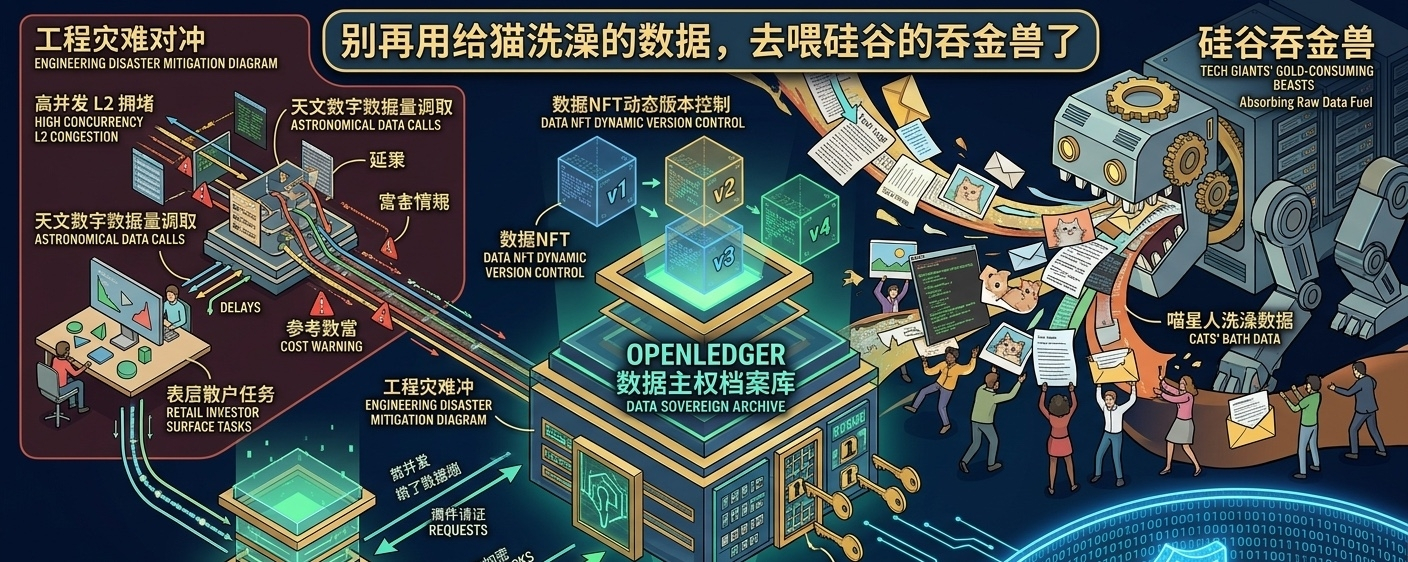
盯着屏幕上那些密密麻麻的链上数据,我常有一种幻觉。现在的去中心化AI赛道,像极了当年一窝蜂搞分布式算力的土路子。大家天天喊着买显卡、租算力,以为把几万张淘汰的显卡连在一起就能造出下一个ChatGPT。然而现实很骨感,算力只是雇佣兵,真正卡住脖子的是干净、垂直且有版权的底层数据。说白了,没有好草,再壮的牛也挤不出好奶。
最近翻完 @OpenLedger 的白皮书,抛开那些被各路KOL嚼烂的Datanet数据网或者Proof of Attribution归因证明,我倒是注意到一个没人细聊,但极具工程美感和底层创新的东西:**数据NFT的动态版本控制与非对称加密交叉验证**。
简单来说,这就好比你把手里的行业机密或者独家代码打包,以往卖给大模型公司就是一锤子买卖,对方转头把你拉黑,你连版权毛都捞不到。而在OpenLedger的架构里,数据被封装成了可以动态升级、且带有加密锁的资产。算法模型想调用它,得在链上通过一连串的数学自证明,确定你这盘“菜”确实适合它的“胃口”,完成一次调用,就通过 $OPEN 进行一次实时结算。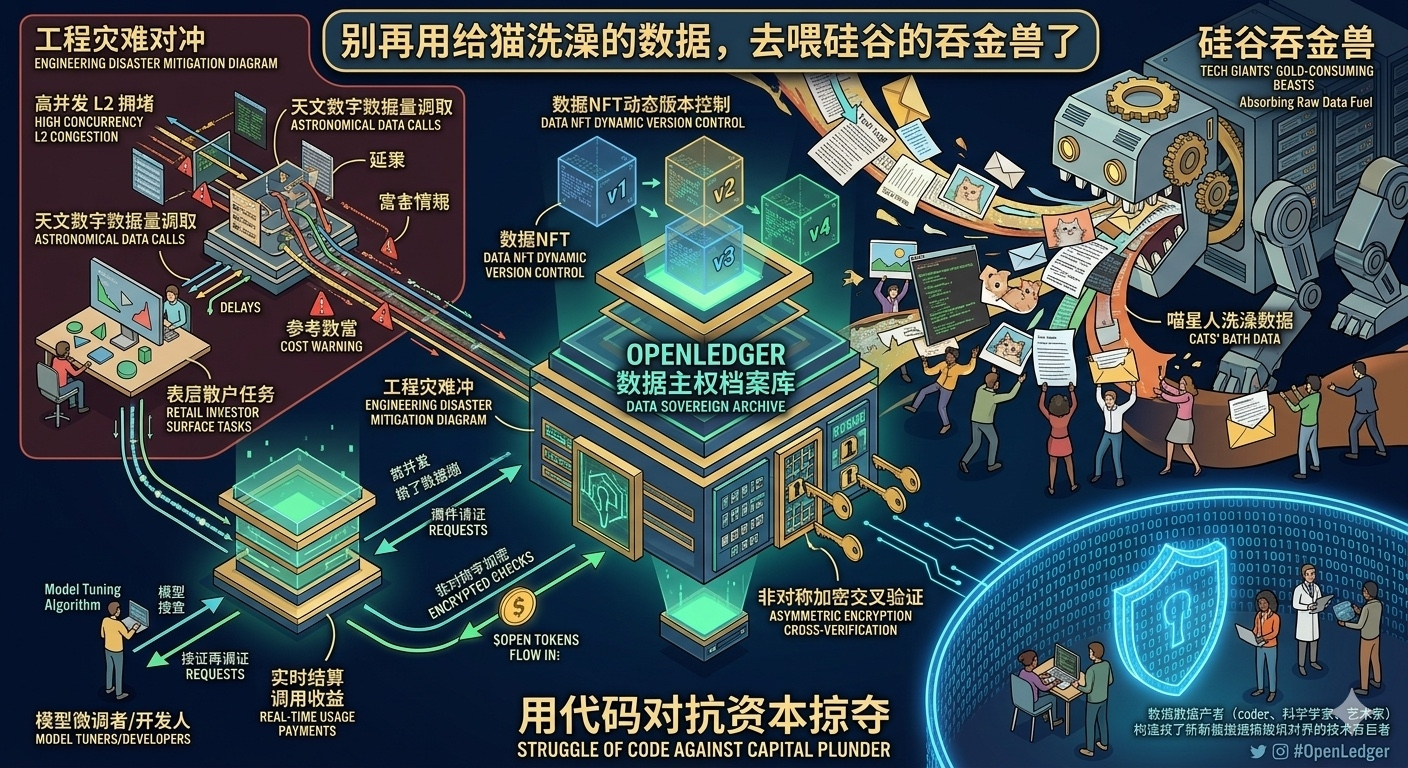
很多所谓的去中心化AI项目,说白了就是给中心化的API套了个区块链的壳子,属于标准的PPT项目。OpenLedger好歹是在解构AI生命周期的链上利益分配。底层逻辑听起来很性感,数据提供者、模型微调者、验证节点各司其职,谁贡献谁拿钱。
这个宏大的数据确权和实时分发,目前来看更像是一个处于理想状态的理想国。我们在工程上管这叫高并发灾难。AI模型每一次微调或者推理,需要吞噬的数据量是天文数字。如果每一次数据的调取、确权、归因和利益结算都要在链上过一遍,哪怕用上了再牛的二层网络,那高昂的微调成本和延迟也会把开发者逼疯。数据NFT的模板目前看来也略显单一,很多复杂的、非结构化的医疗或者金融敏感数据,想真正无缝塞进这个格式里,兼容性依然有一大段路要走。普通散户现在进去,大概率也就是做做表层任务,离真正去部署一个能跑通闭环的微调模型还隔着十万八千里。
不过,它至少撕开了一条口子,那就是把数据的主权从硅谷那几家科技巨头的垄断里抢回来。
我们这代人在互联网上裸奔了太久。你在社交媒体上发的每一句牢骚,在论坛里写的每一段技术分析,转头就被科技巨头的爬虫吞进肚子里,变成它们几千亿参数大模型的养料,最后它们再把包装好的AI服务高价卖回给你。这本身就是一种荒诞的数字剥削。
#OpenLedger 做的尝试,其本质不是简单的去中心化倒买倒卖,而是在数字世界里建立一套新的生产关系。哪怕现在的步伐看起来有些笨拙,工程落地的阵痛也远未结束,但这种在链上给数据打上不可磨灭的数字烙印、试图用代码对抗资本掠夺的尝试,依然是这个充满泡沫的行业里少数值得凝视的方向。技术从来不完美,但比起躺在巨头的温床里被动地当肥料,我更愿意看到这种带着理想主义刺角的底层探索,在混乱的链上秩序中野蛮生长。