I sat at my desk near midnight with laptop and a cup of tea. I was reading OpenLedger’s attribution paper because I keep seeing the same question. Can this model stay accurate outside the paper?
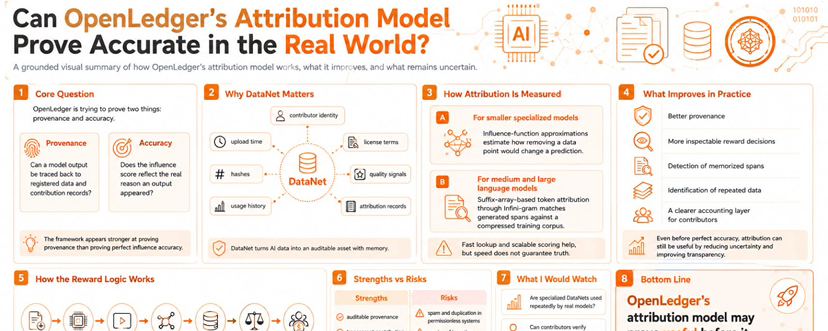
I think OpenLedger is trying to prove two things at once. The first is provenance. That means a model output should be traceable back to registered data and contribution records. The second is accuracy. That means the influence score assigned to a dataset should reflect the real reason an output appeared. The whitepaper feels stronger on the first claim. A public trail can show how rewards were calculated. It cannot automatically prove that the calculation captured true influence.
What I find useful is the DataNet idea. A DataNet is an on-chain dataset container that gives data a clearer record of origin and use. It can show who contributed the data. It can show when it was uploaded. It can also carry license terms, hashes, quality signals, usage history, and attribution records. That gives me a cleaner way to think about AI data as an asset with memory. If a domain dataset has provenance from the start then a model trained on it has a better chance of being audited later. I see progress because the system is building the accounting layer needed before fair rewards can be judged.
The hard part is measurement. For small specialized models OpenLedger leans on influence-function approximations. These estimate how removing a data point would affect a prediction. For medium and large language models it shifts toward suffix-array-based token attribution through Infini-gram. That method matches generated spans against a compressed training corpus. I like this split because it avoids pretending that one method fits every model size. The paper also gives concrete lookup latencies and describes faster influence scoring than older exact methods in one benchmark. Still speed is not truth. A system can be fast and transparent while still being imperfect when data is messy, duplicated, low quality, or influential without matching exact tokens.
My central view is that OpenLedger’s attribution model can become useful in the real world before it becomes perfectly accurate. I would not expect attribution to read a model’s mind. I would expect it to reduce uncertainty, expose provenance, catch memorized spans, identify repeated data, and make reward decisions easier to inspect than a black-box pipeline. If it can do that consistently then it already changes the business logic around data contribution.
The market may misunderstand this point. I do not think the strongest case for OpenLedger is that every contributor receives a perfect payout for every inference. I think the stronger case is that the protocol creates a repeatable process. Data is registered. Models are trained with logged provenance. Influence is computed after inference. Rewards are then shared according to the recorded contribution weight. That gives builders, contributors, and governance a shared record to argue from. In messy markets a shared record can matter more than a vague promise of fairness.
The risk is execution. DataNets are permissionless. That helps growth but it can also attract spam, duplication, and gaming. The paper mentions curation, challenges, and validation. I think those layers will decide whether attribution stays credible. If low-quality data can gain visibility through staking or formatting then reward accuracy weakens. If ambiguous outputs depend more on broad patterns than exact spans then token matching may under-credit useful background data. If governance sets fee allocation poorly then the incentive loop can disappoint contributors.
For my practical lens I would watch adoption through usage instead of slogans. I would look for specialized DataNets that real models repeatedly use. I would look for attribution histories contributors can verify. I would also look for reward flows that survive dispute and evidence that quality scoring improves performance. In the short term the narrative is explainable AI with payouts. In the long term the bigger question is whether OpenLedger can make data markets more disciplined by turning influence into something measurable enough to price.
So can OpenLedger’s attribution model prove accurate in the real world? I would say it can prove useful first. Accuracy will have to be earned through repeated inference, audits, adversarial testing, and contributor behavior. My takeaway is simple. I would not treat Proof of Attribution as a finished truth machine. I would treat it as a serious attempt to make AI data provenance measurable, payable, and open to inspection. That narrower claim is the one I can take seriously.


