

16 марта 2026 года официально открывается конференция GTC 2026 от NVIDIA, основатель и CEO NVIDIA Хуан Ренсюань выступает с ключевой речью.
На конференции, которая считается "годовым паломничеством в индустрии ИИ", Хуан Ренсюань объяснил трансформацию NVIDIA из "компании по производству чипов" в "компанию по производству ИИ-инфраструктуры". В ответ на наиболее волнующие рынок вопросы о стабильности производительности и возможностях роста, Хуан Ренсюань подробно раскрыл основные бизнес-логики, движущие будущим ростом — "экономика фабрики токенов".

Прогнозы по производительности крайне оптимистичны, "в 2027 году спрос составит не менее 10 триллионов долларов"
За последние два года глобальный спрос на вычисления в области искусственного интеллекта вырос в геометрической прогрессии. По мере того, как крупные модели эволюционируют от «восприятия» и «генерации» к «рассуждению» и «действию (выполнению задач)», потребление вычислительной мощности резко возросло. Что касается ограничений по заказам и доходам, которые вызывают большой интерес на рынке, Хуан Жэньсюнь дал чрезвычайно оптимистичные прогнозы.
В своей речи Хуан Жэньсюнь откровенно заявил:
Примерно в это же время в прошлом году я говорил, что мы ожидаем спрос на уровне высокой уверенности в размере 500 миллиардов долларов, охватывающий компании Blackwell и Rubin до 2026 года. Сейчас же, прямо сейчас, я ожидаю спрос как минимум в 1 триллион долларов до 2027 года.
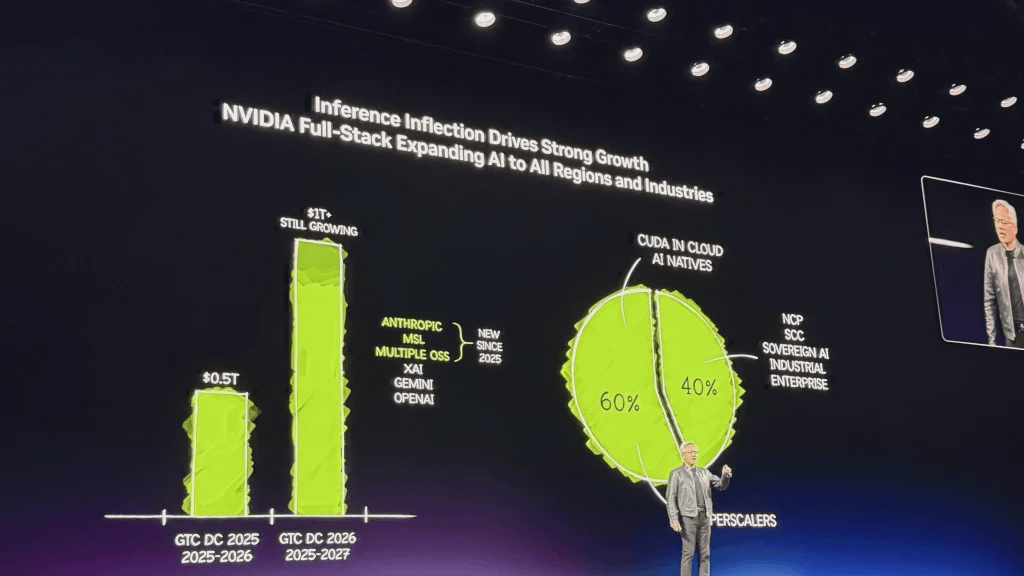
Триллионные прогнозы Дженсена Хуанга однажды подняли цену акций Nvidia более чем на 4,3%.
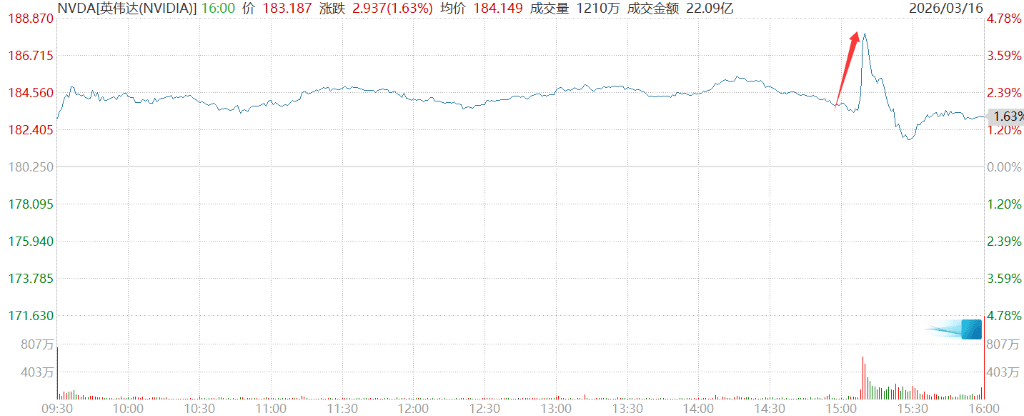
Кроме того, он добавил к этой цифре следующее:
Это разумно? Об этом я и собираюсь поговорить дальше. На самом деле, мы можем даже столкнуться с дефицитом предложения. Я уверен, что реальный спрос на вычислительные ресурсы будет намного выше.
Дженсен Хуанг отметил, что системы Nvidia доказали свою эффективность как «самая дешевая инфраструктура в мире». Благодаря возможности запуска моделей искусственного интеллекта практически в любой области, эта универсальность позволяет в полной мере использовать инвестиции клиентов в размере 1 триллиона долларов и обеспечить длительный срок службы.
В настоящее время 60% бизнеса Nvidia приходится на пять крупнейших поставщиков гипермасштабных облачных услуг, а оставшиеся 40% распределены по различным областям, таким как суверенные облачные сервисы, корпоративные решения, промышленность, робототехника и граничные вычисления.
Экономика токен-фабрики: производительность на ватт определяет жизнеспособность бизнеса.
Чтобы объяснить логику этого триллионного спроса, Дженсен Хуанг представил руководителям глобальных компаний совершенно новый подход к ведению бизнеса. Он отметил, что будущие центры обработки данных будут уже не складами для хранения файлов, а «фабриками» по производству токенов (базовых единиц, генерируемых искусственным интеллектом).

Хуан Жэньсюнь подчеркнул:
По определению, каждый центр обработки данных и каждый завод ограничены по мощности. Завод мощностью 1 ГВт (гигаватт) никогда не станет заводом мощностью 2 ГВт; это закон физики и атомной механики. При фиксированном уровне мощности тот, кто имеет наибольшую производительность на ватт, имеет наименьшие производственные затраты.
Дженсен Хуанг делит будущие сервисы на основе искусственного интеллекта на четыре бизнес-уровня:
Бесплатный тариф (высокая пропускная способность, низкая скорость)
Промежуточный уровень (примерно 3 доллара за миллион токенов)
Продвинутый уровень (примерно 6 долларов за миллион токенов)
Высокоскоростной слой (примерно 45 долларов за миллион токенов)
Сверхскоростной слой (примерно 150 долларов за миллион токенов)
Он отметил, что по мере увеличения размеров моделей и длины контекстов ИИ будет становиться умнее, но скорость генерации токенов будет снижаться. Дженсен Хуанг заявил:
На этой фабрике токенов ваша производительность и скорость генерации токенов напрямую отразятся на вашем доходе в следующем году.
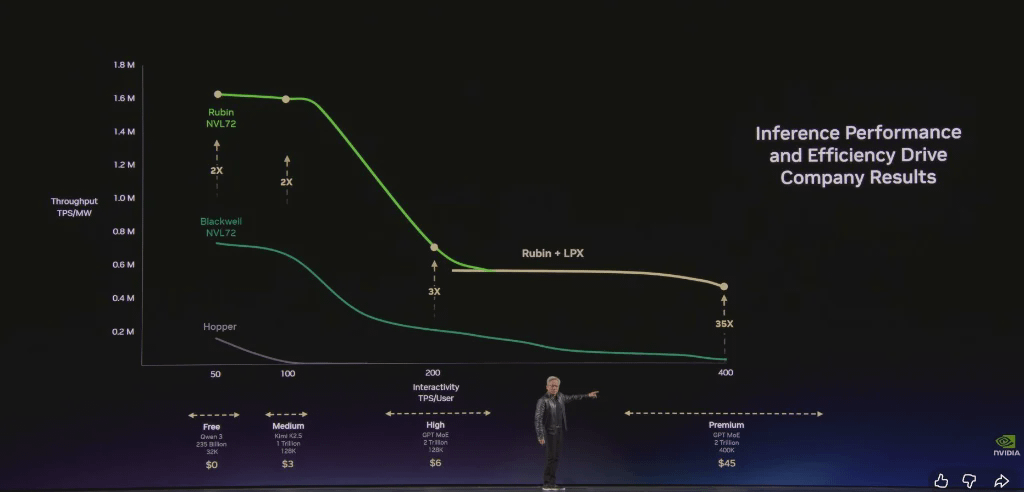
Дженсен Хуанг подчеркнул, что архитектура NVIDIA позволяет клиентам достигать чрезвычайно высокой пропускной способности в бесплатном тарифе, одновременно повышая производительность в поразительные 35 раз в самом дорогом тарифе для инференции.
Вера Рубин добилась 350-кратного ускорения за два года; Groq заполняет пробел в области сверхбыстрого логического мышления.
В условиях этих физических ограничений компания NVIDIA представила Vera Rubin, свою самую сложную вычислительную систему искусственного интеллекта за всю историю. Дженсен Хуанг заявил:
Раньше, когда я упоминал Hopper, я показывал чип, что было довольно мило. Но когда я упоминал Vera Rubin, люди думали обо всей системе. В этой системе со 100% жидкостным охлаждением, полностью исключающей традиционные кабели, стойку, на установку которой раньше уходило два дня, теперь можно собрать всего за два часа.
Дженсен Хуанг отметил, что благодаря сквозному совместному проектированию аппаратного и программного обеспечения Вера Рубин добилась поразительного скачка в объеме данных в рамках того же центра обработки данных мощностью 1 ГВт:
Всего за два года мы увеличили темп генерации токенов с 22 миллионов до 700 миллионов, что составляет 350-кратное увеличение. Закон Мура обеспечил лишь примерно 1,5-кратное увеличение за тот же период.
Для решения проблемы нехватки пропускной способности в условиях чрезвычайно высокой скорости обработки данных (например, 1000 токенов в секунду) NVIDIA представила свое окончательное решение, интегрировав приобретенную компанию Groq: асимметричную децентрализованную обработку данных. Дженсен Хуанг пояснил:
Эти два процессора имеют совершенно разные характеристики. Чип Groq имеет 500 МБ оперативной памяти, а чип Rubin — 288 ГБ памяти.

Дженсен Хуанг отметил, что NVIDIA, используя свою программную систему Dynamo, делегирует этап «предварительного заполнения», требующий огромных вычислительных мощностей и памяти, Вере Рубин, а чувствительный к задержкам этап «декодирования» — Groq. Хуанг также предложил рекомендации по конфигурации вычислительных мощностей для предприятий:
Если ваша работа в основном связана с высокой пропускной способностью, используйте Vera Rubin на 100%; если у вас большой спрос на генерацию ценных токенов на программном уровне, выделите 25% площади вашего дата-центра под Groq.
Стало известно, что чип Groq LP30 производства Samsung уже запущен в серийное производство и, как ожидается, поступит в продажу в третьем квартале, а первая стойка Vera Rubin уже работает в облаке Microsoft Azure.
Кроме того, что касается технологии оптических межсоединений, компания Jensen Huang представила первый в мире серийно выпускаемый оптический коммутатор в корпусе CPO, Spectrum X, тем самым успокоив рыночные дебаты по поводу подхода «медь на выходе, волокно на входе».
Нам необходимо увеличить производственные мощности по выпуску медных кабелей, оптических чипов и микросхем.
Агенты меняют традиционный подход к SaaS; "годовая зарплата + токен" стала стандартом в Силиконовой долине.
Помимо аппаратных барьеров, Хуанг посвятил значительную часть своего выступления революции в программном обеспечении и экосистемах искусственного интеллекта, в частности, появлению агентов.
Он назвал проект с открытым исходным кодом OpenClaw «самым популярным проектом с открытым исходным кодом в истории человечества», заявив, что он превзошел достижения Linux за последние 30 лет всего за несколько недель. Хуанг прямо заявил, что OpenClaw по сути является «операционной системой» для агентных компьютеров.
Хуан Жэньсюнь утверждал:
Каждая компания, предоставляющая SaaS-услуги (программное обеспечение как услуга), в будущем станет компанией, предоставляющей AaaS-услуги (агент как услуга). Несомненно, для обеспечения безопасного развертывания этих агентов, способных получать доступ к конфиденциальным данным и выполнять код, NVIDIA выпустила эталонный дизайн корпоративного уровня NeMo Claw, который включает в себя механизм политик и маршрутизатор конфиденциальности.
Для обычных работающих специалистов эта трансформация также не за горами. Дженсен Хуанг описывает новую форму рабочего места будущего:
В будущем каждому инженеру в нашей компании потребуется годовой бюджет в токенах. Их базовая годовая зарплата может составлять несколько сотен тысяч долларов, и я буду выделять примерно половину этой суммы в виде токенов, чтобы обеспечить им десятикратное повышение эффективности. Это уже новая тактика найма в Силиконовой долине: сколько токенов включает ваше предложение о работе?
В конце своей речи Дженсен Хуанг также представил предварительный обзор вычислительной архитектуры следующего поколения, Feynman, которая первой обеспечит горизонтальное масштабирование как медных проводов, так и CPO. Еще более интригующей является разработка Nvidia «Vera Rubin Space-1» — космического компьютера для центров обработки данных, который полностью открывает возможности для расширения вычислительной мощности ИИ за пределы Земли.
Полный текст выступления Дженсена Хуанга на конференции GTC 2026, переведенный ниже (с помощью инструментов искусственного интеллекта):
Ведущий: Приветствуем на сцене Дженсена Хуанга, основателя и генерального директора Nvidia.
Дженсен Хуанг, основатель и генеральный директор:
Добро пожаловать на GTC. Хочу напомнить всем, что это технологическая конференция. Мне очень приятно видеть столько людей, выстроившихся в очередь так рано утром, и видеть всех здесь сегодня.
На GTC мы сосредоточимся на трех основных темах: технологии, платформы и экосистема. В настоящее время у NVIDIA есть три основные платформы: платформа CUDA-X, системная платформа и наша недавно запущенная платформа AI Factory.
Прежде чем мы официально начнём, я хотел бы поблагодарить наших ведущих, которые подготовили нас к мероприятию: Сару Го из Conviction, Альфреда Лина из Sequoia Capital (первого венчурного капиталиста Nvidia) и Гэвина Бейкера, первого крупного институционального инвестора Nvidia. Эти трое обладают глубокими знаниями в области технологий и оказывают значительное влияние на всю технологическую экосистему. Конечно, я также хочу поблагодарить всех уважаемых гостей, которых я лично пригласил сегодня. Спасибо этой звёздной команде.
Я также хотел бы поблагодарить все компании, присутствовавшие сегодня. NVIDIA — это платформенная компания; у нас есть технологии, платформы и богатая экосистема. Компании, присутствовавшие сегодня, представляют почти всех игроков в индустрии стоимостью 100 триллионов долларов, и мы глубоко благодарны 450 компаниям, которые выступили спонсорами этого мероприятия.
На этой конференции будет представлено 1000 технических форумов и выступят 2000 докладчиков, которые охватят все уровни «пятислойной» архитектуры искусственного интеллекта — от инфраструктуры, такой как земля, электроэнергия и центры обработки данных, до микросхем, платформ, моделей и различных приложений, которые в конечном итоге движут всю отрасль вперед.
CUDA: Двадцать лет технологического прогресса
Всё началось здесь. В этом году отмечается 20-летие CUDA.
На протяжении двух десятилетий мы занимались разработкой этой архитектуры. CUDA — это революционное изобретение: технология SIMT (Single Instruction, Multithreaded) позволяет разработчикам писать программы на скалярном языке и расширять их до многопоточных приложений, что значительно упрощает программирование по сравнению с предыдущей архитектурой SIMD. Недавно мы добавили Tiles, чтобы упростить программирование тензорных ядер и различных математических структур, на которых основан современный искусственный интеллект. В настоящее время CUDA включает тысячи инструментов, компиляторов, фреймворков и библиотек, сотни тысяч публичных проектов в сообществе открытого исходного кода и глубоко интегрирована во все технологические экосистемы.
Эта диаграмма на 100% раскрывает стратегическую логику NVIDIA, и я показываю этот слайд с самого начала. Самым сложным и ключевым элементом является показатель «установленных систем» в нижней части диаграммы. За последние два десятилетия мы накопили сотни миллионов графических процессоров и вычислительных систем, работающих под управлением CUDA, по всему миру.
Наши графические процессоры охватывают все облачные платформы и используются практически всеми производителями компьютеров и в различных отраслях. Огромная база установленных приложений CUDA является основной причиной, по которой этот «маховик» продолжает ускоряться. База приложений привлекает разработчиков, разработчики создают новые алгоритмы и совершают прорывы, прорывы создают новые рынки, новые рынки формируют новые экосистемы и привлекают все больше компаний, что еще больше расширяет базу установленных приложений — этот «маховик» непрерывно ускоряется.
Количество загрузок библиотек NVIDIA растёт с поразительной скоростью, в огромных масштабах и с постоянно возрастающей скоростью. Этот «маховик» позволяет нашей вычислительной платформе поддерживать огромное количество приложений и постоянный поток новых прорывных разработок.
Что еще более важно, это также обеспечивает этим инфраструктурам чрезвычайно долгий срок службы. Причина очевидна: приложения, которые могут работать на NVIDIA CUDA, невероятно разнообразны, охватывая все этапы жизненного цикла ИИ, различные платформы обработки данных и широкий спектр научных решателей. Поэтому, после установки графического процессора NVIDIA, его практическая ценность чрезвычайно высока. Именно поэтому цена наших графических процессоров архитектуры Ampere, выпущенных нами шесть лет назад, фактически выросла.
В основе всего этого лежит наша огромная база установленных систем, мощная архитектура «маховика» и обширная экосистема разработчиков. Когда эти факторы работают вместе, в сочетании с нашими постоянными обновлениями программного обеспечения, вычислительные затраты неуклонно снижаются. Ускоренные вычисления значительно улучшают производительность приложений, а благодаря нашей долгосрочной поддержке и постоянному совершенствованию программного обеспечения пользователи не только ощущают первоначальный скачок производительности, но и получают выгоду от постоянного снижения вычислительных затрат. Мы стремимся обеспечить долгосрочную поддержку каждой видеокарты в мире, поскольку они архитектурно совместимы.
Мы готовы на это из-за огромного масштаба внедрения — каждый новый релиз с оптимизацией приносит пользу миллионам пользователей. Это динамичное сочетание позволяет архитектурам NVIDIA постоянно расширять свои возможности и ускорять собственный рост, одновременно снижая вычислительные затраты и, в конечном итоге, стимулируя дальнейший рост. В основе всего этого лежит CUDA.
От GeForce до CUDA: 25-летняя эволюция.
Наше сотрудничество с CUDA началось 25 лет назад.
GeForce — многие из вас выросли с GeForce. GeForce — это самая успешная маркетинговая программа NVIDIA. Мы начали привлекать будущих клиентов, когда вы еще не могли позволить себе нашу продукцию — ваши родители стали первыми пользователями NVIDIA, покупая наши продукты год за годом, пока однажды вы не выросли в выдающихся специалистов по информатике и не стали настоящими клиентами и разработчиками.
Это фундамент, заложенный GeForce 25 лет назад. Двадцать пять лет назад мы изобрели программируемый шейдер — очевидное, но глубокое изобретение, сделавшее ускорители программируемыми, и первый в мире программируемый ускоритель — пиксельный шейдер. Пять лет спустя мы создали CUDA — одну из самых важных инвестиций, которые мы когда-либо делали. Имея ограниченные ресурсы, мы вложили подавляющую часть нашей прибыли в расширение поддержки CUDA от GeForce до каждого компьютера. Мы были так полны решимости, потому что верили в его потенциал. Несмотря на первоначальные трудности, компания придерживалась этой веры на протяжении 13 поколений, целых двух десятилетий, и сегодня CUDA повсеместно распространена.
Именно пиксельные шейдеры стали движущей силой революции GeForce. А около восьми лет назад мы представили RTX — полную архитектурную перестройку для современной эпохи компьютерной графики. GeForce подарила миру CUDA, и именно благодаря этому многие ученые, включая Алекса Крижевского, Илью Суцкевера, Джеффри Хинтона и Эндрю Нга, обнаружили, что графические процессоры могут стать мощным инструментом для ускорения глубокого обучения, что и положило начало взрывному росту искусственного интеллекта десять лет назад.
Десять лет назад мы решили объединить программируемое затенение с двумя совершенно новыми концепциями: аппаратной трассировкой лучей, что технически было чрезвычайно сложной задачей, и дальновидной на тот момент идеей — мы предвидели около десяти лет назад, что ИИ произведет революцию в компьютерной графике. Так же, как GeForce представил миру ИИ, ИИ теперь, в свою очередь, изменит способ реализации компьютерной графики.
Сегодня я покажу вам будущее. Это наша технология графики следующего поколения, которую мы называем нейронным рендерингом — глубокое слияние 3D-графики и искусственного интеллекта. Это DLSS 5, пожалуйста, взгляните.
Нейронная визуализация: слияние структурированных данных и генеративного искусственного интеллекта.
Разве это не захватывает дух? Компьютерная графика ожила.
Что мы сделали? Мы объединили управляемую 3D-графику (реальную основу виртуального мира) со структурированными данными, а затем внедрили генеративный ИИ и вероятностные вычисления. Один подход полностью детерминирован, другой — вероятностный, но при этом очень реалистичный. Мы объединили эти две концепции, добившись точного управления с помощью структурированных данных и генерируя контент в реальном времени. В конечном итоге, контент получился одновременно визуально потрясающим и полностью управляемым.
Концепция интеграции структурированной информации с генеративным искусственным интеллектом будет продолжать развиваться в различных отраслях. Структурированные данные являются краеугольным камнем надежного ИИ.
Платформа ускорения обработки структурированных и неструктурированных данных.
Сейчас я покажу вам схему технической архитектуры.
Структурированные данные — хорошо известные платформы, такие как SQL, Spark, Pandas, Velox, а также важные платформы, такие как Snowflake, Databricks, Amazon EMR, Azure Fabric и Google BigQuery — все они обрабатывают фреймы данных. Эти фреймы данных похожи на гигантские электронные таблицы, содержащие всю информацию из мира бизнеса и представляющие собой эталонные данные для корпоративных вычислений.
В эпоху искусственного интеллекта нам необходимо дать ИИ возможность использовать структурированные данные и ускорить этот процесс до предела. В прошлом ускорение обработки структурированных данных служило лишь повышению эффективности работы предприятий. В будущем ИИ будет использовать эти структуры данных со скоростью, значительно превышающей скорость человека, а агенты ИИ будут широко использовать структурированные базы данных.
Что касается неструктурированных данных, то векторные базы данных, PDF-файлы, видео и аудио составляют подавляющее большинство форматов данных в мире — примерно 90% данных, генерируемых ежегодно, являются неструктурированными. В прошлом эти данные были практически полностью непригодны для использования: мы читали их, хранили в файловых системах, и на этом всё. Мы не могли делать по ним запросы, и извлечение данных было затруднено, поскольку неструктурированные данные не имели простых методов индексирования; нам приходилось понимать их смысл и контекст. Теперь это может делать искусственный интеллект — используя технологии мультимодального восприятия и понимания, ИИ может читать PDF-документы, понимать их смысл и встраивать их в более крупную, доступную для запросов структуру.
Компания Nvidia создала для этой цели две базовые библиотеки:
cuDF: Используется для ускоренной обработки фреймов данных и структурированных данных.
cuVS: Используется для хранения векторов, семантических данных и обработки неструктурированных данных для ИИ.
Эти две платформы станут одной из важнейших основополагающих платформ в будущем.
Сегодня мы объявили о партнерстве с несколькими компаниями. IBM — изобретатель языка SQL — будет использовать cuDF для ускорения своей платформы обработки данных WatsonX. Dell сотрудничает с нами в создании платформы Dell AI Data Platform, интегрируя cuDF и cuVS, и добилась значительного повышения производительности в реальных проектах в NTT Data. Что касается Google Cloud, мы теперь ускоряем не только Vertex AI, но и BigQuery, и сотрудничаем со Snapchat, чтобы снизить затраты на вычисления почти на 80%.
Преимущества ускоренных вычислений тройные: скорость, масштабируемость и стоимость. Это соответствует логике закона Мура — достижение скачков производительности за счет ускоренных вычислений при постоянной оптимизации алгоритмов, чтобы все могли извлечь выгоду из постоянно снижающихся вычислительных затрат.
Компания NVIDIA разработала платформу ускоренных вычислений, объединяющую множество библиотек, включая RTX, cuDF и cuVS. Эти библиотеки интегрированы в глобальные облачные сервисы и сети OEM-производителей, обеспечивая доступ к ним пользователям по всему миру.
Тесное сотрудничество с поставщиками облачных услуг
Партнерские отношения с крупными поставщиками облачных услуг.
Google Cloud: Мы ускоряем разработку Vertex AI и BigQuery, обеспечиваем глубокую интеграцию с JAX/XLA и преуспеваем в работе с PyTorch — NVIDIA является единственным в мире акселератором, преуспевающим как в PyTorch, так и в JAX/XLA. Мы привлекли в экосистему Google Cloud таких клиентов, как Base10, CrowdStrike, Puma и Salesforce.
AWS: Мы ускоряем внедрение EMR, SageMaker и Bedrock, которые глубоко интегрированы с AWS. Больше всего в этом году меня радует то, что мы интегрируем OpenAI в AWS, что значительно увеличит рост потребления облачных вычислений на AWS и поможет OpenAI расширить региональные развертывания и масштабы вычислений.
Microsoft Azure: Суперкомпьютер NVIDIA мощностью 100 PFLOPS — это первый суперкомпьютер, который мы создали и первый, развернутый в Azure, что заложило важную основу для нашего сотрудничества с OpenAI. Мы ускоряем работу облачных сервисов Azure и AI Foundry, сотрудничаем в расширении региона Azure и активно работаем над поиском Bing. Примечательно, что наши возможности **конфиденциальных вычислений** — гарантирующие, что даже операторы связи не смогут просматривать данные пользователей и модели — делают графические процессоры NVIDIA одними из первых в мире, поддерживающих конфиденциальные вычисления, что позволяет безопасно развертывать модели OpenAI и Anthropics в облачных средах по всему миру. Например, совместно с Synopsys мы ускорили все рабочие процессы EDA и CAD и развернули их в Microsoft Azure.
Oracle: Мы были первым клиентом Oracle, внедрившим ИИ, и я горжусь тем, что первым объяснил Oracle концепцию облачных решений на основе ИИ. С тех пор компания быстро развивалась, и мы привлекли для нее множество партнеров, включая Cohere, Fireworks и OpenAI.
CoreWeave: Первая в мире облачная платформа, разработанная специально для размещения графических процессоров и облачных сервисов ИИ, может похвастаться отличной клиентской базой и высокими темпами роста.
Palantir + Dell: Три компании совместно создали совершенно новую платформу искусственного интеллекта на основе Ontology Platform и AI Platform от Palantir, которая позволяет развертывать ИИ в любой стране и в любой среде с воздушной изоляцией полностью локализованным образом — охватывая все, от обработки данных (векторизации или структурирования) до полного стека ускоренных вычислений для ИИ.
Компания NVIDIA заключила это особое партнерство с глобальными поставщиками облачных услуг — мы помогаем клиентам перейти в облако, создавая взаимовыгодную экосистему.
Вертикальная интеграция и горизонтальная открытость: основная стратегия Nvidia.
Nvidia — первая в мире вертикально интегрированная и горизонтально открытая компания.
Необходимость этой модели очень проста: ускорение вычислений — это не проблема чипа или системы; его полное описание должно звучать как ускорение приложений. Процессоры могут в целом ускорить работу компьютеров, но этот путь достиг своего предела. В будущем только ускорение, специфичное для конкретного приложения или предметной области, сможет и дальше обеспечивать скачки производительности и снижение затрат.
Именно поэтому NVIDIA должна глубоко погружаться в изучение одной библиотеки за другой, одной области за другой и одной вертикальной отрасли за другой. Мы — вертикально интегрированная вычислительная компания; другого пути нет. Мы должны понимать приложения, понимать области применения, глубоко понимать алгоритмы и иметь возможность развертывать их в любом сценарии — в центрах обработки данных, облаке, локально, на периферии и даже в роботизированных системах.
В то же время NVIDIA придерживается горизонтально-открытого подхода, стремясь интегрировать свои технологии в платформы любых партнеров, чтобы мир мог пользоваться преимуществами ускоренных вычислений.
Структура участников GTC в этом году прекрасно иллюстрирует этот тезис. Наибольшая доля участников пришлась на индустрию финансовых услуг – мы надеемся увидеть разработчиков, а не трейдеров. Наша экосистема охватывает как восходящие, так и нисходящие цепочки поставок. Независимо от того, 50, 70 или 150 лет компании, прошлый год стал для нее лучшим за всю историю. Мы находимся на старте чего-то очень и очень значимого.
CUDA-X: Ускоренная вычислительная платформа для различных отраслей промышленности
Компания Nvidia имеет значительное присутствие в различных отраслях промышленности:
Автономное вождение: широкомасштабные и далеко идущие последствия.
Финансовые услуги: Количественное инвестирование переходит от ручной разработки признаков к глубокому обучению на основе суперкомпьютеров, что знаменует собой «момент трансформации».
Здравоохранение: наступает «момент ChatGPT», охватывающий такие области, как разработка лекарств с помощью ИИ, диагностика на основе ИИ и обслуживание клиентов в сфере здравоохранения.
Промышленность: В мире разворачивается крупнейшая волна строительства, повсюду появляются заводы по производству искусственного интеллекта, микросхем и центров обработки данных.
Развлечения и игры: платформа искусственного интеллекта в режиме реального времени поддерживает перевод, прямые трансляции, взаимодействие в играх и интеллектуальных агентов для совершения покупок.
Робототехника: На этой выставке было представлено 110 роботов, обладающих более чем десятилетним опытом и полным набором трех основных компьютерных архитектур (учебный компьютер, имитационный компьютер и бортовой компьютер).
Телекоммуникации: отрасль, оцениваемая примерно в 2 триллиона долларов, – базовые станции будут эволюционировать от выполнения отдельных коммуникационных функций до создания инфраструктурных платформ на основе искусственного интеллекта. Одна из таких платформ, Aerial, тесно сотрудничает с такими компаниями, как Nokia и T-Mobile.
В основе всех этих областей лежат наши библиотеки CUDA-X — сама основа NVIDIA как компании, занимающейся алгоритмами. Эти библиотеки являются наиболее ценными активами компании, позволяя вычислительной платформе приносить реальную пользу в различных отраслях.
Одной из важнейших библиотек является cuDNN (библиотека глубоких нейронных сетей CUDA), которая произвела революцию в искусственном интеллекте и положила начало взрывному росту современного ИИ.
(Воспроизведение демонстрационного видеоролика CUDA-X)
Всё, что вы только что видели, было симуляцией — включая решатель на основе физических принципов, физическую модель с поддержкой ИИ и физическую модель робота с ИИ. Всё это было симуляцией; не было никакой рисованной вручную анимации или настройки суставов. Именно в этом и заключается ключевая компетенция NVIDIA: раскрытие этих возможностей благодаря глубокому пониманию алгоритмов и органичной интеграции вычислительных платформ.
Предприятия, изначально созданные на основе искусственного интеллекта, и новая эра вычислительной техники.
Вы только что увидели гигантов индустрии, определяющих современное общество, таких как Walmart, L'Oréal, JPMorgan Chase, Roche и Toyota, а также большое количество компаний, о которых вы никогда раньше не слышали — так называемые компании, изначально ориентированные на искусственный интеллект. Этот список чрезвычайно обширен и включает в себя OpenAI, Anthropic и множество новых компаний, работающих в различных вертикальных секторах.
За последние два года отрасль пережила феноменальный рост. Приток венчурного капитала в стартапы достиг рекордных 150 миллиардов долларов. Что еще важнее, размер одной инвестиции впервые вырос с миллионов долларов до сотен миллионов или даже миллиардов долларов. Причина лишь в одном: впервые в истории каждой компании в этом секторе требуются огромные вычислительные ресурсы и большое количество токенов. Отрасль создает, генерирует или повышает ценность токенов от таких организаций, как Anthropic и OpenAI.
Подобно тому, как революция персональных компьютеров, интернет-революция и революция мобильных облачных вычислений породили множество компаний, изменивших эпоху, нынешнее поколение трансформации вычислительных платформ также породит ряд весьма влиятельных компаний, которые станут важной силой в мире будущего.
Три исторических прорыва, которые привели ко всему этому.
Что именно произошло за последние два года? Три крупных события.
Во-первых: ChatGPT, открывающий эру генеративного ИИ (конец 2022 – 2023 гг.)
Оно способно не только воспринимать и понимать, но и генерировать уникальный контент. Я продемонстрировал слияние генеративного ИИ и компьютерной графики. Генеративный ИИ коренным образом меняет наш способ вычислений — от поиска информации к генеративному — оказывая глубокое влияние на архитектуру компьютеров, методы развертывания и общее значение.
Второй вариант: Рассуждающий ИИ, представленный O1.
Способность к рассуждению позволяет ИИ самоанализировать, планировать и разбивать проблемы на этапы, которые он не может понять напрямую. Это делает генеративный ИИ правдоподобным, способным рассуждать на основе информации из реального мира. Для достижения этого значительно увеличивается количество токенов во входном контексте и количество выходных токенов, используемых для рассуждений, что приводит к существенному увеличению вычислительной сложности.
Третий вариант: Клод Код, первая модель интеллектуального агента.
Он может читать файлы, писать код, компилировать, тестировать, оценивать и итеративно выполнять операции. Claude Code произвел революцию в разработке программного обеспечения — 100% инженеров NVIDIA используют один или несколько инструментов: Claude Code, Codex и Cursor; ни один разработчик программного обеспечения не обходится без помощи ИИ.
Это совершенно новый поворотный момент — вы больше не спрашиваете ИИ «что, где и как», а позволяете ему «создавать, выполнять и строить», давая ему возможность активно использовать инструменты, читать файлы, анализировать проблемы и предпринимать действия. ИИ эволюционировал от восприятия к генерации, к рассуждению, и теперь он действительно может делать дела.
За последние два года вычислительные затраты, необходимые для вывода результатов, увеличились примерно в 10 000 раз, а объем использования — примерно в 100 раз. Я всегда считал, что вычислительные затраты за последние два года выросли в миллион раз — это общее ощущение, которое разделяют все, OpenAI и Anthropic. Увеличение вычислительной мощности приводит к увеличению количества токенов, росту доходов и повышению интеллекта ИИ. Переломный момент для вывода результатов настал.
Эра триллионной инфраструктуры искусственного интеллекта
В это же время в прошлом году я говорил, что мы очень уверены в объеме спроса и заказов Blackwell и Rubin, которые, по оценкам, составят приблизительно 500 миллиардов долларов до 2026 года. Сегодня, спустя год после GTC, я могу сказать вам: если смотреть в будущее, до 2027 года, я вижу цифру как минимум в 1 триллион долларов. И я убежден, что реальный спрос на вычислительные ресурсы будет намного выше.
2025: Год дедукции от Nvidia
2025 год — это год инференции для NVIDIA. Наша цель — обеспечить высочайшее качество на каждом этапе жизненного цикла ИИ, начиная с обучения и заканчивая постобучением, позволяя инвестированной инфраструктуре продолжать эффективно работать с более длительным сроком службы и меньшей себестоимостью единицы продукции.
Одновременно с этим компании Anthropic и Meta официально присоединились к платформе NVIDIA, совместно представляя треть мирового спроса на вычислительные мощности для ИИ. Модели с открытым исходным кодом приближаются к передовым уровням и повсеместно распространены.
В настоящее время NVIDIA — единственная в мире платформа, способная запускать все модели ИИ во всех областях — лингвистике, биологии, компьютерной графике, компьютерном зрении, речи, белковедении и химии, робототехнике и т. д. — как на периферии сети, так и в облаке, независимо от языка программирования. Архитектура NVIDIA универсальна для всех этих сценариев, что делает нас самой недорогой и надежной платформой.
В настоящее время 60% бизнеса NVIDIA приходится на пять крупнейших мировых поставщиков гипермасштабных облачных услуг, а оставшиеся 40% распределены по различным областям, таким как региональные облака, суверенные облака, корпоративные решения, промышленное оборудование, робототехника и периферийные вычисления. Широкий охват искусственного интеллекта сам по себе является источником устойчивости компании — это, несомненно, совершенно новая революция в вычислительных платформах.
Грейс Блэквелл и NVLink 72: смелые архитектурные инновации
В период расцвета архитектуры Hopper мы решили полностью перепроектировать систему, расширив NVLink с 8-канального до NVLink 72 и всесторонне декомпозировав и реконструировав вычислительную систему. Разработка NVLink 72 была огромным технологическим риском, и это было непросто для всех наших партнеров. Мы хотели бы выразить искреннюю благодарность всем, кто принимал участие в этом проекте.
Одновременно с этим мы представили NVFP4 — не просто обычный FP4, а совершенно новый тип тензорного ядра и вычислительного блока. Мы продемонстрировали, что NVFP4 позволяет выполнять вывод без потери точности, обеспечивая при этом значительное повышение производительности и энергоэффективности, и он одинаково хорошо подходит для обучения. Кроме того, появился ряд новых алгоритмов, таких как Dynamo и TensorRT-LLM, и мы даже инвестировали миллиарды долларов в создание суперкомпьютера, специально предназначенного для оптимизации ядер, под названием DGX Cloud.
Результаты демонстрируют нашу замечательную производительность в области вывода данных. Данные SemiAnalysis — самого полного на сегодняшний день теста производительности ИИ в области вывода данных — показывают, что NVIDIA значительно опережает нас как по показателю токенов на ватт, так и по стоимости токенов. Закон Мура мог бы обеспечить 1,5-кратное повышение производительности для H200, но мы достигли 35-кратного. Дилан Патель из SemiAnalysis даже сказал: «Хуанг занижает оценку; на самом деле это 50-кратное увеличение». И он прав.
Хочу процитировать его слова: «Дженсен занизил репортаж (Хуан Жэньсюнь был осторожен в своих сообщениях)».
Стоимость одного токена у Nvidia самая низкая в мире, на данный момент не имеющая аналогов среди других компаний. Причина кроется в её концепции Extreme Co-design (экстремальный совместный дизайн).
Взяв в качестве примера Fireworks, до обновления программного обеспечения и алгоритмов NVIDIA средняя скорость обработки токенов составляла около 700 токенов в секунду; после обновления она приблизилась к 5000 токенов в секунду, что примерно в 7 раз больше. В этом и заключается сила эффективного совместного проектирования.
Фабрика ИИ: от центра обработки данных до фабрики токенов.
Раньше центры обработки данных были местами для хранения файлов; теперь это фабрики по производству токенов. В будущем каждый поставщик облачных услуг и каждая компания, занимающаяся искусственным интеллектом, будут использовать показатель «эффективности фабрики токенов» в качестве ключевого операционного критерия.
Вот мой главный аргумент:
Вертикальная ось: Пропускная способность – количество токенов, генерируемых в секунду при фиксированном уровне мощности.
Горизонтальная ось: Скорость обработки токенов – скорость ответа на каждом шаге вывода. Чем выше скорость, тем больше полезная модель, тем длиннее контекст и тем интеллектуальнее ИИ.
Этот токен представляет собой новый товар, цена которого будет дифференцирована по мере его созревания.
Бесплатный тариф (высокая пропускная способность, низкая скорость)
Промежуточный уровень (примерно 3 доллара за миллион токенов)
Продвинутый уровень (примерно 6 долларов за миллион токенов)
Высокоскоростной слой (примерно 45 долларов за миллион токенов)
Сверхскоростной слой (примерно 150 долларов за миллион токенов)
По сравнению с Hopper, Grace Blackwell обеспечивает в 35 раз большую пропускную способность на самом высоком уровне и вводит совершенно новые уровни. Используя упрощенную модель, распределяя 25% мощности между четырьмя уровнями, Grace Blackwell могла бы получать в 5 раз больше дохода, чем Hopper.
Вера Рубин: Вычислительная система искусственного интеллекта следующего поколения
(Воспроизводится видеоролик, представляющий систему Веры Рубин)
Vera Rubin — это комплексная, оптимизированная под сквозное использование система, разработанная специально для агентских рабочих нагрузок:
Основной вычислительный блок для крупномасштабных языковых моделей: кластер из 72 графических процессоров NVLink, отвечающий за предварительное заполнение и кэширование ключ-значение.
Совершенно новый процессор Vera: разработан для чрезвычайно высокой производительности в однопоточном режиме, использует память LPDDR5 и отличается исключительной энергоэффективностью. Это единственный в мире процессор для центров обработки данных, использующий LPDDR5, что делает его идеальным для инструментов, работающих на основе искусственного интеллекта.
Система хранения данных: BlueField 4 + CX 9 — совершенно новая платформа хранения данных для эпохи искусственного интеллекта, занимающая 100% глобальное присутствие в индустрии хранения данных.
CPO Spectrum X Switch: первый в мире оптический Ethernet-коммутатор в корпусе, запущенный в полномасштабное серийное производство.
Kyber Rack: Совершенно новая стоечная система, поддерживающая 144 графических процессора, образующих единый домен NVLink, с фронтальной вычислительной частью и бэкэнд-коммутацией NVLink, формирующая суперкомпьютер.
Rubin Ultra: суперкомпьютерный узел нового поколения с вертикально интегрированной конструкцией, совместимый со стойками Kyber и поддерживающий межсоединения NVLink большего масштаба.
Система Vera Rubin теперь полностью охлаждается жидкостью, что сокращает время установки с двух дней до двух часов. В ней используется охлаждение горячей водой температурой 45°C, что значительно снижает нагрузку на центры обработки данных. Я очень рад, что Сатья Наделла подтвердил запуск первой стойки Vera Rubin на платформе Microsoft Azure.
Интеграция с Groq: максимальное расширение возможностей вывода данных.
Мы приобрели команду Groq и получили лицензию на их технологию. Groq — это детерминированный процессор потоковой обработки данных, использующий статическую компиляцию и планирование компилятора, обладающий большим объемом SRAM, оптимизированный для рабочих нагрузок с одним выводом и отличающийся чрезвычайно низкой задержкой и чрезвычайно высокой скоростью генерации токенов.
Однако ограниченный объем памяти Groq (500 МБ встроенной SRAM) затрудняет независимую обработку параметров и кэша ключ-значение больших моделей, что ограничивает его широкомасштабное применение.
Решение — Dynamo, программное обеспечение для планирования процессов вывода. Мы используем Dynamo для разделения конвейера вывода:
Предварительное заполнение и декодирование механизма внимания выполняются на Vera Rubin (что требует значительных вычислительных мощностей и объема кэш-памяти типа ключ-значение).
Декодирование в сети прямого распространения, или генерация токенов, выполняется на платформе Groq (требующей чрезвычайно высокой пропускной способности и низкой задержки).
Эти два устройства тесно связаны по Ethernet, а специальный режим снижает задержку примерно вдвое. Благодаря унифицированному планированию Dynamo, «операционной системе для фабрик ИИ», общая производительность повышается в 35 раз, и открывается новый уровень производительности обработки данных, ранее недостижимый для NVLink 72.
Рекомендации по сочетанию препаратов Groq и Vera Rubin:
Если основная нагрузка связана с высокой пропускной способностью, используйте 100% Веру Рубин.
Если значительная часть работы связана с генерацией ценных токенов, таких как код, можно использовать Groq, рекомендуемое соотношение составляет примерно 25% Groq + 75% Vera Rubin.
Наушники Groq LP30 производятся компанией Samsung и в настоящее время находятся в серийном производстве, начало поставок ожидается в третьем квартале. Благодарим компанию Samsung за всестороннее сотрудничество.
Исторический скачок в эффективности рассуждений.
Количественная оценка предыдущих технологических достижений: в течение двух лет скорость генерации токенов на фабрике искусственного интеллекта мощностью 1 гигаватт увеличится с 22 миллионов токенов в секунду до 700 миллионов токенов в секунду, то есть в 350 раз. В этом сила предельно эффективного совместного проектирования.
Технологическая дорожная карта
Blackwell: В настоящее время производится стандартная стоечная система Oberon, медный кабель расширен до NVLink 72, опционально оптическое расширение до NVLink 576.
Вера Рубин (в настоящее время): стойка Kyber, NVLink 144 (медный кабель); стойка Oberon, NVLink 72 + оптический кабель, расширенный до NVLink 576; Spectrum 6, первый в мире коммутатор CPO.
Vera Rubin Ultra (скоро в продаже): Графический процессор следующего поколения Rubin Ultra, чип LP35 (впервые интегрированный NVFP4), обеспечивающий многократное повышение производительности.
Feynman (следующее поколение): совершенно новый графический процессор, чип LP40 (совместно разработанный NVIDIA и командой Groq, интегрирующий NVFP4); совершенно новый центральный процессор — Rosa (Rosalyn); BlueField 5; CX 10; и стойки Kyber, поддерживающие как медные кабели, так и расширение CPO.
План действий ясен: параллельно реализуются три направления — расширение производства медных кабелей, расширение производства оптических кабелей (Scale-Up) и расширение производства оптических кабелей (Scale-Out). Нам необходимо, чтобы все наши партнеры постоянно наращивали производственные мощности по выпуску медных кабелей, оптических волокон и медных кабелей.
NVIDIA DSX: платформа цифровых двойников для фабрики искусственного интеллекта.
Фабрики искусственного интеллекта становятся все более сложными, но различные поставщики технологий, которые в них участвуют, никогда не сотрудничали друг с другом на этапе проектирования, а лишь «встречались» в центре обработки данных — чего явно недостаточно.
С этой целью мы создали Omniverse и построенную на её основе платформу NVIDIA DSX — платформу для всех партнеров, позволяющую совместно проектировать и управлять фабриками искусственного интеллекта гигаваттного масштаба в виртуальном мире. DSX предоставляет:
Системы моделирования механических, тепловых, электрических и сетевых параметров на уровне стойки.
Подключение к электросети обеспечивает скоординированное энергосберегающее диспетчерское управление.
Динамическая оптимизация энергопотребления и охлаждения в центрах обработки данных на основе алгоритма Max-Q
По консервативным оценкам, эта система может повысить энергоэффективность примерно в 2 раза, что является очень существенным преимуществом в масштабах, которые мы обсуждаем. Начиная с проекта Digital Earth, Omniverse будет поддерживать цифровые двойники всех размеров, и мы работаем с глобальными партнерами над созданием крупнейшего компьютера в истории человечества.
Кроме того, Nvidia выходит на космический рынок. Чипы Thor получили сертификат радиационной безопасности и работают на спутниках. Мы сотрудничаем с партнерами над разработкой Vera Rubin Space-1 для создания космических центров обработки данных. Теплоотвод является ключевой проблемой в космосе, где рассеивание тепла полностью зависит от излучения, и мы привлекаем лучших инженеров для решения этой задачи.
OpenClaw: Операционная система для эпохи интеллектуальных агентов
Питер Штайнбергер разработал программное обеспечение под названием OpenClaw. Это самый популярный проект с открытым исходным кодом в истории человечества, превзошедший достижения Linux за тридцать лет всего за несколько недель.
OpenClaw — это, по сути, агентная система, способная на:
Управление ресурсами, доступ к инструментам, файловым системам и большим языковым моделям.
Выполнение задач по планированию и с заданным временем.
Разбейте проблему на этапы и свяжитесь с субподрядчиками.
Поддерживает ввод и вывод в любом формате (голос, видео, текст, электронная почта и т. д.).
Используя синтаксис операционной системы, это действительно операционная система — операционная система для интеллектуальных компьютеров-агентов. Windows сделала возможным создание персональных компьютеров; OpenClaw делает возможным создание персональных интеллектуальных агентов.
Каждой компании необходимо разработать собственную стратегию OpenClaw, так же как нам всем нужны стратегии Linux, HTML и Kubernetes.
Полная перестройка корпоративных ИТ-систем.
До появления OpenClaw корпоративные ИТ-системы представляли собой данные и файлы, поступающие в системы, проходящие через инструменты и рабочие процессы и в конечном итоге превращающиеся в инструменты для использования людьми. Компании-разработчики программного обеспечения создавали эти инструменты, а системные интеграторы (GSI) и консалтинговые фирмы помогали предприятиям их использовать.
Корпоративные ИТ после OpenClaw: каждая SaaS-компания трансформируется в AaaS (агент как услуга) — предоставляя не просто инструменты, а агентов искусственного интеллекта, специализирующихся в конкретных областях.
Однако здесь возникает ключевая проблема: интеллектуальные агенты внутри предприятия могут получать доступ к конфиденциальным данным, выполнять код и взаимодействовать с внешними организациями. В корпоративной среде это должно строго контролироваться.
С этой целью мы объединили усилия с Питером для внедрения системы безопасности в корпоративную версию, в результате чего были достигнуты следующие результаты:
NeMo Claw (эталонный дизайн): эталонная платформа корпоративного уровня на основе OpenClaw, интегрирующая полный набор инструментов NVIDIA для интеллектуального искусственного интеллекта.
Open Shield (уровень безопасности): интегрирован в OpenClaw, предоставляет механизм политик, сетевые барьеры и маршрутизацию с обеспечением конфиденциальности для защиты корпоративных данных.
NeMo Cloud: загружаемое и используемое решение, совместимое со стратегическими механизмами всех SaaS-компаний.
Это возрождение корпоративных ИТ-индустрии, которая первоначально оценивалась в 2 триллиона долларов и вот-вот вырастет до многотриллионных масштабов, перейдя от предоставления инструментов к предоставлению специализированных услуг с использованием ИИ-агентов.
Я вполне могу предвидеть, что в будущем у каждого инженера в компании будет годовой бюджет в токенах. Их годовая зарплата может составлять сотни тысяч долларов, и я буду выделять им дополнительное количество токенов, эквивалентное половине их зарплаты, что увеличит их производительность в десять раз. Вопрос «Сколько токенов предоставляется при приеме на работу в компанию?» стал новой темой для обсуждения при найме сотрудников в Силиконовой долине.
В будущем каждая компания будет одновременно и пользователем токенов (для инженеров), и производителем токенов (для предоставления услуг своим клиентам). Значение OpenClaw невозможно переоценить; он так же важен, как HTML и Linux.
Инициатива NVIDIA по открытой модели
Что касается кастомных когтей, мы предлагаем передовую, разработанную компанией NVIDIA модель:
К областям моделирования относятся Nemotron (крупномасштабная языковая модель), Cosmos (модель основы мира), GROOT (универсальная модель человекоподобного робота), Alpamayo (автономное вождение), BioNeMo (цифровая биология) и Phys-AI (физика).
Мы находимся на переднем крае технологий во всех областях и стремимся к постоянному совершенствованию: за Nemotron 3 последовал Nemotron 4, за Cosmos 1 — Cosmos 2, и Groq также будет усовершенствован до второго поколения.
Nemotron 3 входит в тройку лучших моделей в мире в OpenClaw, занимая лидирующие позиции в этой области. Nemotron 3 Ultra станет самой мощной базовой моделью в истории, помогая странам создавать суверенный искусственный интеллект.
Сегодня мы объявляем о создании консорциума Nemotron, который инвестирует миллиарды долларов в развитие фундаментальных моделей искусственного интеллекта. В состав консорциума входят BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (Индия) и Thinking Machines (лаборатория Миры Мурати). К консорциуму присоединяются компании-разработчики корпоративного программного обеспечения, интегрируя эталонный дизайн NeMo Claw и инструментарий NVIDIA AI Agent Toolkit в свои продукты.
Физика, искусственный интеллект и робототехника
Цифровые интеллектуальные агенты действуют в цифровом мире — пишут код и анализируют данные; в то время как физический ИИ — это воплощенный интеллектуальный агент, то есть робот.
В этом году на GTC было представлено в общей сложности 110 роботов, представляющих практически все научно-исследовательские компании мира в области робототехники. Компания NVIDIA предоставила три компьютера (учебный компьютер, компьютер для моделирования и бортовой компьютер), а также полный набор программного обеспечения и моделей искусственного интеллекта.
В сфере автономного вождения настал «момент ChatGPT». Сегодня мы объявляем о присоединении к платформе NVIDIA RoboTaxi Ready четырех новых партнеров: BYD, Hyundai, Nissan и Geely, с общей годовой производственной мощностью в 18 миллионов автомобилей. Это еще больше укрепляет существующий состав Mercedes-Benz, Toyota и GM. Мы также объявляем о важном партнерстве с Uber для развертывания и интеграции автомобилей RoboTaxi Ready в нескольких городах.
В области промышленных роботов многие компании, такие как ABB, Universal Robots и KUKA, сотрудничают с нами, чтобы объединить физические модели искусственного интеллекта с системами моделирования, способствуя внедрению роботов на производственных линиях по всему миру.
В телекоммуникационном секторе к этой категории также относятся Caterpillar и T-Mobile. В будущем беспроводные базовые станции перестанут быть просто узлами связи, а станут интеллектуальными платформами для граничных вычислений, такими как NVIDIA Aerial AI RAN, способными в режиме реального времени отслеживать трафик, корректировать формирование луча и обеспечивать экономию энергии и повышение эффективности.
Специальный репортаж: Дебют робота Олафа
(Воспроизводится демонстрационный видеоролик робота Олафа из мультфильма Диснея)
Дженсен Хуанг: Снеговик прибыл! Ньютон работает безупречно! Омниверс тоже работает безупречно! Олаф, как дела?
Олаф: Я так рад тебя видеть.
Дженсен Хуанг: Да, потому что я дал тебе компьютер — Джетсонов!
Олаф: Что это?
Хуан Жэньсюнь: Оно прямо у тебя в животе.
Олаф: Это потрясающе.
Дженсен Хуанг: Ты научился ходить в Омниверсе.
Олаф: Мне нравится гулять. Это гораздо лучше, чем кататься на олене и любоваться прекрасным небом.
Дженсен Хуанг: Это происходит именно благодаря физическому моделированию, основанному на решателе Ньютона, работающем на NVIDIA Warp, который мы разработали в сотрудничестве с Disney и DeepMind, что позволяет адаптироваться к реальному физическому миру.
Олаф: Именно это я и собирался сказать.
Дженсен Хуанг: Вот где кроется ваш интеллект. Я снеговик, а не снежный ком.
Дженсен Хуанг: Можете себе представить? Диснейленд будущего — все эти роботы-персонажи свободно разгуливают по парку. Но, честно говоря, я думал, что вы будете выше. Я никогда не видел такого низкого снеговика.
Олаф: (Без комментариев)
Дженсен Хуанг: Не могли бы вы помочь мне закончить сегодняшнюю речь?
Олаф: Это потрясающе!
Краткое содержание основной речи
Дженсен Хуанг: Сегодня мы вместе обсудили следующие ключевые темы:
Наступил переломный момент: вывод результатов стал основной задачей ИИ, токены стали новым товаром, а производительность вывода напрямую определяет доход.
Эпоха фабрик ИИ: центры обработки данных эволюционировали из хранилищ файлов в фабрики по производству токенов. В будущем каждая компания будет оценивать свою конкурентоспособность по показателю «эффективность фабрики ИИ».
Революция интеллектуальных агентов OpenClaw: OpenClaw положил начало эре интеллектуальных вычислительных систем. Корпоративные ИТ-подразделения переходят от эры инструментов к эре интеллектуальных агентов, и каждому предприятию необходимо разработать стратегию использования OpenClaw.
Физический ИИ и робототехника: воплощенный интеллект внедряется в больших масштабах, и автономное вождение, промышленные роботы и человекоподобные роботы вместе представляют собой следующую важную возможность для применения физического ИИ.
Всем спасибо, желаю отлично провести время на GTC! #黄仁勋 #GTC #AI $BTC $ETH