
Все продолжают помещать OpenLedger в одну категорию:
“еще одна цепочка ИИ.”
Я думаю, что это упускает то, что на самом деле может иметь значение.
Крипта любит простые нарративы. ИИ + блокчейн + вычисления — это легко понять. GPU дефицитны, затраты на вывод данных высоки, и инвесторы естественно тянутся к историям об инфраструктуре, потому что они кажутся конкретными.
Но более глубокая проблема в ИИ может быть не в вычислениях.
Это может быть атрибуция.
Не социальные сети, а экономическая атрибуция.
Кто предоставил данные?
Кто повлиял на результат?
Кто должен получать компенсацию, когда AI генерирует ценность?
И как отслеживать всё это, когда AI станет частью реальных отраслей?
Это та часть, которую большинство людей всё ещё недооценивает.
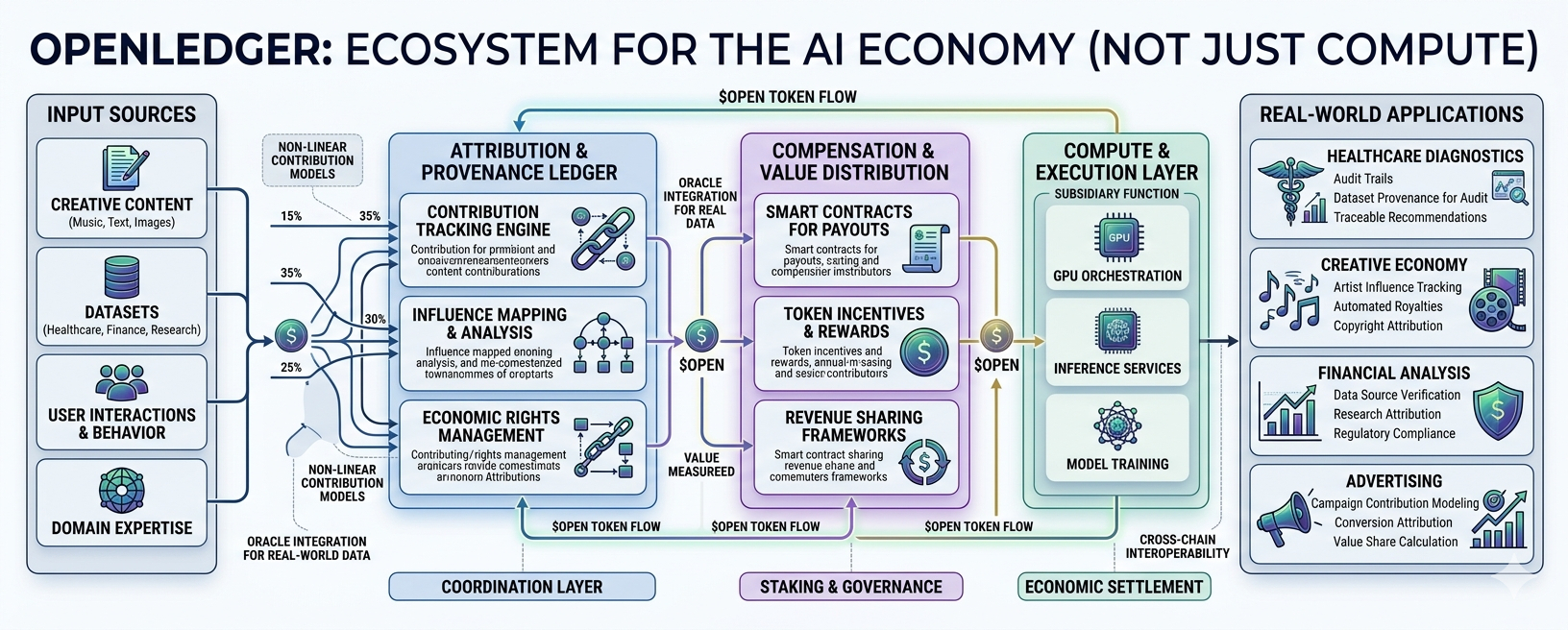
Когда я смотрю на OpenLedger, я не вижу «AI chain» в традиционном смысле. Я вижу проект, который пытается построить нечто более похожее на бухгалтерский слой для AI-экономик.
И честно говоря, это может оказаться более важным, чем сами вычисления.
Потому что вот неудобная правда, о которой никто не любит говорить:
AI сегодня невероятно хорош в поглощении ценности, но по-прежнему ужасен в её распределении.
Модели обучаются на океанах человеческих знаний, креативной работы, поведенческих данных, исследований и экспертных знаний. Затем всё это сжимается в результаты, которые выглядят магически на поверхности — в то время как люди под стеком становятся всё более невидимыми.
Вычисления помогают моделям работать быстрее.
Это не решает вопрос о том, кто заслуживает признания.
Это становится настоящей проблемой, как только AI начинает затрагивать отрасли, где подотчетность имеет значение.
Возьмём здравоохранение.
Люди представляют себе AI-врачей и автоматизированную диагностику как проблему вычислений. Быстрее модели, больше модели, лучше модели.
Но больницы заботятся не только о скорости. Им важна отслеживаемость. Им важно, откуда пришли рекомендации, какие наборы данных на них повлияли и можно ли позже провести аудит решений.
В какой-то момент разговор перестаёт быть техническим и становится экономическим и юридическим.
Происхождение имеет значение.
Реклама сталкивается с той же проблемой в другой форме.
Вся цифровая рекламная индустрия уже вращается вокруг войн атрибуции. Всем интересно, что вызвало конверсию, кто повлиял на клиента, кто заслуживает плату.
Теперь представьте себе системы AI, генерирующие кампании, оптимизирующие таргетинг, пишущие тексты, адаптирующие креативы и обучающиеся на миллионах взаимодействий в реальном времени.
Внезапно вопрос становится запутанным:
Чьи данные создали ценность?
Чья креативность сформировала результат?
Кто получает деньги?
Без атрибуции AI в основном концентрирует ценность в компаниях, контролирующих модели.
С атрибуцией AI начинает выглядеть больше как экономика.
Финансы похожи.
AI-исследователь не создает интеллект из ниоткуда. Он черпает из документов, отчетов аналитиков, исторических паттернов, рыночного поведения и собственных данных. Институтам в конечном итоге нужно знать, откуда пришли идеи — не потому что это звучит идеалистично, а потому что регуляторы и рисковые группы требуют подотчетности.
И честно говоря, музыка может быть самым ясным примером из всех.
Интернет уже один раз сломал креативную атрибуцию. Стриминг частично восстановил её. AI снова собирается нагрузить систему.
Когда модели генерируют песни, вдохновленные тысячами или миллионами существующих произведений, аргумент больше не звучит как «может ли AI создавать музыку?»
Это становится:
«Как мы думаем о влиянии, владении и компенсации в мире, где креативность становится вероятностной?»
Совершенно точного ответа может и не быть.
Это важная часть.
Я думаю, что многие люди слышат «атрибуция» и представляют себе какую-то чистую математическую систему, где каждый вклад измеряется идеально, и все получают справедливую плату.
Реальность, вероятно, не будет выглядеть так.
Человеческая креативность неопрятна. Влияние данных неопрятно. Модели нелинейны. Вклады постоянно пересекаются. Совершенная атрибуция может быть невозможна.
Но несовершенная атрибуция всё равно может иметь огромное значение.
Потому что сейчас стандартная система фактически не предусматривает никакой атрибуции.
И это обычно означает, что ценность течёт вверх к тем, кто владеет моделями.
Вот почему OpenLedger кажется мне интересным.
Проект, похоже, делает ставку на то, что AI в конечном итоге нуждается в инфраструктуре для отслеживания вклада, происхождения и экономического участия — не только в инфраструктуре для вычислений.
Это также меняет то, как я думаю о $OPEN.
Большинство токенов AI рассматриваются через призму полезности:
платить за вывод, обеспечивать сеть, получать доступ к вычислениям и т. д.
Но если тезис OpenLedger сработает, $OPEN станет чем-то другим. Меньше вычислительный токен, больше координационный слой, связанный с атрибуцией, компенсацией и владением внутри AI-рабочих процессов.
Это гораздо более масштабная идея.
Но это также гораздо рискованней.
Потому что рынку может быть всё равно.
Это та часть, которую иногда игнорируют крипто-люди.
Только потому что проблема важна, не означает, что принятие происходит быстро. Большинство компаний оптимизируют для эффективности, прежде чем для справедливости. Если системы AI с черным ящиком остаются дешевле и «достаточно хорошими», системам атрибуции может потребоваться годы, чтобы стать коммерчески значимыми.
Есть также вероятность, что инфраструктура станет полезной, в то время как токен не захватит долговременную ценность.
Этот риск реальный.
И честно говоря, скептицизм здесь полезен.
Атрибуция сложна.
Стандарты неясны.
Принятие в корпоративном секторе может двигаться медленно.
Регулирование может сформировать пространство раньше, чем крипто-нативные системы.
И совершенная прозрачность в AI, возможно, просто никогда не будет существовать.
Тем не менее, я всё время возвращаюсь к одной и той же мысли:
Первая фаза AI заключалась в создании интеллекта.
Следующая фаза может заключаться в учете этого.
Не только кто владеет моделями — но и кто вносил вклад в них, кто повлиял на них и кто получает деньги, когда они генерируют экономическую ценность.
Вот почему OpenLedger кажется более интересным, чем типичная ярлыка «AI chain» предполагает.
Он не только пытается масштабировать интеллект.
Он пытается построить реестр вокруг того, откуда берется интеллект.