

Nu mai privi OpenLedger ca pe un singur lucru! Asta a fost, sincer, greșeala pe care am tot făcut-o la început.
Încercam să-l înțeleg ca pe un singur produs. Ca, ok, e asta un lanț AI? E o platformă de date? E un marketplace de modele? E un sistem de recompense? E un alt proiect crypto AI cu un nume fain în jurul proprietății?
Dar cu cât mă uitam mai mult la asta, cu atât mai mult cadrul începea să pară prea mic.
OpenLedger are mai mult sens când încetezi să încerci să-l pui într-o singură cutie.
Nu e doar despre date.
Nu e doar despre modele.
Și odată ce acel ciclu se fixează, totul începe să se simtă diferit.
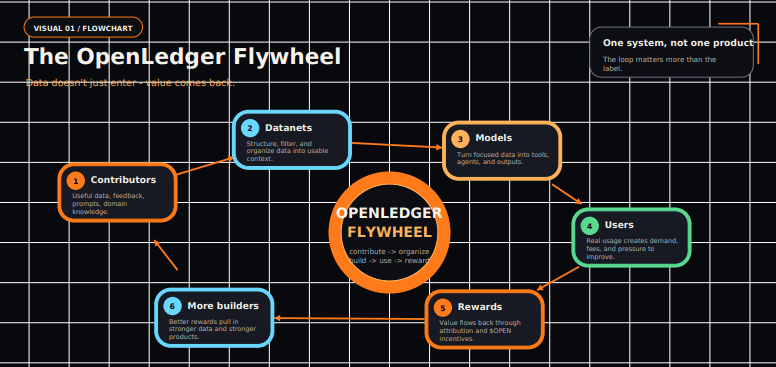
Roata OpenLedger este de fapt destul de simplă în teorie.
Oamenii contribuie cu date.
Acelea date sunt organizate prin Datanets.
Modelele folosesc acele date.
Valoarea se întoarce.
Și dacă acel ciclu continuă să se miște, OpenLedger încetează să mai arate ca un proiect normal și începe să arate ca un ecosistem care se poate hrăni singur.
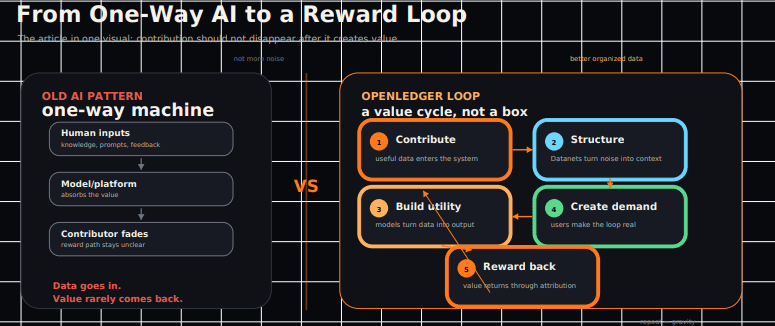
Aici devine interesant. Pentru că majoritatea sistemelor AI de astăzi se simt unidirecționale. Datele intră, dar nimic nu revine cu adevărat. Oamenii creează conținut, împărtășesc cunoștințe, etichetează lucruri, scriu prompturi, oferă feedback, construiesc comunități, antrenează comportamente indirect și apoi, cumva, totul dispare într-o cutie neagră.
Modelul devine mai inteligent. Platforma devine mai bogată. Contributorii devin invizibili. Asta a fost modelul normal.
OpenLedger încearcă să contesteze acel model.
Nu prin a spune „AI este rău” sau „modelele nu ar trebui să existe.”
Nah, asta nu e ideea.
Ideea este mai simplă.
Cineva adaugă date utile. Poate că este cunoștințe de domeniu. Poate că este informații de nișă. Poate că este feedback structurat. Poate că este un set de date specializat pe care un model general nu l-ar înțelege niciodată corect pe cont propriu.
Acea dată singură nu este suficientă totuși.
Datele brute sunt dezordonate.
Încărcările aleatorii nu devin magic valoroase doar pentru că există pe blockchain. Aici intră în scenă Datanets.
Pentru mine, Datanets sunt partea care face ca OpenLedger să pară mai organizat decât o idee de bază „încarcă date și câștigă.”
Pentru că dacă toată lumea aruncă informații aleatorii într-un singur butoi uriaș, nu obții inteligență.
Obții zgomot.
Și AI are deja destul zgomot.
Datanets creează structură în jurul contribuției. Ele fac datele mai concentrate. Mai utile. Mai conectate la un scop specific.
Asta contează pentru că AI specializat nu va fi construit din scraping aleatoriu pentru totdeauna.
La un moment dat, modelele au nevoie de intrări mai curate.
Mai mult context. Date mai relevante....
Date care înțeleg cu adevărat o arie profund în loc să pretindă că înțeleg totul în mod egal.
De aceea cred că roata OpenLedger nu începe cu „mai multe date.”
Totul începe cu date mai bine organizate.
Există o mare diferență. Mai multe date pot face un sistem mai greu. Date mai bune pot să-l facă mai ascuțit.
Odată ce datele sunt organizate, următoarea etapă sunt modelele.
Aici începe roata să se învârtească de la contribuție la utilitate.
Pentru că datele devin valoroase doar când se poate construi ceva util din ele.
Un set de date care stă pe loc este doar potențial.
Un model folosind acel set de date îl transformă în ieșire. Acum contribuția devine parte din ceva cu care oamenii pot interacționa de fapt. aici este unde stratul modelului OpenLedger devine important.
Constructorii pot lua date concentrate și crea modele în jurul lor.
Aceste modele pot servi utilizatorilor.
Ei pot răspunde mai bine.
Ele pot opera în piețe specifice. Ele pot susține agenți. Dar nu explică întotdeauna de unde vine cererea. Pentru că recompensele fără cerere sunt doar emisii.
Asta nu e o roată.
Asta e o scurgere.
Pentru ca OpenLedger să funcționeze pe termen lung, modelele au nevoie de utilizare reală.
Oamenii trebuie să folosească ceea ce se construiește.
Constructorii au nevoie de un motiv să creeze.
Utilizatorii au nevoie de un motiv să se întoarcă.
Ecosistemul are nevoie de cerere care să nu fie bazată doar pe farming sau speculații.
Asta e partea pe care o urmăresc.
Pentru că dacă utilizatorii au cu adevărat nevoie de aceste modele, atunci recompensele devin mai semnificative.
Utilizarea generează taxe.
contribuie → organizează → construiește → folosește → recompensează → repetă.
Simplu, dar puternic dacă chiar funcționează.
Partea recompenselor este importantă pentru că schimbă logica emoțională a participării la AI.
Acum, majoritatea oamenilor contribuie la sistemele AI fără să se gândească la asta.
Fiecare postare, comentariu, set de date, corectare, prompt, evaluare, explicație și insight de nișă pot ajuta la conturarea unui fel de inteligență undeva.
Dar sistemul de recompense este stricat.
Majoritatea contributorilor primesc atenție cel mult.
Uneori nimic.
De obicei nimic.
OpenLedger încearcă să creeze un sistem unde contribuția poate fi urmărită și recompensată în loc să fie înghițită.
Asta pare mic până te gândești cât de mare ar putea deveni AI.
Dacă AI devine parte din muncă, creativitate, afaceri, cercetare, automatizare și finanțe, atunci întrebarea devine evidentă:
Cine primește bani când inteligența creează valoare?
Sau și oamenii ale căror date, feedback și cunoștințe au ajutat să facă sistemul util?
Asta e întrebarea mai profundă din OpenLedger.
Și, sincer, asta e motivul pentru care nu-l văd doar ca pe un alt coin AI.
Tokenul este doar o piesă.
Ceea ce contează mai mult este ciclul valorii.
Dacă $OPEN este folosit în acel ciclu pentru recompense, taxe, stimulente și guvernare, atunci devine legat de activitatea ecosistemului.
Dar din nou, asta contează doar dacă ciclul are cu adevărat activitate reală.
Sistemul trebuie să dovedească că datele utile atrag constructori, constructorii creează modele utile, utilizatorii creează cerere și recompensele atrag contribuții și mai bune.
Asta e toată treaba.
Dacă o parte se strică, roata se încetinește. Se simte ca o infrastructură care încă trebuie să-și dovedească utilitatea. Dar asta nu o face mai puțin interesantă.
De fapt, majoritatea infrastructurii se simte plictisitoare sau incompletă înainte ca oamenii să înțeleagă de ce contează.
Internetul a avut protocoale înainte de aplicații.
DeFi a avut căi înainte ca lichiditatea reală să vină.
L2-urile au trebuit să construiască straturi de decontare și execuție înainte ca utilizatorii să le pese de designul lanțului.
Acum AI ar putea avea nevoie de căi de atribuire și proprietate înainte ca oamenii să realizeze cât de stricat este fluxul actual de valoare.
Asta e unde OpenLedger ar putea să se potrivească. Nu ca modelul strălucitor despre care toată lumea vorbește. Nu ca aplicația zgomotoasă de care toată lumea postează capturi de ecran.
Asta este stratul economic al AI.
Părerea mea personală este asta:
Dacă OpenLedger are succes, nu va fi pentru că oamenii au început să iubească cuvântul „Datanets.”
Nu va fi pentru că fiecare trader înțelege atribuirea peste noapte.
Nu va fi nici măcar pentru că AI este o narațiune fierbinte.
Se va întâmpla pentru că ciclul începe să funcționeze.
Contributorii văd valoare. Constructorii văd date utile. Modelele se îmbunătățesc.
Utilizatorii creează cerere. Recompensele se întorc. Mai mulți oameni se alătură.
Ciclul se repetă.
Asta e momentul în care OpenLedger devine mai mult decât un proiect.
Asta e momentul în care devine un sistem viu.
Și asta e partea pe care cred că piața ar putea să o subestimeze în continuare.
Utilizatorii creează cerere.
Recompensele aduc valoarea înapoi.
Asta e toată roata.
Și dacă continuă să se învârtă,$OPEN începe să arate mai puțin ca o tranzacție narativă și mai mult ca stratul de coordonare din spatele unei economii AI noi.
@OpenLedger #OpenLedger $OPEN
