul pentru care continuă să rămână în mintea mea.
Apoi încep complicațiile.
Cu cât citesc mai mult, cu atât îmi dau seama că OpenLedger nu face cu adevărat o argumenție tehnologică, ci mai degrabă una economică. Propune că datele ar trebui să se comporte ca un capital productiv, nu ca o resursă care este absorbită și uitată. Sistemul lor Datanet funcționează ca o rețea de seturi de date specializate unde contribuabilii oferă informații specifice domeniului care pot fi utilizate ulterior pentru antrenarea și desfășurarea AI. Aceste seturi de date rămân atribuibile, versiuni și conectate la contribuabili printr-un sistem de înregistrare transparent. Citind documentația, m-am tot gândit cât de diferit este acest lucru față de economia AI actuală, unde informația este adesea agregată la o scară masivă, iar contribuția individuală devine aproape imposibil de identificat ulterior.
Ce mă lovește este că OpenLedger pare să parieze pe un viitor în care AI devine mai specializată, nu doar mai mare. Proiectul subliniază în mod repetat modele specifice domeniului antrenate pe seturi de date concentrate, în loc să se bazeze complet pe sisteme gigantice de uz general. Poate că au dreptate. Obsesiile actuale cu modele tot mai mari se simt uneori ciudat de detașate de modul în care operează efectiv afacerile. Cele mai multe industrii nu au nevoie de o mașină capabilă să discute filozofie, să scrie poezii și să genereze scenarii de film. Au nevoie de sisteme care înțeleg cererile de asigurare, rapoartele de radiologie, procesele de fabricație, documentele legale sau prognoza agricolă cu o precizie extremă. Viitorul ar putea conține mii de modele specializate care fac muncă utilă în tăcere în loc de un număr mic de modele masive care încearcă să facă totul.
Această posibilitate schimbă valoarea datelor. Dintr-o dată, activele rare nu mai sunt informațiile în general. Există deja prea multe informații. Activele rare devin informațiile de încredere. Informațiile verificate. Informațiile bogate în context. Datele conectate la expertiză. Datanets de la OpenLedger par concepute în jurul acestei presupuneri. Contribuabilii trimit seturi de date text, imagine sau audio în depozite structurate unde sistemele de validare încearcă să evalueze calitatea și relevanța înainte ca informația să devină parte a ecosistemului. Întregul cadru depinde de ideea că datele utile merită recunoaștere economică.
Totuși, am tot dat peste aceeași întrebare în timp ce citeam despre mecanismele de atribuție. Poate influența dintr-un rețea neuronală să fie măsurată cu suficientă acuratețe pentru ca aceste sisteme de recompensă să funcționeze corect?
Aici devine mai greu să-mi reprim scepticismul.
Modelele de învățare automată nu sunt sisteme contabile. Sunt sisteme statistice. Influența se răspândește pe straturi, greutăți, embeddings, procese de recuperare și interacțiuni care sunt adesea greu de interpretat chiar și pentru cercetătorii care le construiesc. OpenLedger recunoaște această provocare propunând multiple metode de atribuție, inclusiv aproximări ale funcției de influență și sisteme de atribuție la nivel de token în funcție de arhitectura modelului. Ambiția tehnică este impresionantă. Dacă aceste metode rămân fiabile la scară este mult mai greu de evaluat.
Poate că atribuirea perfectă este imposibilă.
Poate că acesta este reperul greșit.
Întrebarea mai realistă este dacă atribuirea imperfectă este totuși dramatic mai bună decât absența aproape totală a atribuării care există astăzi.
Suspectez că aceasta ar putea fi adevărata argumentație ascunsă sub limbajul de marketing.
O altă parte a arhitecturii care mi-a atras atenția implică sistemele de Generare Augmentată prin Recuperare. OpenLedger propune un cadru în care informațiile recuperate pot rămâne legate de sursa lor originală în timpul inferenței. Dacă un model generează un output folosind informații dintr-un set de date specific, evenimentul de recuperare poate fi înregistrat și contribuabilii recompensați corespunzător. Comparativ cu unele dintre ideile mai abstracte care circulă în jurul AI și crypto, aceasta a părut surprinzător de concretă. Cele mai multe implementări practice AI de astăzi se concentrează pe recuperare, managementul cunoștințelor, căutarea în întreprinderi și sistemele informaționale, mai degrabă decât scenariile de science-fiction despre superinteligența autonomă. OpenLedger pare conștient de această realitate.
Desigur, nimic din toate acestea nu garantează adoptarea.
Proiectele de infrastructură sună adesea convingător cu mult înainte de a deveni utile.
Industria AI se mișcă brutal de repede. Organizațiile mari au avantaje enorme în resursele de calcul, talentul ingineresc, canalele de distribuție și capital. Sistemele deschise trebuie să concureze împotriva companiilor capabile să cheltuie miliarde de dolari anual pe cercetare și infrastructură. Această provocare ar putea suprasolicita chiar și cele mai puternice idei. Există, de asemenea, riscul familiar ca stimulentele crypto să devină mai atractive decât utilizarea efectivă a produsului, creând ecosisteme în care speculația crește mai repede decât utilitatea.
Am observat urme ale acelei tensiuni în timp ce citeam discuțiile din comunitate. Unii contribuabili par cu adevărat interesați de proprietatea și atribuirea datelor. Alții par concentrați în principal pe performanța token-ului, listările pe schimburi și narațiunile de pe piață. Această diviziune există în aproape fiecare proiect crypto, în cele din urmă. Partea dificilă este determinarea care parte devine dominantă în timp.
Până când am terminat de citit documentul alb și documentația de atribuție, am rămas cu mai puțină certitudine decât aveam la început. Ciudat, acest lucru a făcut proiectul mai interesant, nu mai puțin. OpenLedger se simte ca o încercare de a rezolva o problemă care există cu adevărat, chiar dacă soluția rămâne neterminată. Economia AI depinde din ce în ce mai mult de contribuțiile unor rețele enorme de oameni, a căror participare devine invizibilă odată ce începe antrenarea. Datele intră în mașină. Valoarea apare mai târziu. Legătura dintre aceste două momente dispare adesea.
OpenLedger susține esențial că legătura ar trebui să rămână vizibilă pentru totdeauna.
Dacă acea viziune va avea succes, este imposibil de știut acum. Provocările tehnice sunt substanțiale. Provocările de coordonare ar putea fi chiar mai mari. Totuși, întrebarea de bază pare greu de ignorat: pe măsură ce inteligența artificială devine mai importantă din punct de vedere economic, cum decidăm cine a contribuit la inteligența sa în primul rând?
Industria nu pare să aibă încă un răspuns convingător.
OpenLedger, în ciuda tuturor incertitudinilor sale, încearcă măcar să pună întrebarea înainte ca restul pieței să fie forțat să o facă.
