Market's been choppy lately. Not crash-level noise, just that low-grade restlessness where nothing really moves but everyone keeps refreshing. I had a tab open with $OPEN charts, mostly just habit, and ended up falling into a rabbit hole I wasn't expecting.
I started looking into how OpenLedger actually structures its reward system — not the pitch, the mechanics. And somewhere between reading the Proof of Attribution docs and watching the token sit roughly 88% below its September 2025 ATH of $1.82, something clicked that I can't quite shake.
Here's the thing most people seem to be missing: everyone frames $OPEN and OpenLedger as an AI transparency story. Verifiable data, traceable lineage, fair payouts. And sure, that's real. But the more interesting design question buried inside it is actually about when someone gets rewarded. Not how much — when.
Traditional AI economies pay contributors once, upfront, or not at all. You upload something, it gets scraped, that's the end of your economic relationship with it. What OpenLedger's Proof of Attribution is quietly proposing is a recurring royalty model — you earn every single time your data influences an inference, not just when you contributed it. The reward isn't tied to the act of giving. It's tied to the ongoing usefulness of what you gave.
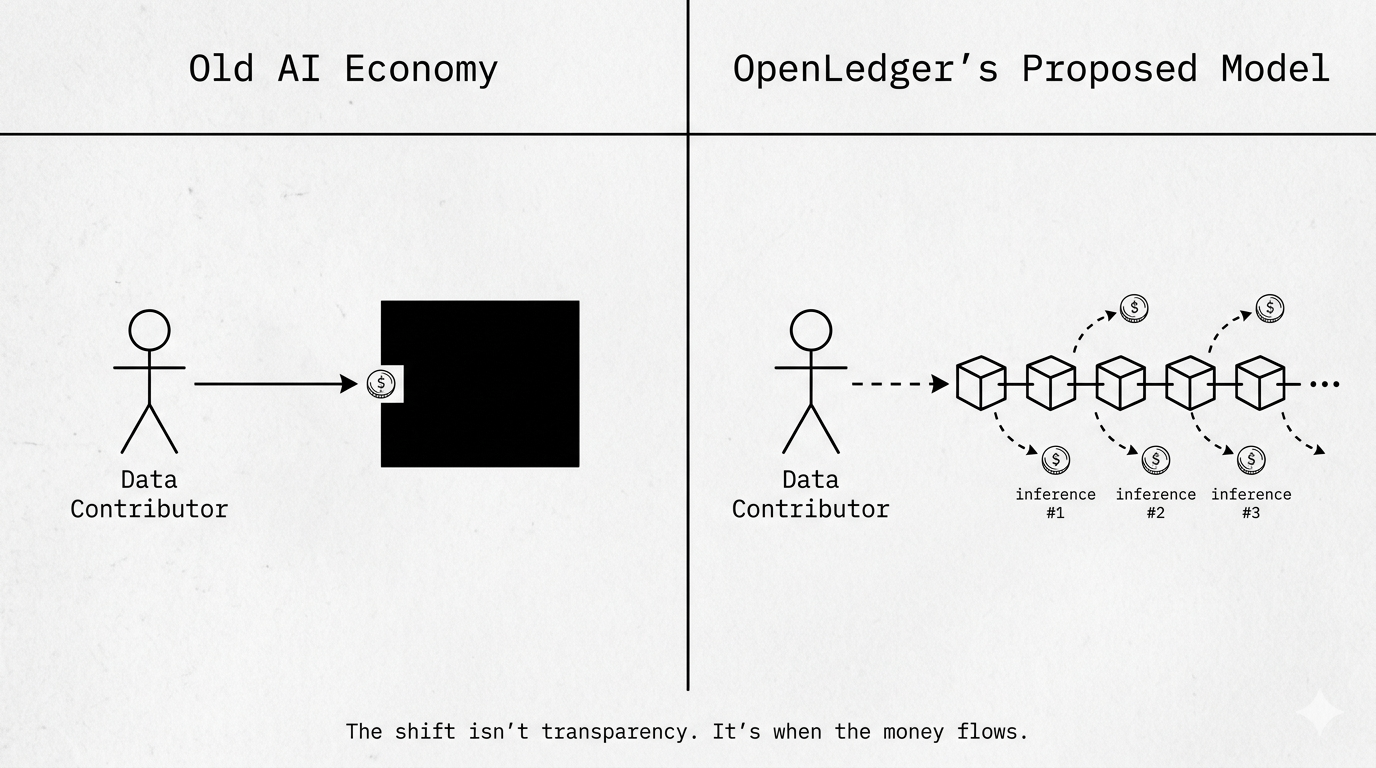
That's a completely different incentive shape. And if it actually works at scale, it changes who bothers contributing quality data in the first place. Right now, the people who produce high-signal niche datasets — domain experts, specialists, annotators with deep context — have basically zero reason to do it publicly. The economics don't work. OpenLedger is trying to flip that. If a medical researcher's annotated dataset keeps influencing outputs for three years, they keep earning for three years.
I thought that was mostly narrative at first. But then I read the PoA whitepaper more carefully. The attribution math — influence function approximations for smaller models, suffix-array token matching for LLMs — is genuinely trying to solve a hard problem. It's not just hand-waving about "contribution rewards." There's a real mechanism attempt.
But here's the part that bothers me…
The influence scores that determine how much a contributor earns aren't fully transparent on-chain. The provenance is recorded. The lineage is verifiable. But the weighting — the number that actually sets your payout — gets computed via approximation methods that the average contributor has no practical way to audit. So the incentive design is open in principle and partially opaque in practice. That tension is real and unresolved. It's the difference between "you will be rewarded fairly" and "you can verify you were rewarded fairly." Those aren't the same promise.
And the token unlock clock is ticking — team and investor vesting starts September 2026 after a 12-month cliff. That's not a red flag by itself, but it does mean the next few months of actual on-chain data are quietly significant. Does real contributor usage grow before that supply hits? Or does the reward flywheel need more runway than the unlock schedule allows?
I genuinely don't know. The design is interesting enough that I keep coming back to it. There's something here about what healthy incentive design looks like in a world where AI models become infrastructure — where the question of who keeps getting paid starts to matter as much as who got paid first.
Anyway. Charts still look rough. Team has until September to show traction before things get more complicated. I'll probably just watch.
@OpenLedger #OpenLedger