
Я уже какое-то время сижу с этой концепцией дизайна эмитента, и не могу выбросить из головы одну идею: “одинаковые учетные данные, разные эмитенты.” Это звучит чисто на бумаге… но что-то кажется неправильным.
Смотри, системы, такие как SIGN, относятся к учетным данным как к структурированной правде. Эмитент определяет схему, подписывает её, и вуаля, любой с правильными ключами может её проверить. Просто. Чисто. Машинно-читаемо.
Так что, теоретически, если два учетных данных следуют одному и тому же формату, они должны означать одно и то же.
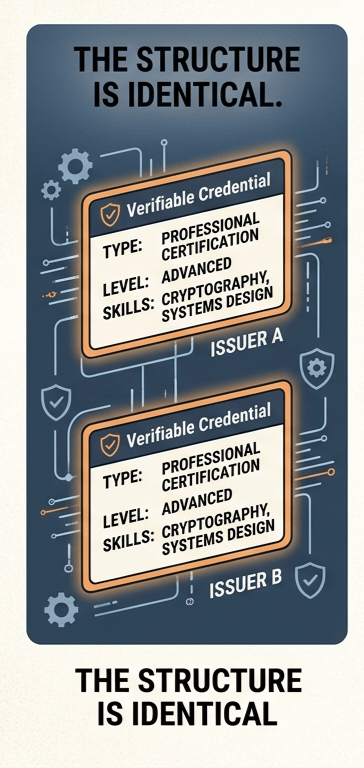
Это предположение.
Но, честно говоря? Это работает только если каждый эмитент думает одинаково. А они не думают. Даже близко.
Возьмите что-то базовое — «профессиональная сертификация». Звучит просто, правда?
Теперь представьте это: один эмитент заставляет вас проходить формальные экзамены, накапливать контролируемые часы, обновлять это каждые несколько лет. Реальные усилия.
Другой эмитент? Они выдают это после короткого курса или какой-то внутренней проверки.
Вот дикая часть: оба учетных данных могут выглядеть идентично. Одни и те же поля. Одна и та же структура. Одна и та же криптографическая действительность. Все проверяется.
Но они не означают одно и то же. Даже близко.
А система? Она этого не поймает. Не может.
С точки зрения проверки оба действительны. Подписаны. Действительны. Готово.
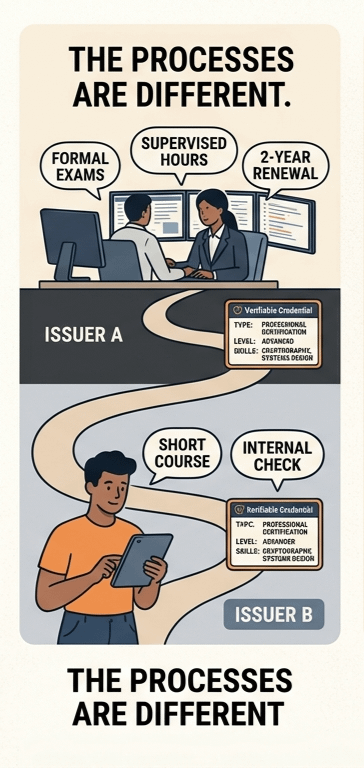
Разница не в криптографии. Она заключается в решениях, которые эмитент принял до того, как учетные данные даже появились.
Вот где начинаются проблемы.
Теперь проверяющему нужно думать глубже. Это уже не просто «это действительно?» Это «хорошо... но что это на самом деле значит от этого эмитента?»
И это совершенно другая проблема.
Люди не говорят об этом достаточно.
Потому что, как только вы доходите до этого, вы, по сути, добавили второй уровень интерпретации поверх проверки. И этот уровень? Он субъективен.
Теперь продвиньте это через границы. Разные системы. Разные отрасли.
Работодатель, государственное учреждение, какая-то платформа — все они смотрят на учетные данные, которые выглядят взаимозаменяемыми… но не являются таковыми.
Что происходит?
Либо вы создаете общие стандарты среди эмитентов (удачи с этим), либо создаете какую-то репутационную прослойку. Или, и это то, что обычно происходит, вы сбрасываете проблему на проверяющего.
«В масштабах», говорят они.
Да… это не маленькая проблема.
Потому что теперь согласованность больше не исходит от системы. Она исходит от координации. А координация запутанная, политическая, медленная, как угодно.

Вот часть, которая запоминается:
SIGN (или любая аналогичная система) может сделать учетные данные переносимыми. Проверяемыми. Легкими для передачи.
Но переносимость не то же самое, что эквивалентность. Даже близко.
Это просто значит, что вы можете что-то проверить. Это не значит, что это несет одинаковый вес повсюду.
И вот где это становится интересным... и немного неудобным.
Что происходит в долгосрочной перспективе?
Могут ли системы идентификации оставаться последовательными, когда разные эмитенты определяют «одни и те же» учетные данные совершенно разными способами?
Или мы окажемся в мире, где все проверяется идеально...
но значение медленно уходит в сторону со временем?
Я не думаю, что мы на это ответили.
