Сеть роботов может быстро обрабатывать задачи и все же стратегически терпеть неудачу, если обновления политики отстают от реальных инцидентов.
Большинство систем рассматривают управление как статическую документацию, в то время как операции меняются каждую неделю. Этот разрыв создает скрытый риск. Появляются новые режимы сбоя, операторы импровизируют, и правила отклоняются от реальности, пока крупный спор не заставит вмешаться в экстренном порядке. Скорость не является узким местом в этом сценарии. Реакция на управление.
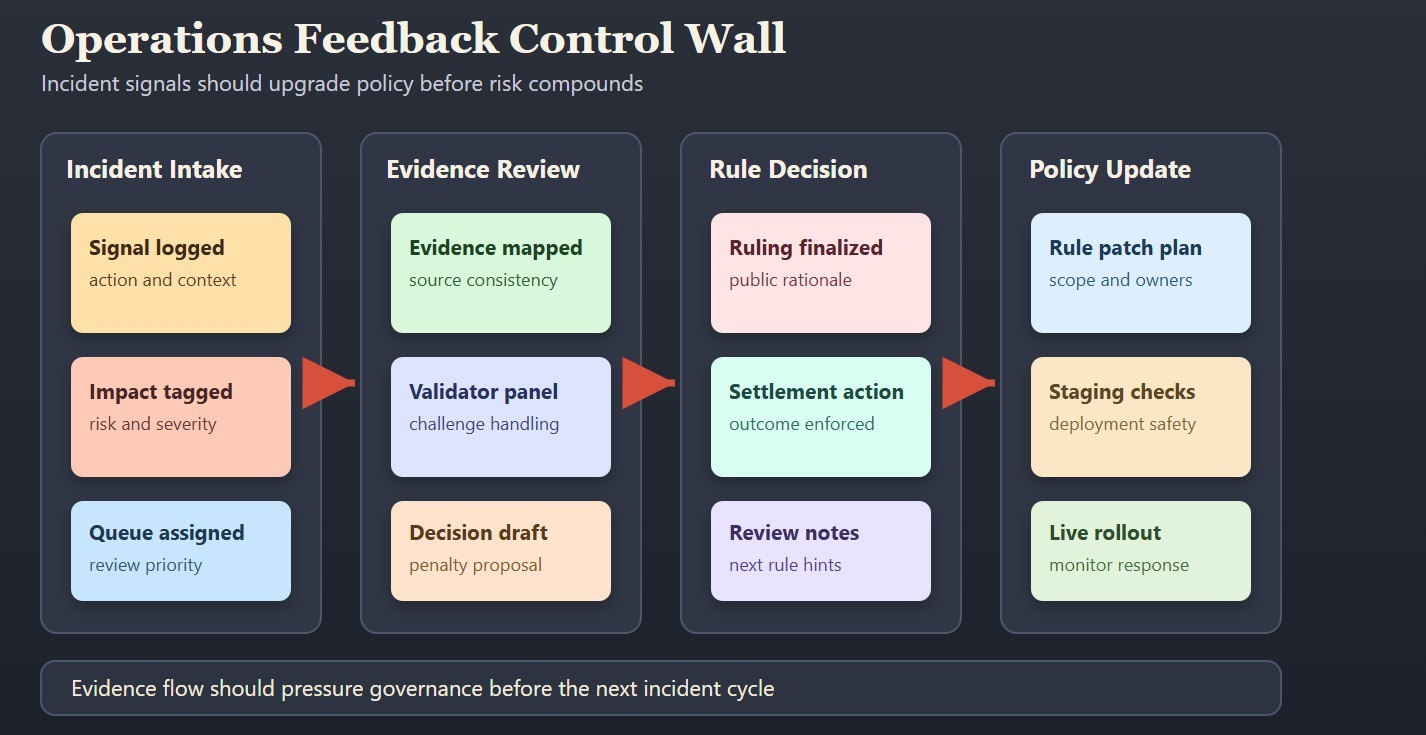
Формулировка Fabric полезна, потому что она связывает обратную связь от выполнения с публичной моделью координации, а не с закрытым кругом комитета. Механика вызовов, экономика валидаторов и видимые пути правил создают структуру, в которой доказательства из операций могут давить на изменения политики до того, как ущерб усугубится. Это более сильная теза надежности, чем "у нас есть хорошие модели и хорошие намерения."
Это также пересматривает, как я читаю `$ROBO`. Полезность и ценность управления должны приходить от реального использования контрольной поверхности: участие в надзоре, выравнивание стимулов и непрерывность эволюции правил под нагрузкой. Если эти механизмы активны, сеть может улучшаться под давлением. Если они неактивны, управление становится брендингом.
Для команд, разворачивающих долгосрочные роботизированные сервисы, практический вопрос не в том, происходят ли инциденты. Они будут. Ключевой вопрос в том, делает ли каждый инцидент систему более управляемой или более хрупкой.
Когда следующий оспариваемый результат робота поступит в производство, будет ли ваш уровень политики адаптироваться через публичные доказательства, или это будет зависеть от частных исключений и задержанного восстановления доверия?
@Fabric Foundation $ROBO #ROBO