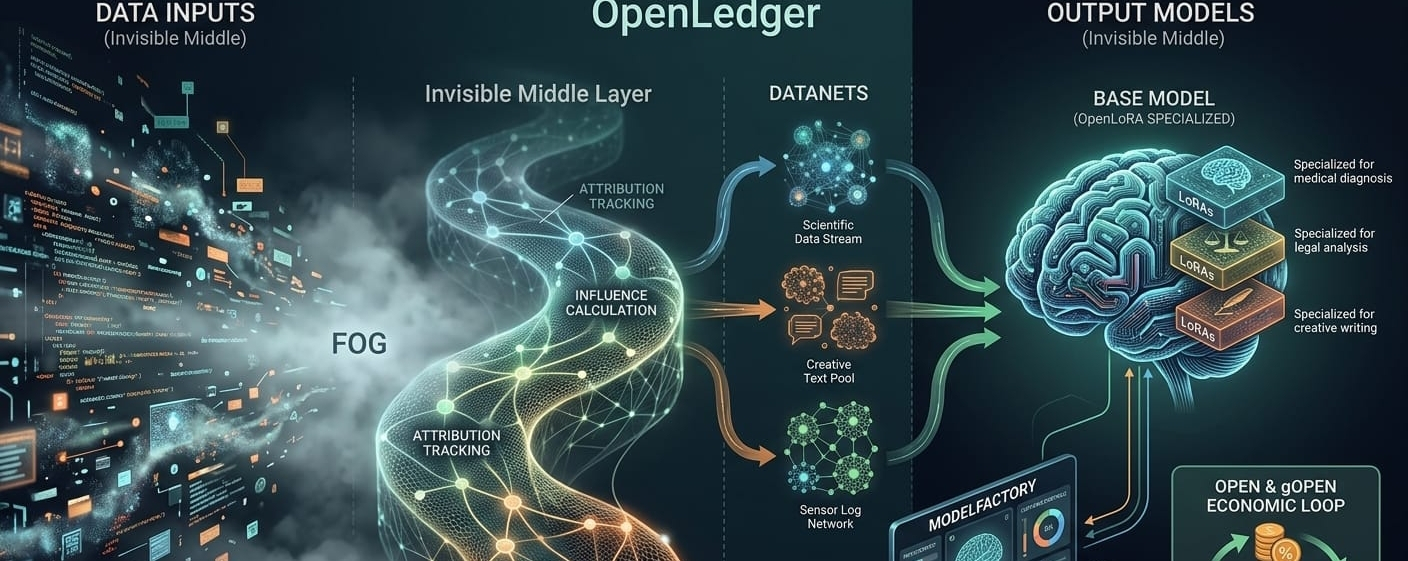
There’s a strange gap in modern AI that most people casually step over without noticing.
We obsess over inputs (data), and we obsess over outputs (model performance, benchmarks, demos, agent behavior). But the middle layer—the part where data becomes intelligence, where contribution turns into capability—that part is basically treated like fog.
It just… happens.
OpenLedger is interesting because it goes straight into that fog and starts asking uncomfortable questions. Not about whether AI works, but about what gets erased when it works.
And that’s a very different starting point.
Attribution in AI has always been a kind of polite fiction. We say models are “trained on data,” but we don’t really track how specific pieces of data shape specific behaviors. We don’t because it’s hard, and also because the system wasn’t designed for it. Once data enters training, it disappears into parameter space. No labels. No receipts. No ownership trail.
Just weights.
Clean, but also a bit suspicious if you think about it long enough.
OpenLedger tries to reintroduce structure into that disappearance process. Not by stopping it—but by layering a tracking system on top of it. That’s the essence of Proof of Attribution.
The idea is deceptively simple: if a model produces an output, you should be able to estimate what contributed to it. Not perfectly. Not deterministically. But meaningfully enough to assign influence.
This is where most people underestimate the difficulty. Because influence in neural networks isn’t additive. It’s entangled. A single output is the result of millions of micro-adjustments across datasets, parameters, and training dynamics. You’re not tracing a path—you’re reconstructing a probability field after the fact.
Messy work. The kind you don’t fully solve, only approximate.
Still, approximation changes behavior.
That’s the part worth paying attention to.
Because once contributors believe their input can be traced—even loosely—they stop acting like they’re dumping data into a void. They start curating. Competing. Optimizing. Suddenly data contribution isn’t passive anymore. It becomes economic behavior.
And that shift is bigger than it looks.
Now layer in Datanets.
Instead of treating data as one giant undifferentiated pool, Datanets structure it into grouped, attributable streams. Think of it less like a dataset and more like a network of curated influence zones. Each zone feeds models differently. Each one can be tracked, weighted, rewarded.
If that sounds abstract, it kind of is. But the intuition is straightforward: not all data should be treated equally, and not all contributions should vanish into the same statistical blender.
Some of it matters more. Some of it shapes behavior disproportionately. The system just never had a clean way to admit that before.
Then there’s OpenLoRA, which grounds the whole thing in practicality.
Because attribution and coordination don’t matter if models are too rigid to adapt. OpenLoRA introduces lightweight adaptation layers so models can be specialized without full retraining. Instead of rebuilding everything, you modify behavior through modular updates.
Less “retrain the entire brain,” more “install a new cognitive reflex.”
That might sound like a small engineering detail, but it quietly changes distribution dynamics. Suddenly, model customization isn’t locked behind large institutions with massive compute budgets. It becomes accessible, incremental, and distributed.
Which feeds directly into ModelFactory.
This is where things shift from infrastructure to interface. ModelFactory is essentially the attempt to make model shaping usable without deep ML expertise. And honestly, this part matters more than most people admit.
Because systems don’t scale on architecture alone. They scale on usability.
If you’ve ever seen a powerful system that no one can actually operate without a specialist, you already know how this story goes. It dies quietly, or it becomes niche.
ModelFactory is trying to prevent that by making model adaptation feel less like engineering and more like configuration.
Then comes the economic layer—OPEN and gOPEN.
This is where the system stops being purely technical and starts behaving like an ecosystem with incentives baked in.
The idea is to connect usage, contribution, and model performance into a loop where value flows back to participants based on measurable influence. Data contributors, model builders, and infrastructure providers aren’t just “supplying inputs.” They’re participating in a system that tries (imperfectly, but intentionally) to track and reward their impact.
Now, here’s where I’ll be direct: incentive systems in AI are always messy. They attract gaming, noise, and strategic behavior very quickly. That’s not a flaw unique to OpenLedger—it’s just how reward systems behave once money enters them.
But ignoring incentives entirely is worse. Because then you end up with extraction without feedback.
And that’s basically where most of today’s AI ecosystem already sits.
So the real question isn’t whether attribution works perfectly. It won’t. It can’t.
The question is whether it works well enough to shift behavior.
That’s the threshold that matters.
Because once attribution is “good enough,” even if imperfect, it changes how people participate. It changes what gets submitted as data. It changes how datasets are curated. It changes how model improvements are valued internally.
Small shifts, but they compound.
And that compounding effect is where the flywheel emerges.
Better data → better models → more usage → stronger attribution signals → more rewards → higher quality data.
It’s not magic. It’s just feedback loops doing what feedback loops do when you finally wire incentives into them instead of bolting them on later.
Zoom out a bit and something else becomes obvious.
OpenLedger isn’t really about AI models at all. It’s about making the “invisible middle” visible enough to coordinate.
That middle layer—between raw data and intelligent output—has always been treated as a black box. Not because it needed to be, but because we didn’t have a reason strong enough to open it.
Now we do.
Because AI is no longer just generating answers. It’s shaping decisions, systems, workflows, even financial flows. And when outputs start having real-world consequences, “we don’t know exactly how that was formed” stops being acceptable.
So we start reaching for structure. Attribution. Coordination. Incentives.
Not because it’s elegant. But because it’s necessary.
And OpenLedger, whether it succeeds or not, is basically a bet that the next real breakthrough in AI won’t come from scaling models further.
It’ll come from finally understanding—and coordinating—the messy middle we’ve been ignoring all along.
