astăzi vreau să discut despre ceva cu adevărat tehnic pentru că cred că conversația la nivel de suprafață despre OpenLedger ratează provocarea reală de inginerie. toată lumea vorbește despre agenți și proprietatea datelor și atribuire. corect. dar sub toate acestea există două probleme de infrastructură care trebuie rezolvate corect sau nimic din lucrurile interesante nu funcționează la scară.
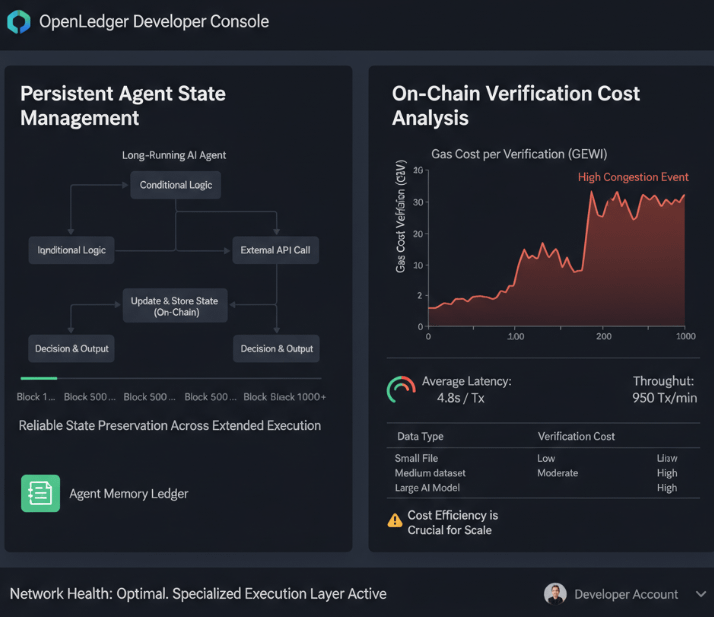
prima este gestionarea stării pentru agenții care funcționează pe termen lung.
chain-urile de scop general au fost concepute în jurul tranzacțiilor discrete. ceva se întâmplă, este înregistrat, s-a terminat. modelul mental este o intrare în registru. curat, limitat, final. dar un agent AI care face ceva cu adevărat util nu funcționează în acest fel. un agent de trading care monitorizează condițiile de piață pe parcursul mai multor sesiuni, un agent de cercetare care extrage și procesează date timp de ore, un agent de coordonare care gestionează dependențele între alți agenți, acestea nu sunt tranzacții discrete. sunt procese continue cu un stat care evoluează continuu și trebuie păstrat fiabil în timp fără ca rețeaua să piardă urma a ceea ce se întâmplă.
nicio lanț de uz general nu a fost construit având acest caz de utilizare în vedere. Ethereum nu a fost. majoritatea L2-urilor nu au fost. ele gestionează starea într-un bloc, într-o tranzacție, într-un apel de contract. dar starea persistentă a agenților pe perioade lungi de timp, cu ramificare condițională și dependențe de date externe este o problemă complet diferită. arhitectura OpenLedger este proiectată în jurul acestui aspect specific, motiv pentru care deciziile legate de mediul de execuție contează mult mai mult decât își dau seama oamenii atunci când se uită doar la prețul token-ului.

cea de-a doua problemă este costul real al verificării datelor on-chain și nimeni nu o include în prezentarea de marketing pentru că cifrele nu sunt tocmai frumoase.
fiecare bucată de date care este atribuită, verificată și înregistrată on-chain costă ceva. gaz, latență, capacitate de procesare. și când construiești o rețea unde contribuția de date este activitatea economică principală, aceste costuri nu sunt cazuri marginale. ele sunt evenimentul principal. dacă verificarea este scumpă, contribuabilii mici sunt excluși. dacă este lent, fluxurile de lucru ale agenților care depind de date verificate proaspete se distrug. dacă capacitatea de procesare este limitată, rețeaua se congestionează exact când adopția crește, care este cel mai prost moment pentru o creștere a tarifelor.
motivul pentru care aceste două probleme sunt conectate este că gestionarea stării și costul verificării se află ambele la același strat. mediul de execuție. dacă obții acel strat corect, ambele probleme devin gestionabile. dacă îl obții greșit, ajungi cu o rețea care funcționează frumos într-o demonstrație controlată și începe să piardă valoare în momentul în care utilizarea reală pune presiune pe ea.
ceea ce îmi dă încredere în abordarea OpenLedger este că acestea nu sunt probleme în care au dat peste ele. deciziile arhitecturale care se iau în jurul execuției specializate, mai degrabă decât desfășurării generale pe lanț, sugerează că echipa a identificat aceste puncte de presiune devreme și a construit în jurul lor, în loc să spere că nu vor conta. aceasta este, de obicei, diferența dintre infrastructura care rezistă și infrastructura care își cere scuze.
modelul economic încetează să piardă bani doar când stratul tehnic de dedesubt este sincer cu privire la costurile sale. OpenLedger este sincer în acest sens într-un mod în care majoritatea proiectelor din acest spațiu nu sunt.