Cea mai simplă greșeală pe care o poți face când evaluezi OpenLedger este să presupui că este un proiect AI.
Obiectivul mai greu și mai util este să o tratăm ca pe un experiment de coordonare economică.
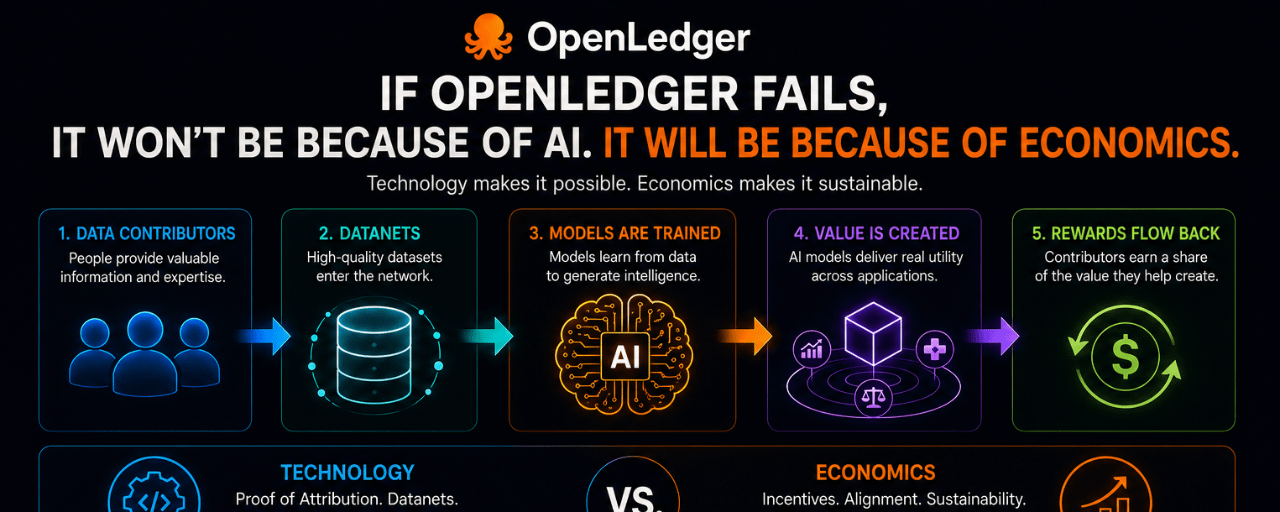
Majoritatea oamenilor se concentrează pe tehnologie mai întâi. Dovada Atribuirii. Datanets. ModelFactory. OpenLoRA. Stiva de infrastructură este importantă, dar tehnologia este rar motivul pentru care piețele adoptă un sistem la scară largă.
Piețele adoptă sisteme când stimulentele continuă să funcționeze după ce entuziasmul dispare.
Aceasta este adevărata provocare pe care OpenLedger încearcă să o rezolve.
Promisiunea de bază a protocolului este simplă. Contributorii de date oferă informații. Modelele sunt antrenate folosind acele informații. Când acele modele generează valoare, contributorii primesc o parte din activitatea economică prin atribuire.
Tehnologia determină dacă acel proces este posibil.
Economia determină dacă supraviețuiește.
Această distincție contează pentru că AI are deja acces la cantități enorme de date. Internetul nu suferă de o lipsă de informații. Ceea ce îi lipsește este un mecanism sustenabil care să mențină contributorii de calitate implicați pe perioade lungi de timp.
O mulțime de discuții despre AI presupun că oamenii vor contribui cu date dacă există recompense.
Istoria sugerează ceva mai complicat.
Sistemele de stimulente tind să funcționeze extrem de bine la început. Apoi, participanții învață cum sunt calculate recompensele. În cele din urmă, comportamentul începe să se optimizeze pentru recompensă în sine, mai degrabă decât pentru rezultatul pe care recompensa a fost concepută să-l încurajeze.
DeFi a experimentat asta prin mining de lichiditate.
GameFi a experimentat asta prin play-to-earn.
Rețelele sociale au experimentat asta prin algoritmi de angajament.
OpenLedger se confruntă cu o versiune a aceleași provocări.
Întrebarea nu este dacă contributorii pot fi recompensați.
Întrebarea este dacă contributorii continuă să ofere date valoroase în loc să ofere doar mai multe date.
Astea sunt rezultate foarte diferite.
De aceea cred că cea mai importantă parte a OpenLedger nu este Proof of Attribution în sine.
Este dacă atribuția devine în cele din urmă un filtru de calitate.
Dacă sistemul poate identifica constant care contribuții îmbunătățesc cu adevărat performanța modelului, protocolul creează un ciclu de feedback în care calitatea atrage capital și capitalul atrage mai multă calitate.
Dacă nu poate, atribuția riscă să devină un sistem contabil sofisticat care măsoară activitatea mai degrabă decât valoarea.
Și acea diferență determină aproape totul.
Pentru că OpenLedger încearcă în cele din urmă să stabilească o piață în care cunoștințele se comportă ca un capital productiv.
Nu sunt mulțumită.
Nu atenție.
Nu speculație.
Capital.
Un set de date medical, un set de date financiare, un set de date legale—acestea nu sunt valoroase pentru că există. Ele sunt valoroase pentru că îmbunătățesc rezultatele. Întreaga model economic depinde de măsurarea acelei îmbunătățiri suficient de precis încât participanții să aibă încredere în rezultat.
Aceasta este o problemă mult mai dificilă decât construirea unei alte aplicații AI.
De aceea proiectul este interesant.
Majoritatea infrastructurii AI se concentrează pe a face inteligența mai ieftină.
OpenLedger se concentrează pe a face contribuțiile măsurabile.
Acestea sună similar la suprafață.
Ele rezolvă probleme complet diferite.
Viitorul OpenLedger probabil nu va fi decis de cine construiește cel mai bun model.
Va fi decis de faptul că rețeaua poate convinge participanții că crearea de valoare este măsurată suficient de corect pentru ca ei să continue să contribuie după ce stimulentele inițiale dispar.
Dacă asta funcționează, OpenLedger creează o nouă piață în jurul datelor.
Dacă nu reușește, devine un alt exemplu despre cât de dificil este să aliniem stimulentele în jurul muncii digitale.
Și, sincer, acea întrebare economică este mai interesantă decât întrebarea despre AI.