я изучал легкий документ протокола SIGN и несколько демонстраций интеграции, в основном пытаясь понять, почему он постоянно появляется в инструментах распределения. на первый взгляд это кажется довольно простым — определить некоторые учетные данные, проверить их, а затем использовать это, чтобы решить, кто получит токены. что-то вроде формализации неаккуратных таблиц и скриптов, которые команды уже используют.
и да, я думаю, что именно так большинство людей это видит. уровень аттестации плюс некоторые встроенные механики аирдропа. полезно, но не совсем новый примитив.
но это не вся картина.
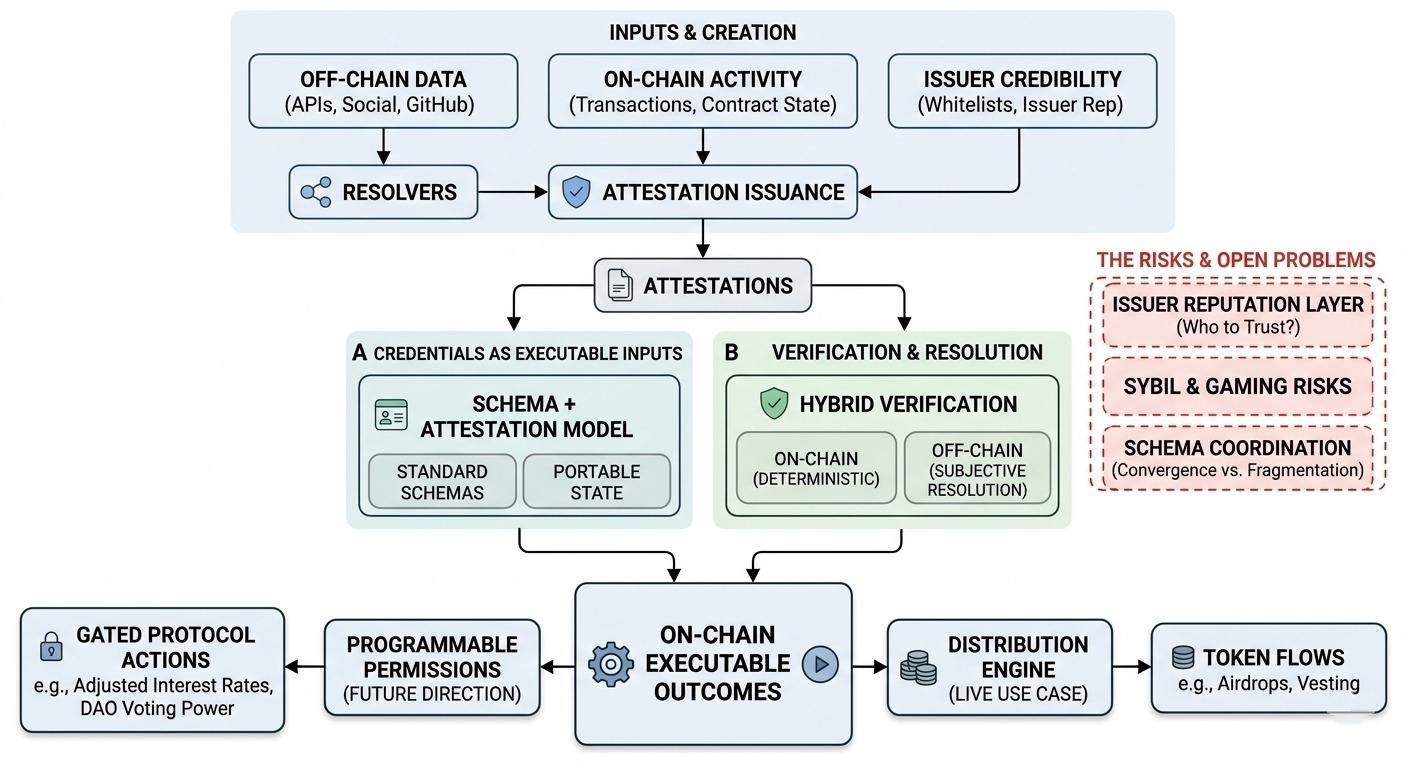
то, что SIGN тихо делает, — это превращение учетных данных во что-то исполняемое. не просто записи, которые вы запрашиваете, а входные данные, которые напрямую влияют на результаты на цепи. и как только учетные данные начинают вызывать действия — особенно потоки токенов — они перестают быть пассивными данными и начинают вести себя больше как инфраструктура.
первая часть — это модель схемы + аттестации. концептуально ничего нового — схемы определяют структуру, аттестации заполняют их утверждениями. но SIGN ориентируется на стандартизацию схемы таким образом, который предполагает повторное использование между приложениями. не просто «это приложение определяет учетные данные», а «эти учетные данные могут существовать независимо от любого отдельного приложения».
и вот здесь становится интересно. если схемы действительно становятся общими, то учетные данные начинают выглядеть как переносимое состояние. «история» или «репутация» пользователя не привязаны к одной системе. но это сильно зависит от координации. схемы имеют значение только в том случае, если несколько сторон согласны с ними, и это соглашение не обеспечивается протоколом.
некоторая часть этого уже в действии — проекты выдают аттестации и используют схемы внутри. но повторное использование между приложениями все еще кажется слабым. большинство команд, похоже, определяют, что им нужно, и двигаются дальше, вместо того чтобы основываться на общих стандартах.
второй механизм — это слой верификации, особенно гибридная модель. SIGN поддерживает как верификацию на цепи (детерминированную, основанную на контракте), так и оффчейн-резолюцию (внешние данные, API, эвристики). на бумаге это просто гибкость.
но вот в чем дело — смешивание этих двух создает разделенную границу доверия. верификация на цепи единообразна, все видят один и тот же результат. оффчейн-резолюция вводит субъективность, в зависимости от того, как реализованы и поддерживаются резолюторы.
так что теперь учетные данные — это не просто «истина или ложь», а «истина в зависимости от того, как вы это разрешаете». что нормально для данных из реального мира, но это усложняет составимость. два приложения могут использовать одну и ту же аттестацию, но прийти к немного разным выводам.
этот гибридный подход уже используется, особенно в проверках на соответствие, которые полагаются на оффчейн-сигналы. но стандартизация поведения резолютора или даже согласие по приемлемым отклонениям кажется открытой проблемой.
третье — это механизм распределения, который, вероятно, является самой конкретной частью на сегодняшний день. SIGN соединяет учетные данные напрямую с логикой распределения токенов. определяйте право на участие через аттестации, а затем выполняйте распределения без экспорта списков или написания пользовательских скриптов.
это явно в действии и используется. это снижает операционные затраты и делает распределения более воспроизводимыми. но это также смещает, где находится сложность. вместо того, чтобы вручную писать скрипты для распределений, вы кодируете логику в схемы и правила верификации.
и я не совсем уверен, что это всегда проще — просто по-другому. сложность перемещается из произвольных скриптов в структурированные определения, которые легче повторно использовать, но сложнее обдумывать, когда что-то идет не так.
более дальновидные части — постоянные слои идентичности, переносимость учетных данных между цепями, более глубокая интеграция кошельков — больше похожи на направление, чем на реальность. они зависят от повторного использования учетных данных в разных экосистемах, что снова возвращает к координации схем и доверию к эмитентам.
одна вещь, которую я продолжаю ставить под сомнение, — это доверие к эмитенту. если кто угодно может выдавать аттестации, то системе нужен какой-то способ их оценить. в противном случае вы получаете поток учетных данных с низким сигналом. SIGN не обеспечивает этот уровень — он оставляет это приложениям или будущим расширениям.
в итоге вы сталкиваетесь со второй проблемой: не просто верификация учетных данных, но и решение, какие эмитенты имеют значение. и это может быстро стать запутанным.
также интересно, как это будет работать в условиях противодействия. атаки Sybil, сговорящиеся эмитенты, использование схем — ни одно из этих явлений не уникально для SIGN, но протокол действительно делает легче операционализацию учетных данных в большом масштабе, что может усугубить эти проблемы.
любопытно по поводу:
* будут ли схемы действительно сходиться или оставаться фрагментированными по проекту
* как развиваются оффчейн-резолюторы и стандартизируются ли они
* если распределение остается основным случаем использования или просто точкой входа
* появление репутации эмитента или фильтрующих слоев
* реальные примеры повторного использования учетных данных в несвязанных экосистемах
#signdigitalsovereigninfra @SignOfficial $SIGN