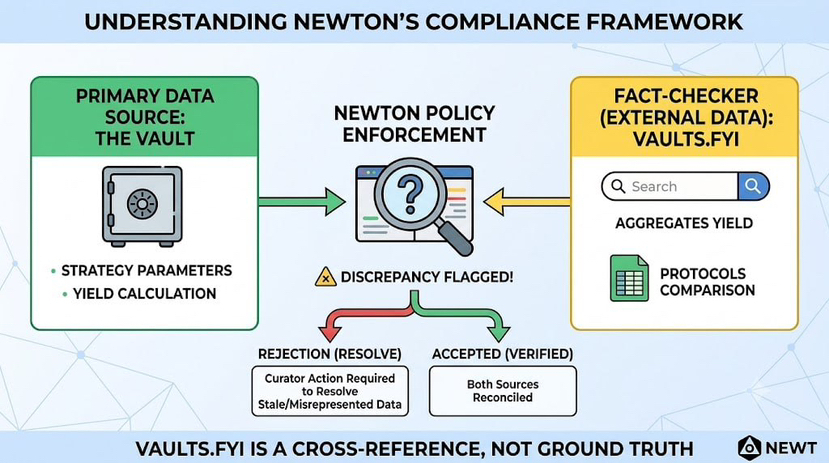
Newsrooms with a serious editorial process do not treat a single fact-checking pass as proof a story is correct. A fact-checker's job is to catch claims that do not reconcile with the underlying evidence, flagging discrepancies for a reporter to resolve before publication. The fact-checker rarely generates the original claim. They test it against something else. Newton's use of Vaults.fyi inside its compliance domain works the same way, and understanding that framing matters for anyone assuming yield data flowing through a Newton policy is simply accepted at face value.
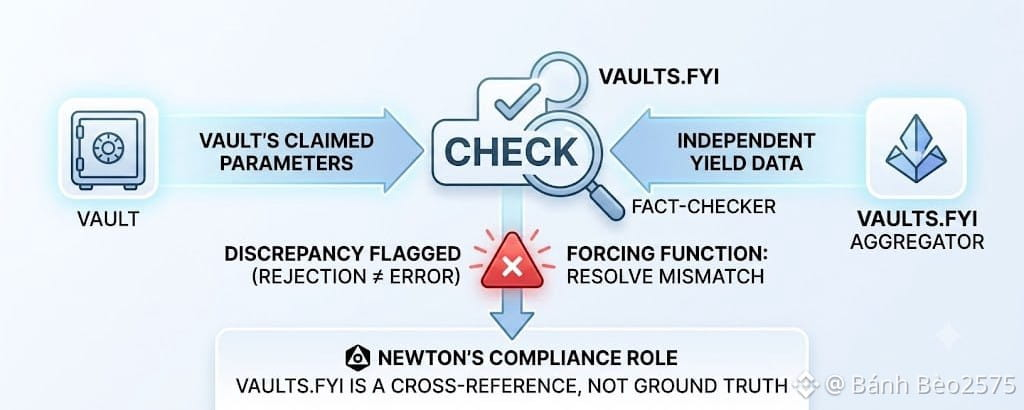
A vault's actual yield is determined by its own strategy, its own smart contract logic, its own realized returns from whatever positions it holds. Vaults.fyi separately aggregates yield figures across a wide set of vaults by pulling reported data and calculating comparable metrics across protocols. When a Newton policy pulls Vaults.fyi data into an enforcement check, it is not treating that aggregator as the definitive source of what a vault's yield actually is. It is using that aggregator's figure as a check against the vault's own claimed parameters, the same way a fact-checker cross-references a reporter's draft against an independent source before a story runs.
This distinction matters because it changes what a rejection actually means. If a Newton policy rejects a transaction because a reported yield figure does not reconcile with a vault's actual strategy parameters, that is not Newton saying Vaults.fyi's number is wrong, or saying the vault's own number is wrong. It is flagging a discrepancy between two sources that should agree and do not, exactly the way a fact-checker flags a claim that does not match the paper trail, without necessarily knowing yet which side of the discrepancy is the actual error.
Here is where the analogy gets genuinely useful rather than just decorative. A good fact-checking process does not stop at noticing that two things disagree. It creates a forcing function that requires someone, a reporter, an editor, in Newton's case a vault curator, to actually resolve the discrepancy before anything moves forward. That resolution might reveal the aggregator's data was stale or miscategorized. It might reveal the vault itself misrepresented its parameters, intentionally or through an honest configuration error. Either way, the mismatch gets caught and addressed before it reaches whoever was relying on the number, rather than silently propagating forward as if both sources agreed.
The tradeoff this creates is the same tradeoff every fact-checking process creates. False positives happen. A legitimate yield figure can get flagged simply because the aggregator's data lagged behind a genuine, honest update to the vault's strategy. That is not a sign the system is broken, it is the cost of having any cross-referencing check at all instead of blindly trusting a single source. A newsroom that never flags a true statement as questionable is probably not fact-checking rigorously enough to catch the false ones either.
What this framing corrects is the assumption, which I think a lot of people default to, that Newton simply pulls in Vaults.fyi data and treats it as ground truth for policy decisions. It does not. It uses that external data as a cross-reference, a second source checking a first source, exactly the structural role a fact-checker plays relative to a reporter's draft. The vault's own parameters remain the primary claim. Vaults.fyi is the check against that claim, not a replacement for it.
Newton's compliance domain uses Vaults.fyi the way a serious newsroom uses a fact-checker, as an independent cross-reference that flags discrepancies against a vault's own stated parameters rather than as a single trusted source of truth, which means a rejected transaction signals disagreement between two data points, not necessarily an error in either one specifically.
This reframing has a practical consequence for anyone building on top of Newton too. A curator whose policy trips a Vaults.fyi reconciliation check should not treat that as a verdict, it is closer to a prompt to go verify which side of the mismatch is actually correct. Building that verification step into an operational runbook, rather than treating every mismatch as an automatic hard stop, is the difference between using this check the way it was actually designed to function and treating a cross-reference tool as if it were a final, unappealable judge.